【TiDB 使用环境】生产环境
【TiDB 版本】7.1.0
【操作系统】centos7
【部署方式】机器部署
【GC情况】
-
集群GC正常
-
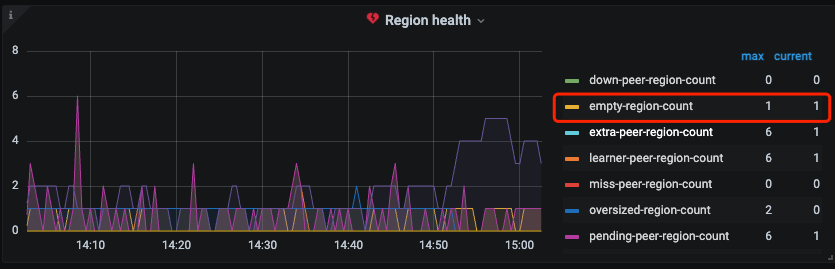
查看pd面板 empty-region=0
-
开启了跨表merge
-
region增速变快

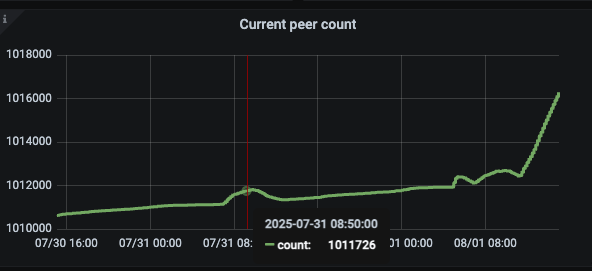
【问题】
1、计划清理20亿数据,释放磁盘空间,已清理1.2亿,发现集群region数量增加,符合预期么
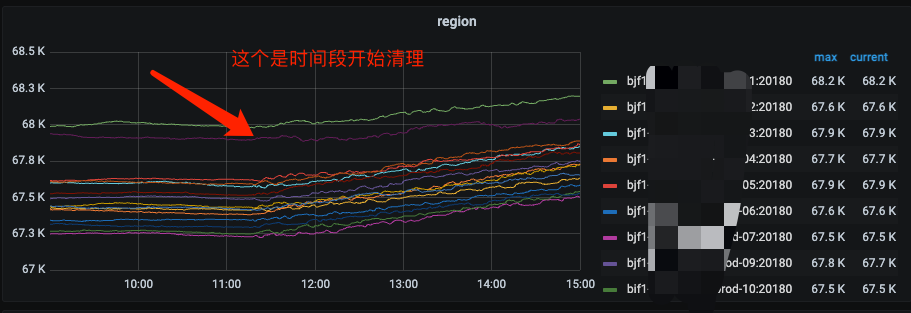
2、有什么办法能定位或加快合并么?
【TiDB 使用环境】生产环境
【TiDB 版本】7.1.0
【操作系统】centos7
【部署方式】机器部署
【GC情况】
集群GC正常
查看pd面板 empty-region=0
开启了跨表merge
region增速变快
【问题】
1、计划清理20亿数据,释放磁盘空间,已清理1.2亿,发现集群region数量增加,符合预期么
2、有什么办法能定位或加快合并么?
删除脚本逻辑是:根据主键ID递增删除,发现有比较多remove-hot,transfer-hot-write-leader的调度线程(时间能吻合上)。
会不会是主键递增删除,会使更多线程用在调度hot region,导致check、merge region慢?
gc没有清理呢吧
有可能,也好几个小时了,按理应该可以删一些。
下面是尝试resole-lock,是有事务卡住了?tso解析时间跟gc-life-time时间一致
`
[gc worker] finish resolve locks"] [uuid=651272028540017] [safePoint=459810137488752640] [try-resolve-locks-ts=459810137488752640] [regions=339672]
tso 459810137488752640
system: 2025-08-01 16:21:14.185 +0800 CST
logic: 0
`
[2025/08/01 17:11:14.178 +08:00] [INFO] [gc_worker.go:389] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=651272028540017]
[2025/08/01 17:12:14.178 +08:00] [INFO] [gc_worker.go:389] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=651272028540017]
[2025/08/01 17:12:16.479 +08:00] [INFO] [gc.go:182] ["clear outdated historical stats"]
[2025/08/01 17:12:22.729 +08:00] [INFO] [gc_worker.go:888] ["[gc worker] start delete ranges"] [uuid=651272028540017] [ranges=0]
[2025/08/01 17:12:22.729 +08:00] [INFO] [gc_worker.go:941] ["[gc worker] finish delete ranges"] [uuid=651272028540017] ["num of ranges"=0] ["cost time"=222ns]
[2025/08/01 17:12:22.730 +08:00] [INFO] [gc_worker.go:964] ["[gc worker] start redo-delete ranges"] [uuid=651272028540017] ["num of ranges"=0]
[2025/08/01 17:12:22.730 +08:00] [INFO] [gc_worker.go:993] ["[gc worker] finish redo-delete ranges"] [uuid=651272028540017] ["num of ranges"=0] ["cost time"=255ns]
[2025/08/01 17:12:22.733 +08:00] [INFO] [gc_worker.go:1845] ["[gc worker] sent safe point to PD"] [uuid=651272028540017] ["safe point"=459809964486819840]
[2025/08/01 17:17:16.378 +08:00] [INFO] [gc.go:182] ["clear outdated historical stats"]
[2025/08/01 17:21:14.229 +08:00] [INFO] [gc_worker.go:442] ["[gc worker] starts the whole job"] [uuid=651272028540017] [safePoint=459810137488752640] [concurrency=15]
[2025/08/01 17:21:14.241 +08:00] [INFO] [gc_worker.go:1250] ["[gc worker] start resolve locks"] [uuid=651272028540017] [safePoint=459810137488752640] [try-resolve-locks-ts=459810137488752640] [concurrency=15]
[2025/08/01 17:21:31.153 +08:00] [INFO] [gc_worker.go:1272] ["[gc worker] finish resolve locks"] [uuid=651272028540017] [safePoint=459810137488752640] [try-resolve-locks-ts=459810137488752640] [regions=339672]
[2025/08/01 17:22:14.187 +08:00] [INFO] [gc_worker.go:389] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=651272028540017]
[2025/08/01 17:22:16.484 +08:00] [INFO] [gc.go:182] ["clear outdated historical stats"]
[2025/08/01 17:23:11.172 +08:00] [INFO] [gc_worker.go:888] ["[gc worker] start delete ranges"] [uuid=651272028540017] [ranges=0]
[2025/08/01 17:23:11.172 +08:00] [INFO] [gc_worker.go:941] ["[gc worker] finish delete ranges"] [uuid=651272028540017] ["num of ranges"=0] ["cost time"=287ns]
[2025/08/01 17:23:11.173 +08:00] [INFO] [gc_worker.go:964] ["[gc worker] start redo-delete ranges"] [uuid=651272028540017] ["num of ranges"=0]
正常,使用 delete 删了要的 GC 和底层 rocksdb compaction 的
嗯呢,多谢,我再等等。
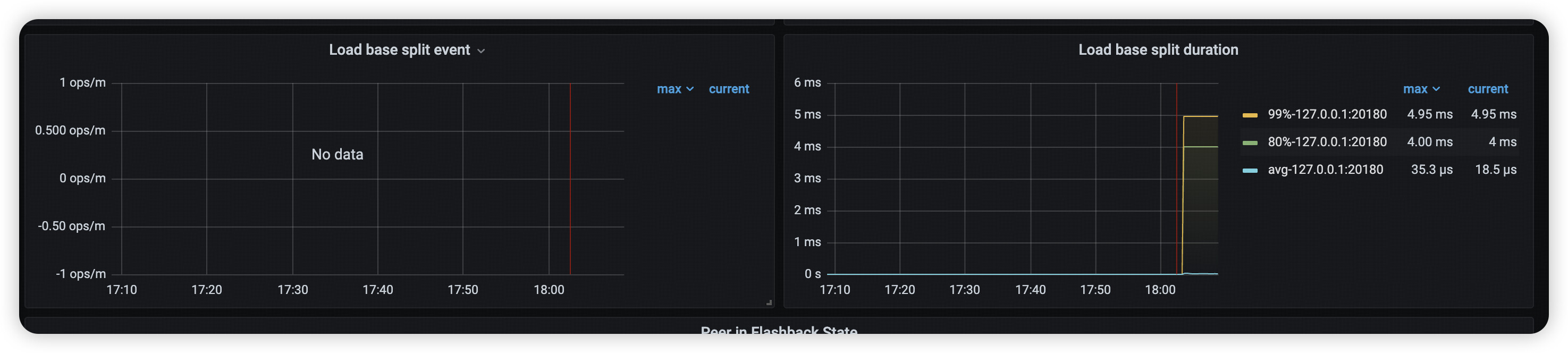
region 变多可能是因为 load base split 的特性 https://docs.pingcap.com/zh/tidb/stable/configure-load-base-split。因为删除数据会先把数据读到 tidb 上去,然后再删除,所以可能触发了 load base split 逻辑。可以通过 tikv 监控 tikv-detailes->raft admin 下面的监控来验证。
监控看到region数量,region健康度。正常情况下删除操作快于gc region合并,监控看起来就是先增多再减少
清理的表开启Tiflash了吗?
ALTER TABLE table_name COMPACT TIFLASH REPLICA;目前该语句仅支持对 TiFlash 进行数据整理,不支持对 TiKV 进行数据整理。
https://docs.pingcap.com/zh/tidb/stable/sql-statement-alter-table-compact/#alter-table--compact
收到,其它集群我按照这个搞。
集群没有tiflash。
正常的 delete删除tidb是向tikv存储插入一条标记为删除的记录,所以越删除硬盘空间占用越大,等过了gc时间再底层完成compact,估计得2天左右空间才会降下来
是的,看磁盘持续没释放,就改了gc参数。现在释放了
get!!
我是通过关闭gc.compactioin 的,不太清楚打开有啥问题,snapshort正常推进,数据不gc。
符合预期。不要着急,晚点再看看,有惊喜! ![]()
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。