[2025/12/17 05:37:19.018 +00:00] [ERROR] [commit.go:200] [“2PC failed commit key after primary key committed”] [error=“Error(Txn(Error(Mvcc(Error(TxnLockNotFound { start_ts: TimeStamp(462933153015136331), commit_ts: TimeStamp(462933153906426548), key: [116, 128, 0, 0, 0, 0, 0, 0, 208, 95, 114, 128, 21, 84, 27, 34, 220, 94, 231] })))))”] [txnStartTS=462933153015136331] [commitTS=462933153906426548] [keys=“[7480000000000000d05f728015541b22dc5ee7]”]
现象就是写入的数据没查到。至于这个事务有没有写成功,不确定,程序没抓到报错。
我理解primary key 提交了就代表事务提交了。
有没有什么参数可以调整,让两阶段都提交后再返回成功。
或者说我这是遇到了已知bug吗?
我看 client-go 里面有相关的 issue :
https://github.com/tikv/client-go/issues/1631
是想加更多的信息,那么意味着你们遇到过?怎么解决?怎么避免?
另外补充一下:这个报错如果返回给了客户端,客户端常用的访问 mysql 的那一套靠 durid 的封装没有抓到这个报错(也可能是我们程序写的挫),这会给客户端造成数据已成功写入的假象,建议这个错误至少能做个兼容处理,让客户端能感知到这个错误。
还有另一个错误客户端捕获不到:当事务超大,返回 out of memory 的时候,链接也没断开,我们一个程序会认为结果还没返回,就一直傻等着。这个问题不确定是程序导致的还是 tidb 自创的这些报错 jdbc 驱动无法拿到。
我理解primary key 提交了就代表事务提交了,这个没错。我也想知道如果远程节点在写入成功之前宕机的话,lock cf和write cf是在什么时候补偿的?
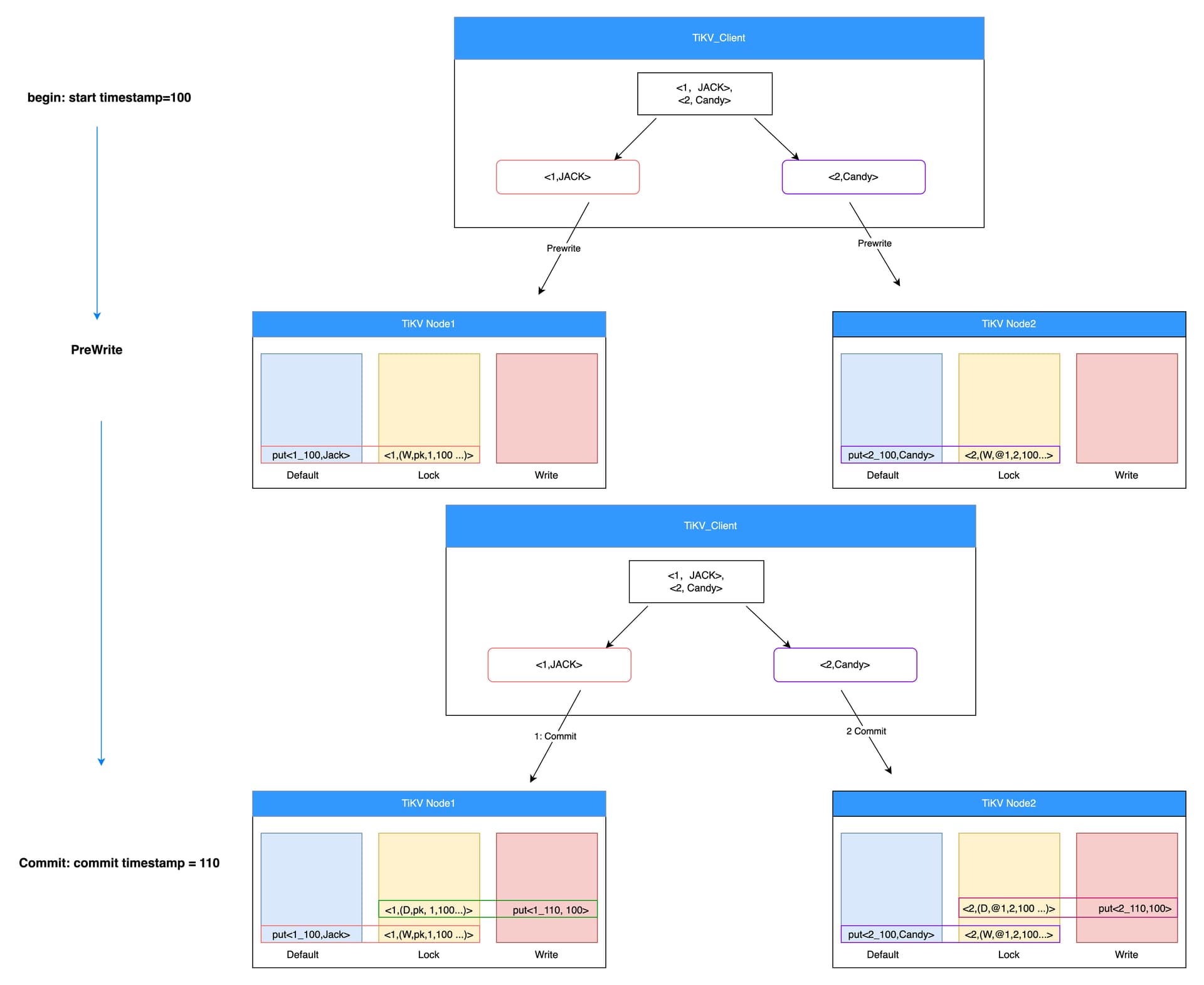
这里是把 <1,Jack>,<2,Candy> 两个属于不同region、不同tikv的key按事务写入tikv。
- 首先是prewrite,在default cf 和 lock cf 写入数据,把要写入的变更按region分成2个grpc,分别发送给2个tikv。
- 两个tikv 分别在default cf中写入数据,lock cf 中写入锁。其中 tikv1 中的是主锁,tikv2的是从锁
- 提交时,tikv_client 首先给主锁所在的region发送grpc,在write cf中写入commit记录put<1_100,100>,删除lock cf 中的锁<1,(D,pk,1,100…)>,这两个cf的数据利用rocksdb支持的多cf的原子写入保证同时成功或失败。
- 主锁提交成功后才给tikv2发送grpc,tikv2 在write cf中写入commit记录 put<2_110,100>,删除lock cf中的锁<2,(D,@1, 2,100…)>。 同样也是原子写入。
这里第四步,tikv2 的 grpc 是肯定能成功的,如果这时候 tikv2 的 region 不可访问了,等 3 副本选出新的 leader 以后再写 write cf 和 lock cf,如果3副本中2副本坏了,那后续恢复后,其他事务看到2 candy 上有没提交的事务,去检查主锁 1 jack已经提交了,就直接把 2 candy 提交了。也就意味着不可能出现提交失败的情况。都持久化了。
这里应该是碰到了 bug