db_user
(Db User)
1
【TiDB 使用环境】生产环境 /测试/ Poc 生产
【TiDB 版本】7.5.4
【操作系统】centos 7.9
【部署方式】云上部署(什么云)/机器部署(什么机器配置、什么硬盘)机器部署 SSD
【集群数据量】16.5T
【集群节点数】7个 TiKV
【问题复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
–ratelimit 为30
BR 备份失败,报错[ERROR] [main.go:60] [“br failed”] [error="EntityTooLarge: 参数“Content-Length=105048538”无效,有效值为:[0,100MB]\n\tstatus code: 400, request id: , host id: "]
将–ratelimit调整为10后依旧有该报错,目前100M是集团共享存储的影响,有没有什么办法让备份文件大小小于100M
db_user
(Db User)
4
竟然是tikv的参数,我说在br上没有找到呢,我试下
AN_12
(Xiaoqiao)
5
BR 备份的文件本质是 TiKV 生成的 SST 数据文件,这些文件会被直接上传到 S3。因此,限制 SST 文件的大小即可控制上传到 S3 的单个文件大小。可通过调整 TiKV 的 RocksDB 相关参数,强制减小单个 SST 文件的最大尺寸。
2 个赞
db_user
(Db User)
6
还是不行,没改的时候报错事105M,改成96M报错是110M,改成80M的时候报错是130M了
[2025/11/05 06:28:57.210 +08:00] [INFO] [client.go:943] ["backup range completed"] [range-sn=532] [startKey=7480000000000003335F69800000000000000300] [endKey=7480000000000003335F698000000000000003FB] [take=51.901227ms]
[2025/11/05 06:28:57.212 +08:00] [INFO] [client.go:893] ["Backup Ranges Completed"] [take=7h28m50.042201967s]
[2025/11/05 06:28:57.212 +08:00] [INFO] [metafile.go:634] ["write metas finished"] [type=datafile]
[2025/11/05 06:28:58.900 +08:00] [INFO] [backup.go:675] ["wait for flush checkpoint..."]
[2025/11/05 06:28:58.900 +08:00] [INFO] [checkpoint.go:454] ["stop checkpoint runner"]
[2025/11/05 06:28:58.965 +08:00] [INFO] [checkpoint.go:341] ["stop checkpoint flush worker"]
[2025/11/05 06:28:58.973 +08:00] [INFO] [backup.go:498] ["skip removing gc-safepoint keeper for next retry"] [gc-id=br-29f90b72-1f7b-494b-9824-87ec4fc99af7]
[2025/11/05 06:28:58.974 +08:00] [INFO] [pd_service_discovery.go:248] ["[pd] exit member loop due to context canceled"]
[2025/11/05 06:28:58.974 +08:00] [INFO] [resource_manager_client.go:271] ["[resource manager] exit resource token dispatcher"]
[2025/11/05 06:28:58.974 +08:00] [INFO] [tso_dispatcher.go:240] ["exit tso dispatcher loop"]
[2025/11/05 06:28:58.974 +08:00] [INFO] [tso_dispatcher.go:410] ["[tso] stop fetching the pending tso requests due to context canceled"] [dc-location=global]
[2025/11/05 06:28:58.974 +08:00] [INFO] [tso_dispatcher.go:344] ["[tso] exit tso dispatcher"] [dc-location=global]
[2025/11/05 06:28:58.974 +08:00] [INFO] [tso_dispatcher.go:186] ["exit tso requests cancel loop"]
[2025/11/05 06:28:58.974 +08:00] [INFO] [tso_client.go:134] ["closing tso client"]
[2025/11/05 06:28:58.974 +08:00] [INFO] [tso_client.go:139] ["close tso client"]
[2025/11/05 06:28:58.974 +08:00] [INFO] [tso_client.go:150] ["tso client is closed"]
[2025/11/05 06:28:58.974 +08:00] [INFO] [pd_service_discovery.go:294] ["[pd] close pd service discovery client"]
[2025/11/05 06:28:58.975 +08:00] [INFO] [pd.go:231] ["closed pd http client"]
[2025/11/05 06:28:58.976 +08:00] [INFO] [tso_dispatcher.go:186] ["exit tso requests cancel loop"]
[2025/11/05 06:28:58.976 +08:00] [INFO] [tso_dispatcher.go:240] ["exit tso dispatcher loop"]
[2025/11/05 06:28:58.976 +08:00] [INFO] [resource_manager_client.go:271] ["[resource manager] exit resource token dispatcher"]
[2025/11/05 06:28:58.976 +08:00] [INFO] [pd_service_discovery.go:248] ["[pd] exit member loop due to context canceled"]
[2025/11/05 06:28:58.976 +08:00] [INFO] [tso_dispatcher.go:410] ["[tso] stop fetching the pending tso requests due to context canceled"] [dc-location=global]
[2025/11/05 06:28:58.976 +08:00] [INFO] [tso_dispatcher.go:344] ["[tso] exit tso dispatcher"] [dc-location=global]
[2025/11/05 06:28:58.976 +08:00] [INFO] [tso_client.go:134] ["closing tso client"]
[2025/11/05 06:28:58.976 +08:00] [INFO] [tso_client.go:139] ["close tso client"]
[2025/11/05 06:28:58.976 +08:00] [INFO] [tso_client.go:150] ["tso client is closed"]
[2025/11/05 06:28:58.976 +08:00] [INFO] [pd_service_discovery.go:294] ["[pd] close pd service discovery client"]
[2025/11/05 06:28:58.977 +08:00] [INFO] [collector.go:224] ["units canceled"] [cancel-unit=0]
[2025/11/05 06:28:58.977 +08:00] [INFO] [collector.go:78] ["Full Backup failed summary"] [total-ranges=0] [ranges-succeed=0] [ranges-failed=0] [backup-total-ranges=533]
[2025/11/05 06:28:58.977 +08:00] [ERROR] [backup.go:54] ["failed to backup"] [error="EntityTooLarge: 参数“Content-Length=133570547”无效,有效值为:[0,100MB]\n\tstatus code: 400, request id: , host id: "] [errorVerbose="EntityTooLarge: 参数“Content-Length=133570547”无效,有效值为:[0,100MB]\n\tstatus code: 400, request id: , host id: \ngithub.com/pingcap/errors.AddStack\n\t/root/go/pkg/mod/github.com/pingcap/errors@v0.11.5-0.20240318064555-6bd07397691f/errors.go:178\ngithub.com/pingcap/errors.Trace\n\t/root/go/pkg/mod/github.com/pingcap/errors@v0.11.5-0.20240318064555-6bd07397691f/juju_adaptor.go:15\ngithub.com/pingcap/tidb/br/pkg/storage.(*S3Storage).WriteFile\n\t/workspace/source/tidb/br/pkg/storage/s3.go:561\ngithub.com/pingcap/tidb/br/pkg/metautil.(*MetaWriter).flushMetasV2\n\t/workspace/source/tidb/br/pkg/metautil/metafile.go:772\ngithub.com/pingcap/tidb/br/pkg/metautil.(*MetaWriter).FinishWriteMetas\n\t/workspace/source/tidb/br/pkg/metautil/metafile.go:664\ngithub.com/pingcap/tidb/br/pkg/task.RunBackup\n\t/workspace/source/tidb/br/pkg/task/backup.go:712\nmain.runBackupCommand\n\t/workspace/source/tidb/br/cmd/br/backup.go:53\nmain.newFullBackupCommand.func1\n\t/workspace/source/tidb/br/cmd/br/backup.go:143\ngithub.com/spf13/cobra.(*Command).execute\n\t/root/go/pkg/mod/github.com/spf13/cobra@v1.7.0/command.go:940\ngithub.com/spf13/cobra.(*Command).ExecuteC\n\t/root/go/pkg/mod/github.com/spf13/cobra@v1.7.0/command.go:1068\ngithub.com/spf13/cobra.(*Command).Execute\n\t/root/go/pkg/mod/github.com/spf13/cobra@v1.7.0/command.go:992\nmain.main\n\t/workspace/source/tidb/br/cmd/br/main.go:58\nruntime.main\n\t/usr/local/go/src/runtime/proc.go:267\nruntime.goexit\n\t/usr/local/go/src/runtime/asm_amd64.s:1650"] [stack="main.runBackupCommand\n\t/workspace/source/tidb/br/cmd/br/backup.go:54\nmain.newFullBackupCommand.func1\n\t/workspace/source/tidb/br/cmd/br/backup.go:143\ngithub.com/spf13/cobra.(*Command).execute\n\t/root/go/pkg/mod/github.com/spf13/cobra@v1.7.0/command.go:940\ngithub.com/spf13/cobra.(*Command).ExecuteC\n\t/root/go/pkg/mod/github.com/spf13/cobra@v1.7.0/command.go:1068\ngithub.com/spf13/cobra.(*Command).Execute\n\t/root/go/pkg/mod/github.com/spf13/cobra@v1.7.0/command.go:992\nmain.main\n\t/workspace/source/tidb/br/cmd/br/main.go:58\nruntime.main\n\t/usr/local/go/src/runtime/proc.go:267"]
db_user
(Db User)
8
2025-08-18 23:35 87588691 s3://backup-data/2025-08-18/backupmeta.datafile.000000001
2025-10-19 22:44 102792275 s3://backup-data/2025-10-19/backupmeta.datafile.000000001
2025-10-22 22:45 103305170 s3://backup-data/2025-10-22/backupmeta.datafile.000000001
2025-10-25 22:47 104377670 s3://backup-data/2025-10-25/backupmeta.datafile.000000001
我观测了所有文件,发现是meta文件大小的问题,meta文件在25号的时候已经达到了99.5M,所以下一次备份失败了
db_user
(Db User)
9
查看github发现metafilesize达到128M才会自动切分
db_user
(Db User)
10
如果更改MetaFileSize,自己编译会不会有其他风险,或者官方能提供个接口,参数之类的,我想既然有sst-max-size参数,就是为了控制文件大小限制的,那MetaFileSize应该也是个可传参的吧
db_user
(Db User)
11
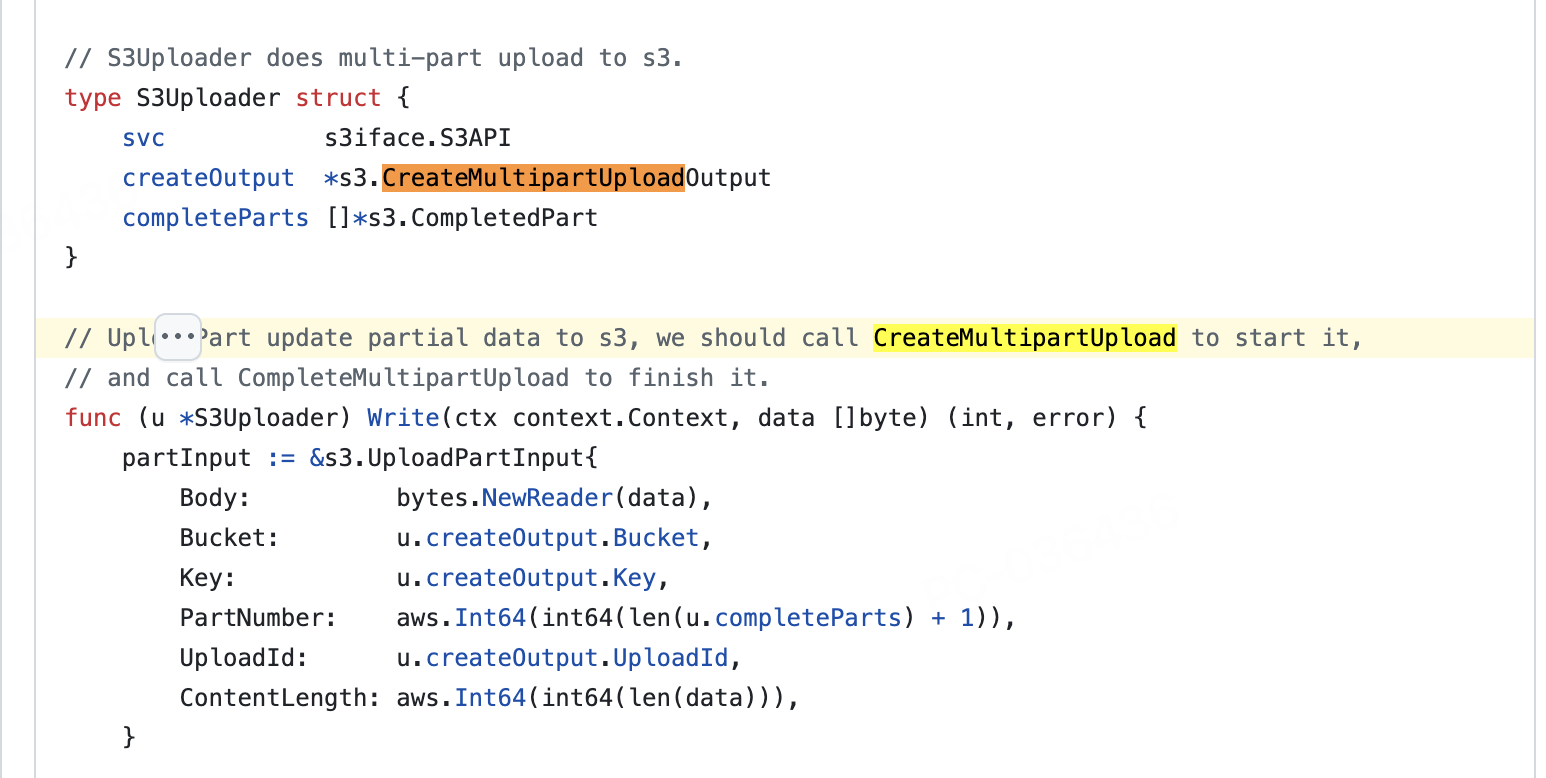
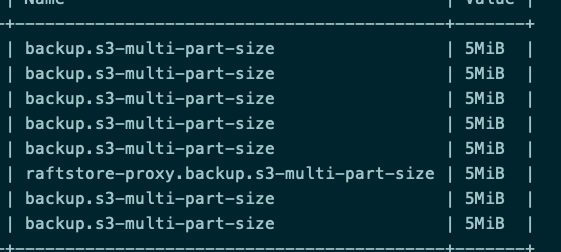
看代码里貌似支持5M的分块上传,大佬们帮忙看看为啥不行,是因为我备份设置了ratelimit了么,还是因为backup.s3-multi-part-size参数确实不起作用了
db_user
(Db User)
12
已经清楚,5M的限制是用在了并发分片上传,但是设置了ratelimit后就无法并发,单独的分片上传没有限制,所以才会出现参数不起作用的情况