【TiDB 使用环境】生产环境
【TiDB 版本】7.5.3
【操作系统】CentOS Linux release 7.4.1708 (Core)
【部署方式】云上部署(腾讯云)
【集群数据量】10TB
【集群节点数】13Tikv
【问题复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
一、背景
最近在调整该集群的tikv节点配置, 历史节点低配数据量,目前一半节点配置升级,另外一半节点逐步下线。
刚开始一两个节点下线因为节点上数据少,下线时间还算可以。随着节点变少,单节点承载的数据量变多。节点下线时间越来慢。
看了官方文档 store limit 可以调整加速节点下线。 在之前的时候,所有store节点的 add-peer/remove-peer 都是45 ;通过监控能看到 replace-rule-offline-leader-peer 平均能到每分钟60个; replace-rule-offline-peer 平均能到95左右;
然后昨晚操作的时候,想着能加速下,就动态调整 store limit all 60 ,结果发现 operator的相关操作能力都急剧下降 (create \ check \ finish ) 具体如下图
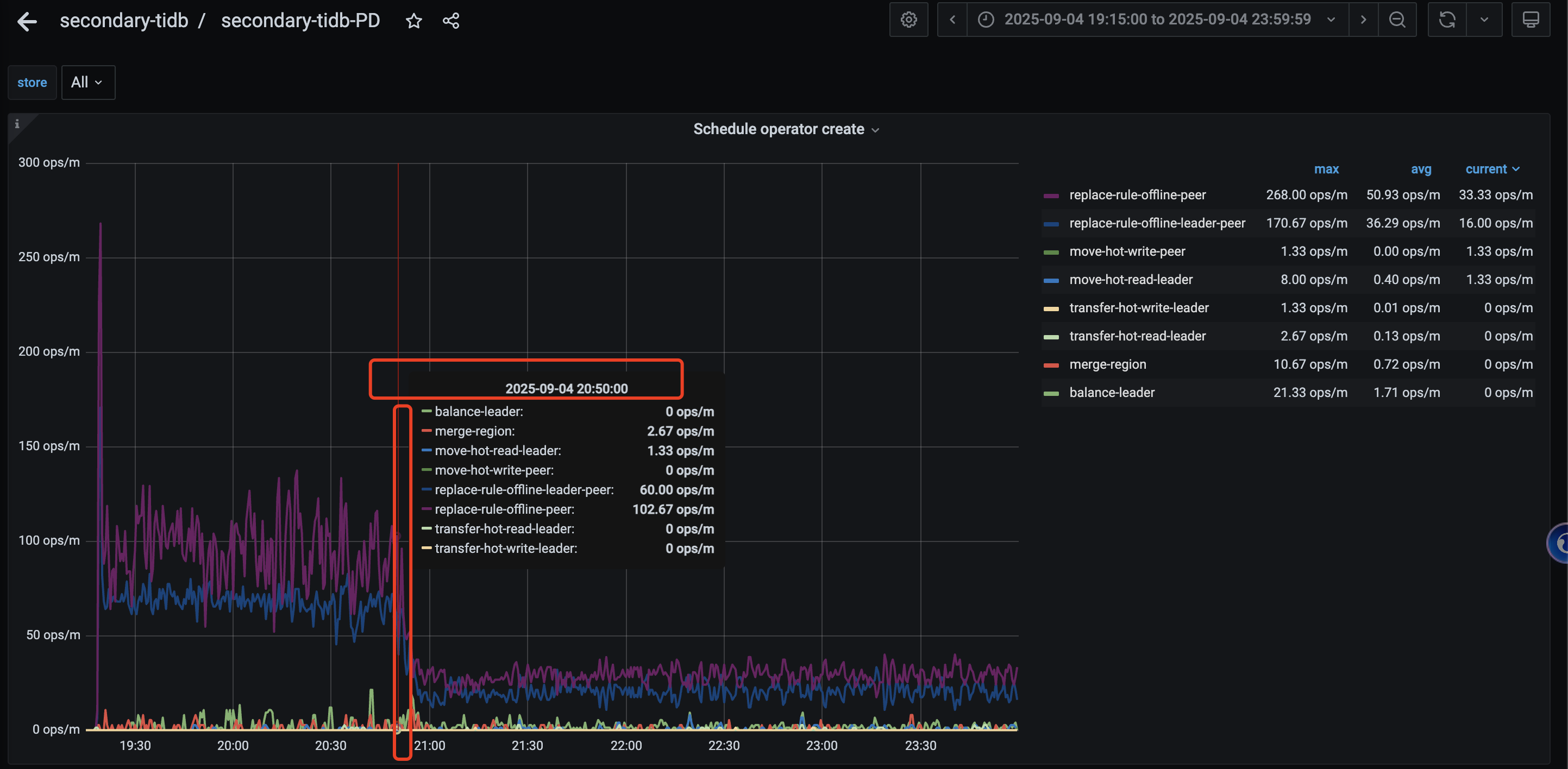
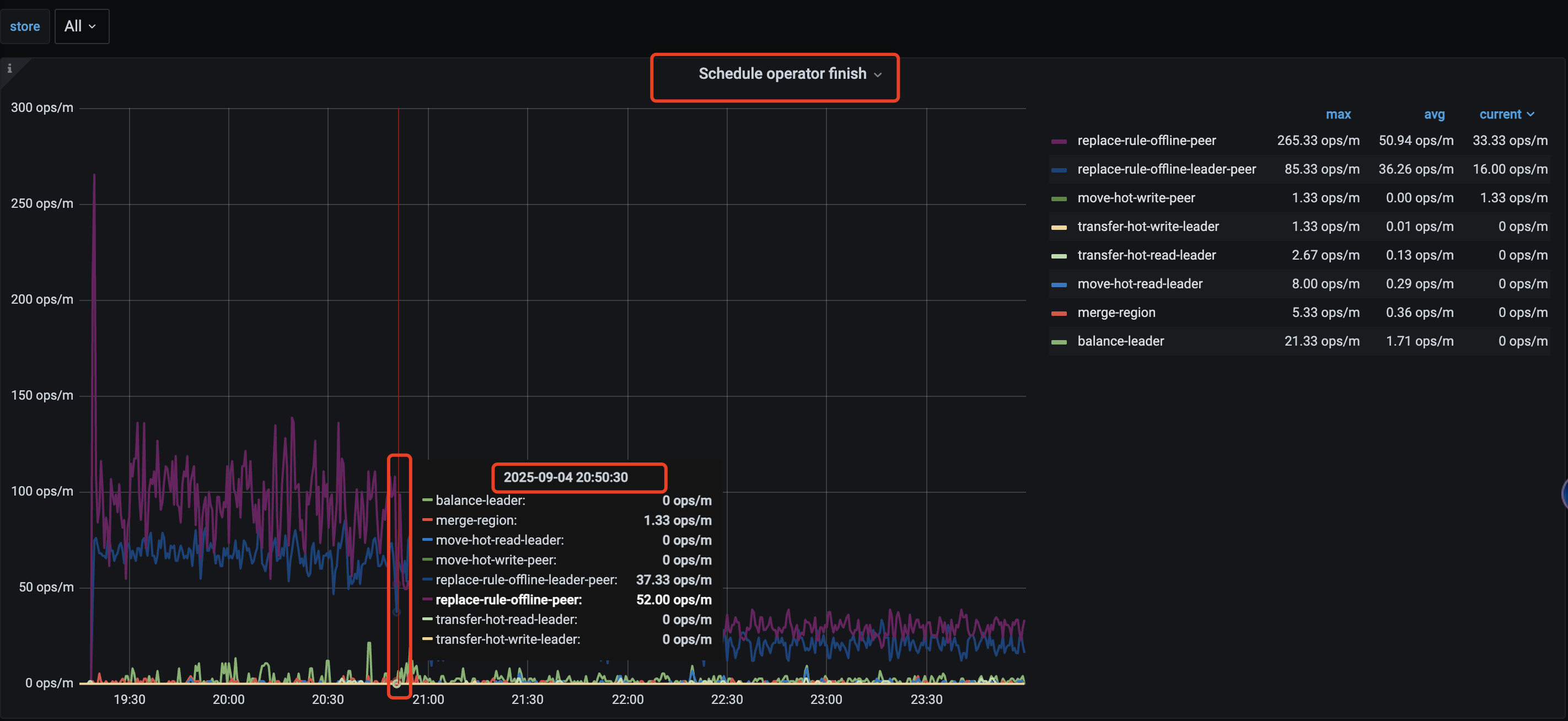
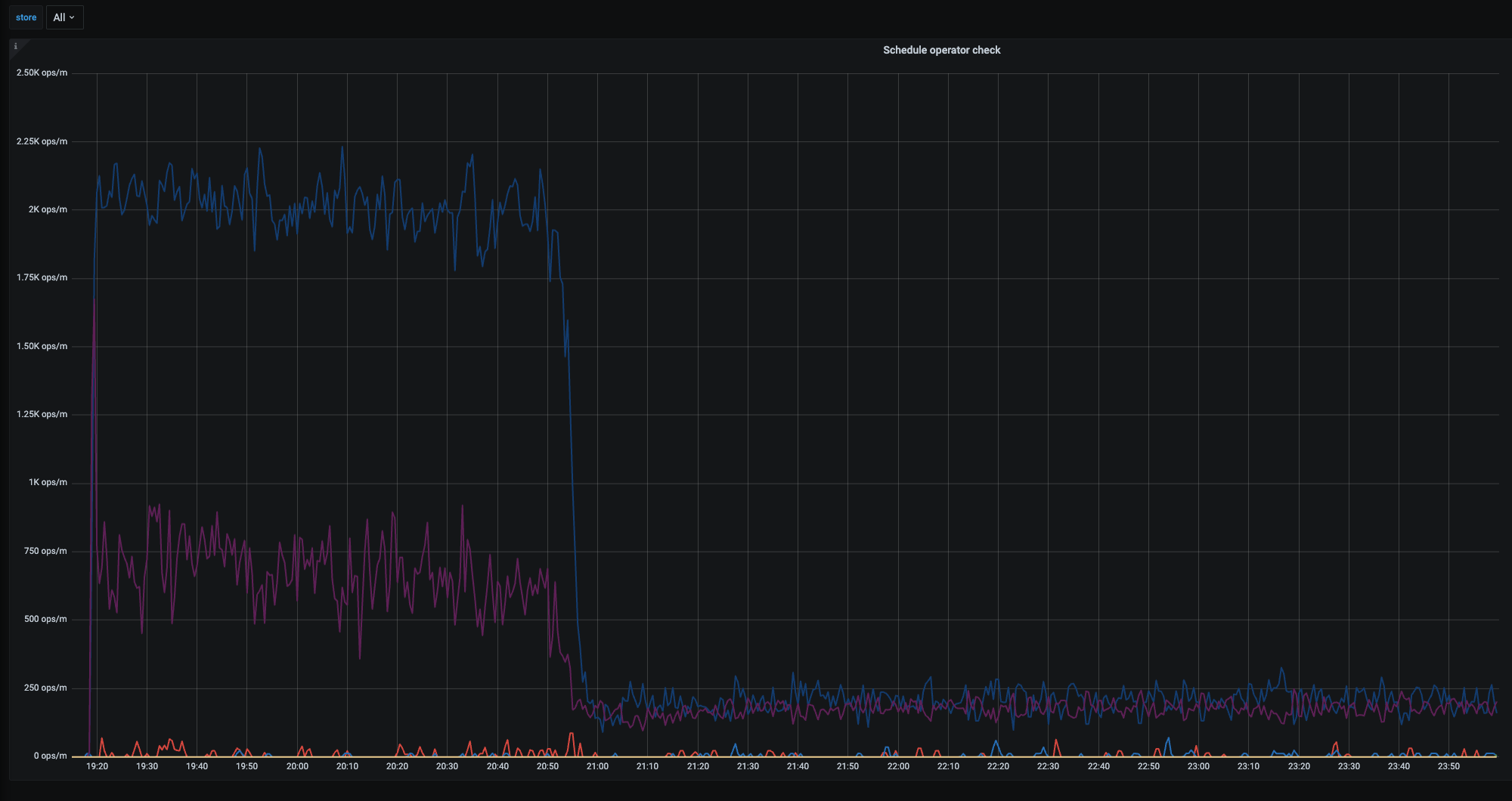
然后两分钟之后调整这个值恢复到 45 (store limit 45) 发现不起作用, 同步检查数据库中 配置发现是同步修改的 (show config where type=‘pd’ and name like ‘%store-limit%’ ; )
另外数据库中 schedule-limit 相关参数如下,过程中没有修改
+------+-------------------+------------------------------------+-------+
| Type | Instance | Name | Value |
+------+-------------------+------------------------------------+-------+
| pd | 172.31.7.144:2379 | schedule.hot-region-schedule-limit | 4 |
| pd | 172.31.7.144:2379 | schedule.leader-schedule-limit | 16 |
| pd | 172.31.7.144:2379 | schedule.merge-schedule-limit | 8 |
| pd | 172.31.7.144:2379 | schedule.region-schedule-limit | 2048 |
| pd | 172.31.7.144:2379 | schedule.replica-schedule-limit | 128 |
| pd | 172.31.7.144:2379 | schedule.witness-schedule-limit | 4 |
+------+-------------------+------------------------------------+-------+
6 rows in set (0.02 sec)
想了解 store limit 是在下线过程中不能动态调整还是什么原因导致了这个速度下降呢?
