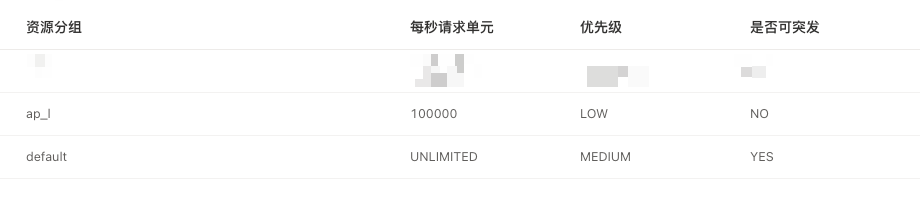
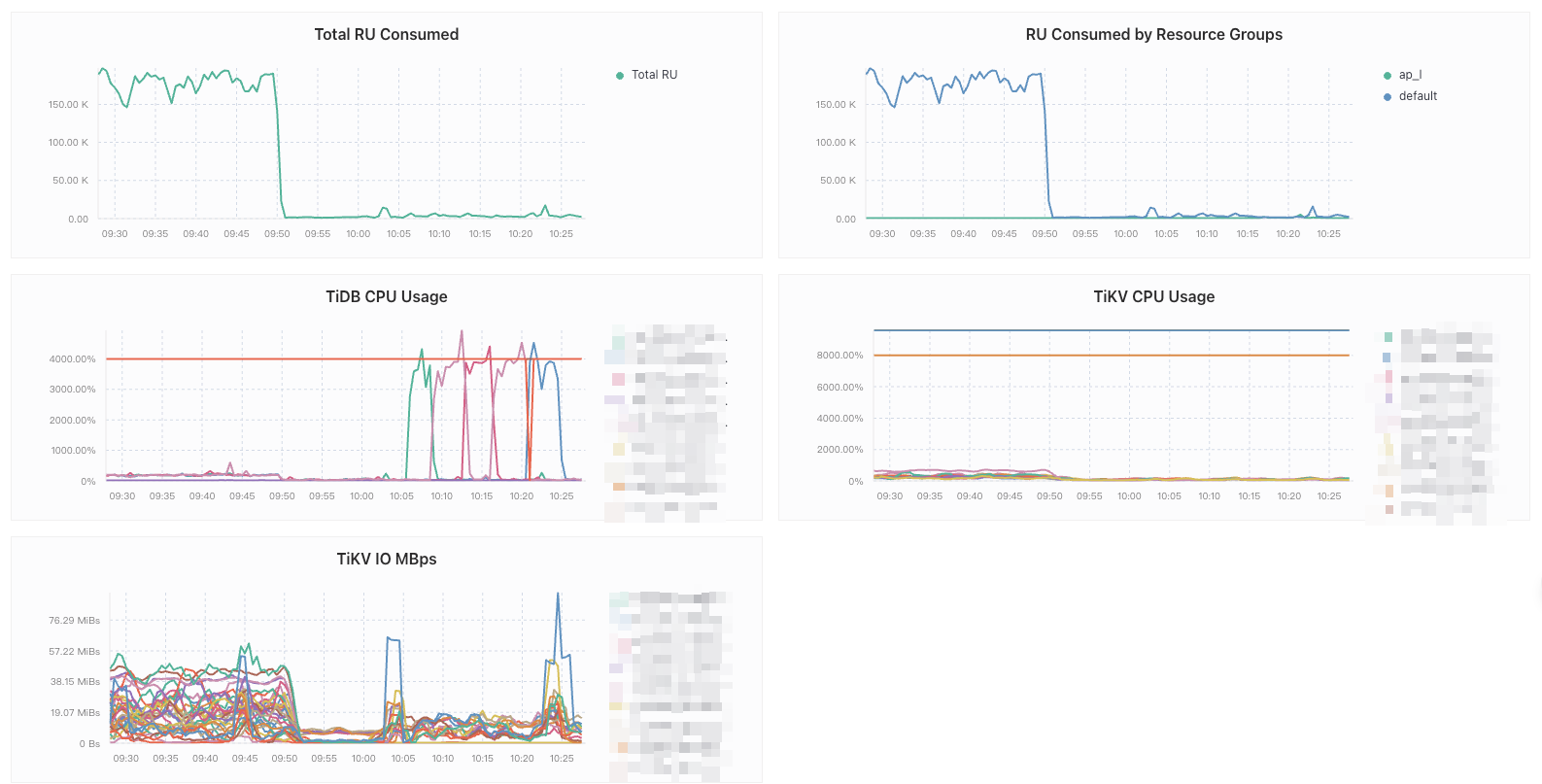
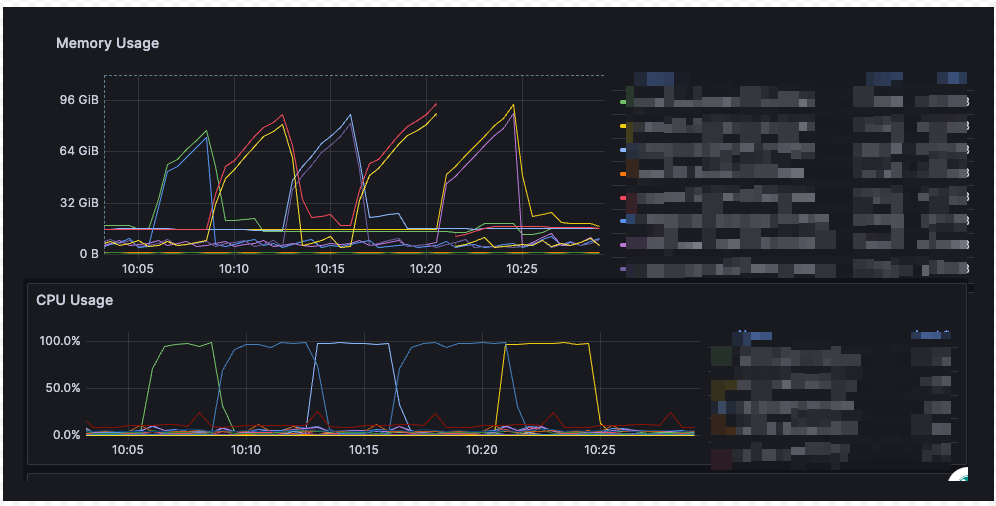
在我的场景中,涉及到大量的聚合类查询,但是发现这类 SQL 的磁盘扫描很少,需要消耗大量的内存和cpu,而对这块儿的限制手段比较少。图中我发现对 io 的限制是走 RU 的,但是对 cpu 和内存的聚合类查询不走,请教各位对这种场景有什么建议吗?
附加信息:
1 tidb 7.5.4
2 这个表已经加入到 tiflash 中,但优化器选择的是 TiKV,可能是带 where 过滤出来的结果集较小,所以优化器认为代价更优
SELECT
SUM(field1) AS metric1,
SUM(field2) AS metric2,
ROUND(SUM(field3), 2) AS metric3,
field4,
field5,
‘[REDACTED]’ AS field6,
field7,
‘[REDACTED]’ AS field8,
field9,
‘[REDACTED]’ AS field10,
‘[REDACTED]’ AS field11,
‘[REDACTED]’ AS field12,
field13
FROM
table_x
WHERE
field14 = ‘[REDACTED]’
AND field15 >= ‘[REDACTED]’
AND field15 <= ‘[REDACTED]’
GROUP BY
field7,
field9,
field11,
field12,
field4,
field13