感谢各位大佬,目前我采用了多个小文件(200M以内)进行批量并发导入,速度提上来了,测了一下之前单个一个G要花40多分钟,现在10分钟内就导完了 ![]()
1 个赞
数据量巨大的情况下调整region-concurrency不知是否有性能提升?
有提升但是不明显,我的是16核的,数值调成12,16,32速度变化不大,感觉核心应该还是单个sql文件大小超过256M之后,导入速度上不去
1 个赞
不过目前还有个问题,就是tidb-lightning导入的时候,有个pd挂了导致同步任务中断了(我配置了断点续传),重启pd之后,继续传的时候报错了让我用tidb-lightning-ctl工具检测,但是也没搜到这个工具,我用tiup install tidb-lightning-ctl 也没装上 jiu 比较尴尬了,原表数据也不能清理
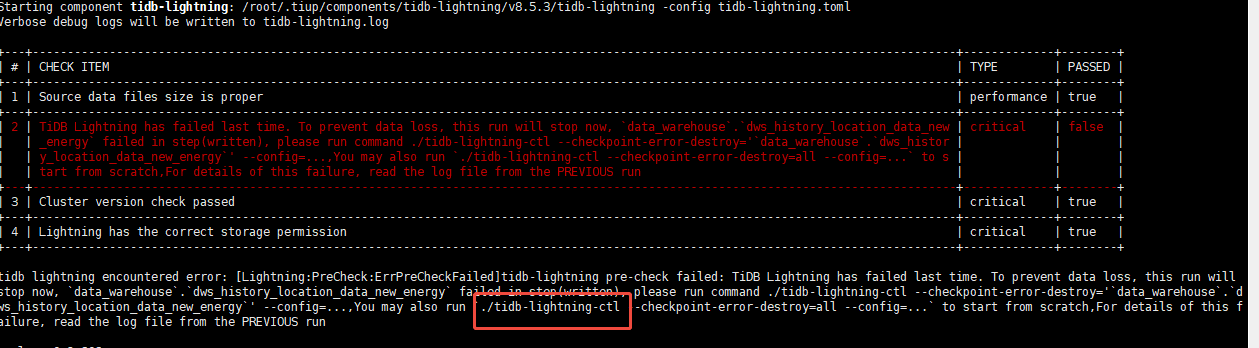
tidb-lightning-ctl 这个工具在toolkit包里
在慢查询里面能否看到慢的INSERT?如果能看到,那可以看下慢查询记录中的PLAN,如果不能看到到,那问题应该不在INSERT本身
默认的大小,优化文件大小吗
看看执行计划
跟文件大小也有关系吗 可以测试下
应该是文件数量过多了,不是文件大小的问题
导入的话,读文件也耗时。不是配置的问题,仅调整tidb-lightning 配置,要么使用物理导入,逻辑导入的话,对照官方文档调整导入并发即可
1 个赞
可以试试并行操作
单个文件并启动了并行?如果这样可能性能会受到影响,单个开启并行可能反而影响效率吧,类似单个cpu切换时间片的方式,失去了真正的多线程/多进程的优势~
有道理~
嗯,可能真跟这个有关系,单个文件快过大,导致内部扫描或检索太慢
目前导入速度基本稳定再15分钟左右了,写了两个tidb-lightning任务一起导,region-concurrency = 15;单个sql文件保持在200M左右,速度比较稳定
恭喜,还是有效果的哈~
优化一下…
看文件大小,优化一下