有猫万事足
22
289ms 是比较高的了。
我先整理一下思路吧。首先一开始的问题从日志上看就是每个节点之间的互联互通有问题,那么我想到如果每个节点之间的互通有问题,获取tso肯定会慢,就值得看看tso wait指标是否正常。tso wait这里现在看是个有优化空间的地方,不过很难说和原始内存升高的问题有多大的相关性。
默认的slow sql的阈值是300ms。tso wait需要289ms的意思就是,几乎所有的sql在默认设置下都会变成慢查询。很显然留给其他环节的时间必须小于11ms才会不进慢查询,这是很难做到的。
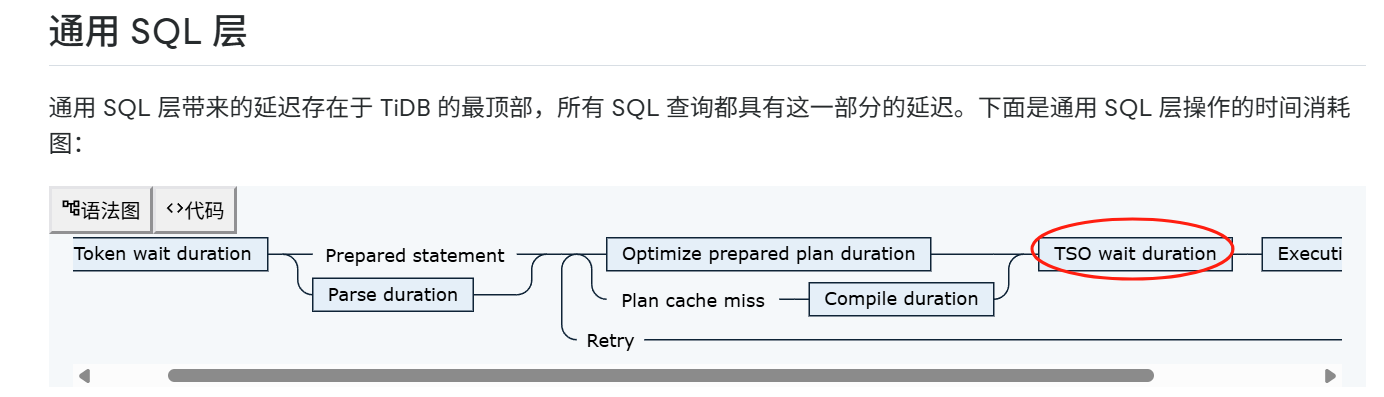
https://docs.pingcap.com/zh/tidb/stable/latency-breakdown/#通用-sql-层
在整个通用sql的阶段如上图所示。tso wait正常值应该也就20ms左右(对应着每个节点到pd leader的ping值小于1ms)。你现在这个值是偏高的。应该说大概率有个别节点到pd leader的ping值是大于10ms的。
以我的经验来说,tso wait一高,所有sql都慢。
建议检查一下其他节点到pd的ping值。另外部署的节点,最好不要跨子网,你上面的3个能看到ip的节点,分别是44.132,45.83,40.106。已经是3个pd/tidb节点跨了3个子网了。
grafana里面有个图可以看到ping值。黄框这个地方设置为你当前的pd leader。
wind
(Ti D Ber B Bgs Ljoo)
23
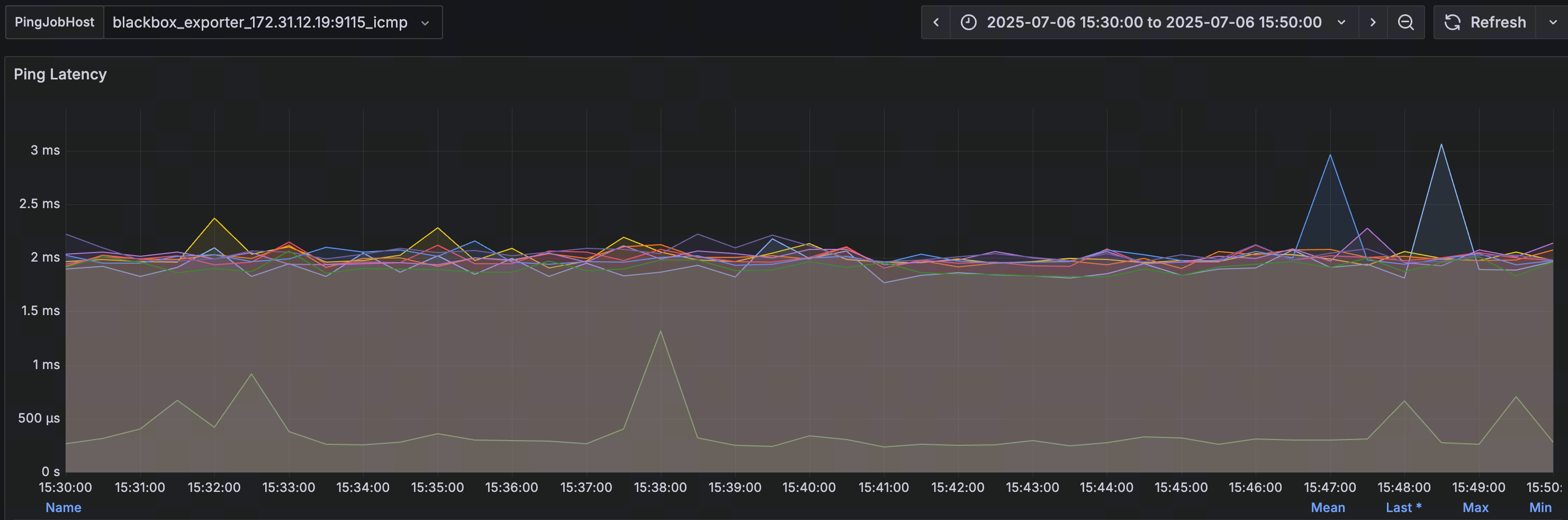
这边IP都是在B类172的私网网段的,不算跨网络吧?ping值是有点高,平均在2ms左右
故障时候Tso很高,但一般也都在20ms下。
看前面那个pd日志,出现故障时是15:38 这边tso开始升高的地方是15:41,从这点看tso变高不是因反而是果吧?
1 个赞
有猫万事足
24
ping值2ms左右,确实可以接受。
后面的结论我也同意是果不是因。是当时不能互通的一种佐证。我已经没什么思路了。这个oom的原因让人困惑。
有猫万事足
25
wind
(Ti D Ber B Bgs Ljoo)
26
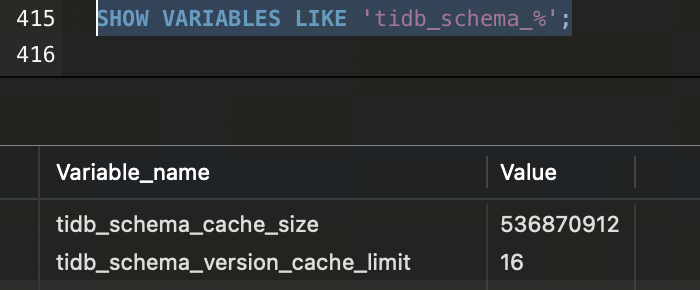
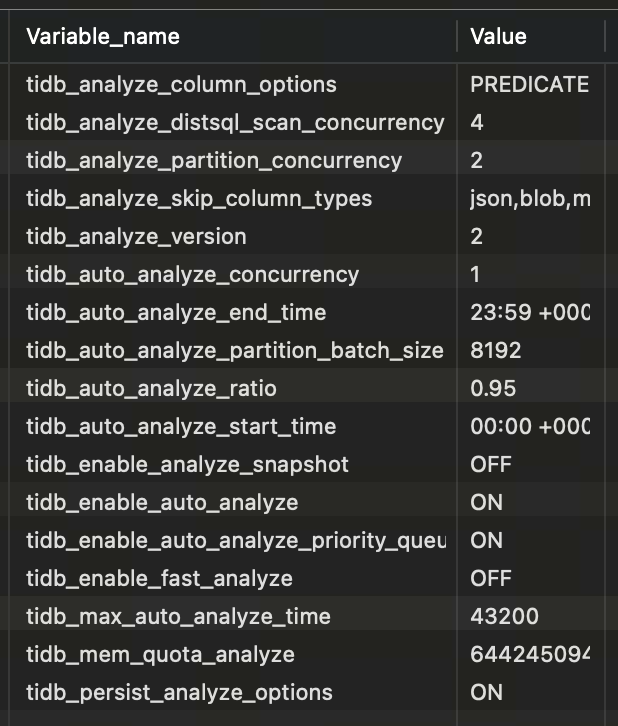
印象中没配置过这些参数,应该是默认的吧
tidb_schema_cache_size:536870912
tidb_schema_version_cache_limit:16
有猫万事足
27
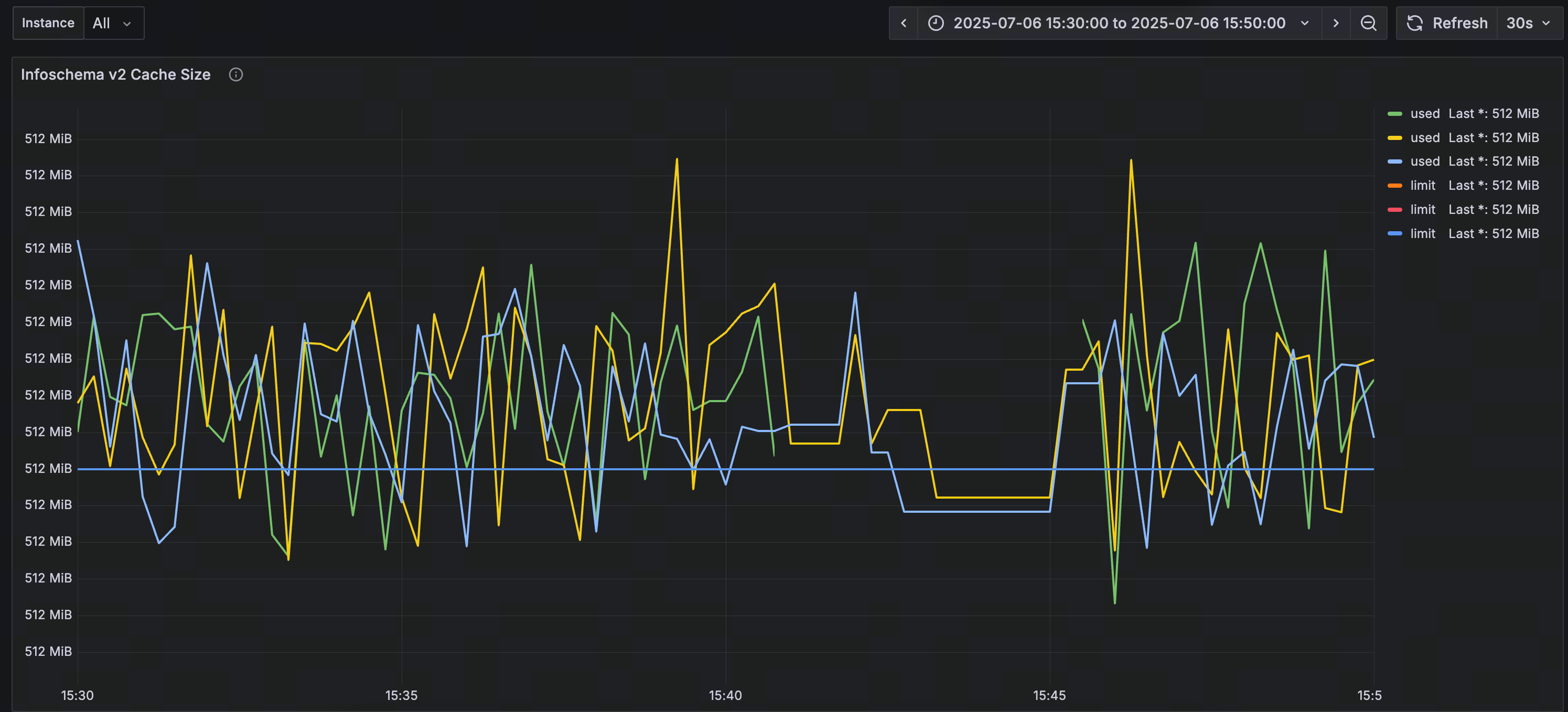
你这确实是默认值,最大只有512Mb,但你这个图里面看怎么都不止512Mb。
起码3-4g了。bug的概率很高了。
再看看这个图吧,如果说这个图统计的内存占用和heap profiling也不对上,我感觉就是bug了。
有猫万事足
29
有一个类似的issue。
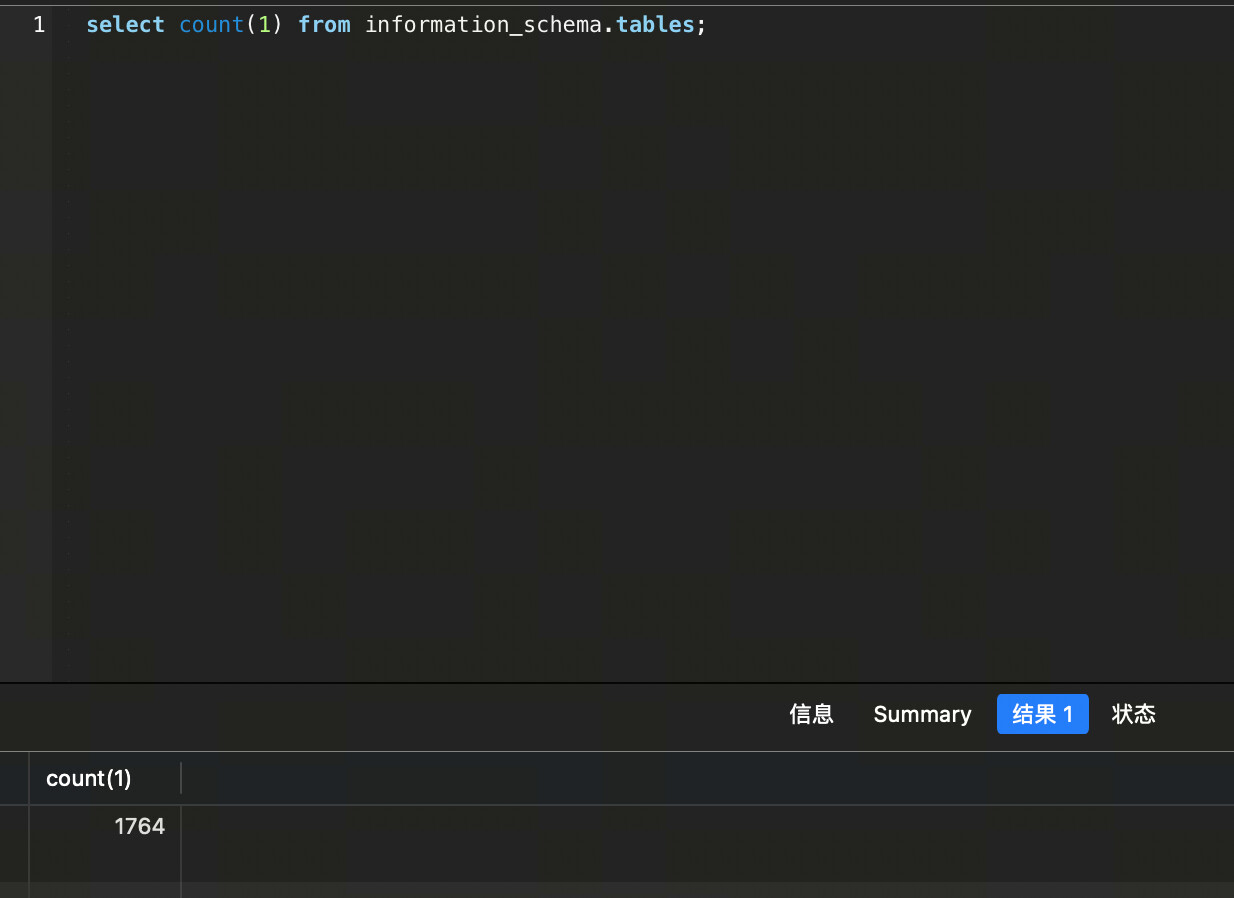
里面提到,当有100w表的时候,执行下面这个语句,
select count(1) from information_schema.tables;
导致了oom。
感觉和这个问题很像。你可以自己判断一下是不是类似这种表或者information库下元数据非常多的场景。
进一步的问题在于修复。这个issue修复直接合到了master上,没有在8.5分支上合并,我对比了一下修复代码和8.5.2版本,确实这部分修复不在8.5分支上。
这也就造成了目前还没有可用的子版本,可以通过升级修复这个问题。
wind
(Ti D Ber B Bgs Ljoo)
30
我理解上面issue问题是SQL占用内存超过tidb_mem_quota_query时,才可能触发的吧。
突然想起来,我们这边有500+张表的健康值低于50(这其中大半健康值为0),因为会频繁auto_analyze,所以有次优化把tidb_auto_analyze_ratio调整为0.95了。
可能是这块的问题不?
有猫万事足
31
期望看到的是2,也就是select 可以被tidb_mem_quota_query限制住。
实际结果是3,tidb oom了。
如果是auto_analyze的问题,应该只有ddl owner会oom。也就是说只会有一个tidb节点内存升高,不会是2个tidb节点都升高。
空region有点多是个问题,但我感觉和这个内存的问题关系不大。
lllzd
(时光旅行者)
32
多条日志中出现了 context canceled 错误,这通常表示某个请求或任务在执行过程中被取消了。这种情况可能是因为客户端超时、服务器资源不足(如内存耗尽)或者其他原因导致的。
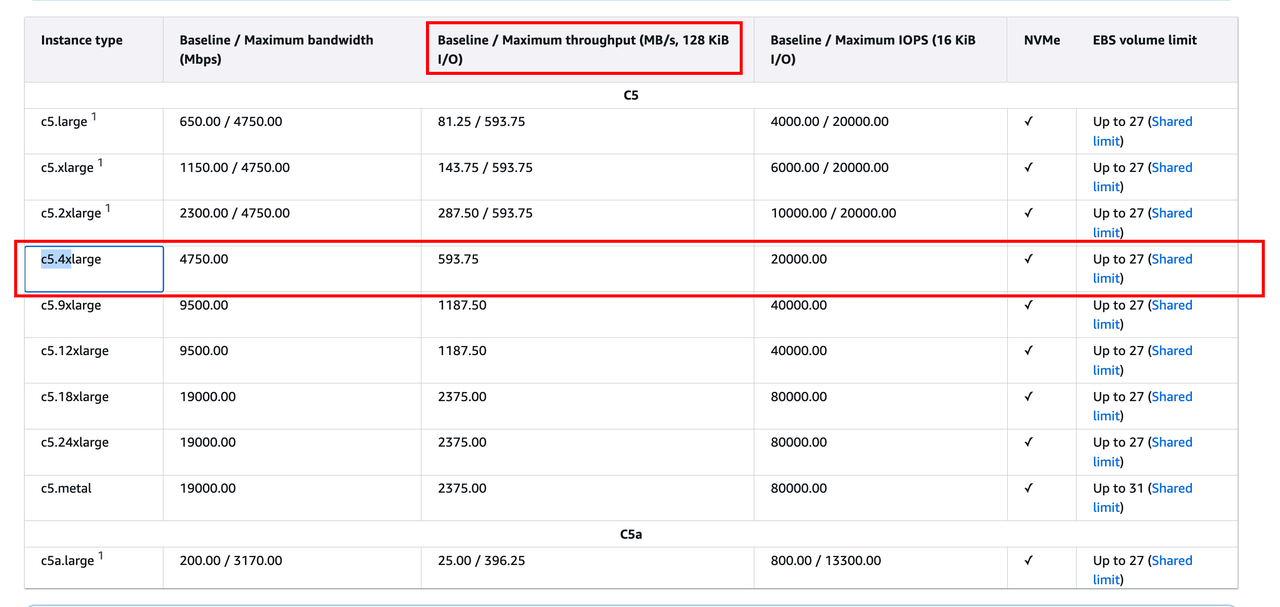
aws ECS购买的带宽/iops这种指标是多大的,印象是要单独买。
wind
(Ti D Ber B Bgs Ljoo)
34
tidb几台都是c5.4xlarge规格
tikv是c5a.8xlarge规格
wind
(Ti D Ber B Bgs Ljoo)
35
断开这种情况可能是有多,业务上有查询超时相关的设定,可能会断开。
wind
(Ti D Ber B Bgs Ljoo)
36
这边慢SQL里看auto_analyze,有运行几分钟的。如果不是这方面导致的,目前版本BUG的可能性比较大吧?
1 个赞
wind
(Ti D Ber B Bgs Ljoo)
39
感谢您的帮助。
目前这种这个问题,除了升级外,有啥临时规避措施嘛?
有猫万事足
40
不,你还是仔细阅读一下我上面的关于bug的那个帖子。
如果确定是扫描information_schema下的表,引起的oom。
我判断你这个问题和这个issue相关,主要是你之前发的帖子里面提到有频繁的ddl,所以我怀疑你的information_schema下的元数据会比较多。如果对这些数据做扫描,极有可能触发这个bug。不过这个推断目前还没有得到你的证实。
而且现在问题棘手的地方就在于,没有可用的LTS分支包含这个修复。
那个issue下的修复是合并在master分支上的,生产环境不太可能从master分支做修复的。还要等这个修复合并到8.5分支上去,才有可用的LTS子版本用。
wind
(Ti D Ber B Bgs Ljoo)
41
这边information_schema没有那么大数据量,可能是某种新问题
1 个赞