已经按那个做了,还是存在错误。
你这个报错的gtid不对啊,怎么都是0呢,把gtid这块改下
你试试不要把binlog日志读取到本地在分析,直接远程分析,传输过来的是sql内容。
“binlogType”: “remote”。
我的DM同步就是用的远程模式,没有存本地
感觉这种模式适用于开启GITMOD的情况,我的没开启,所以都是 0
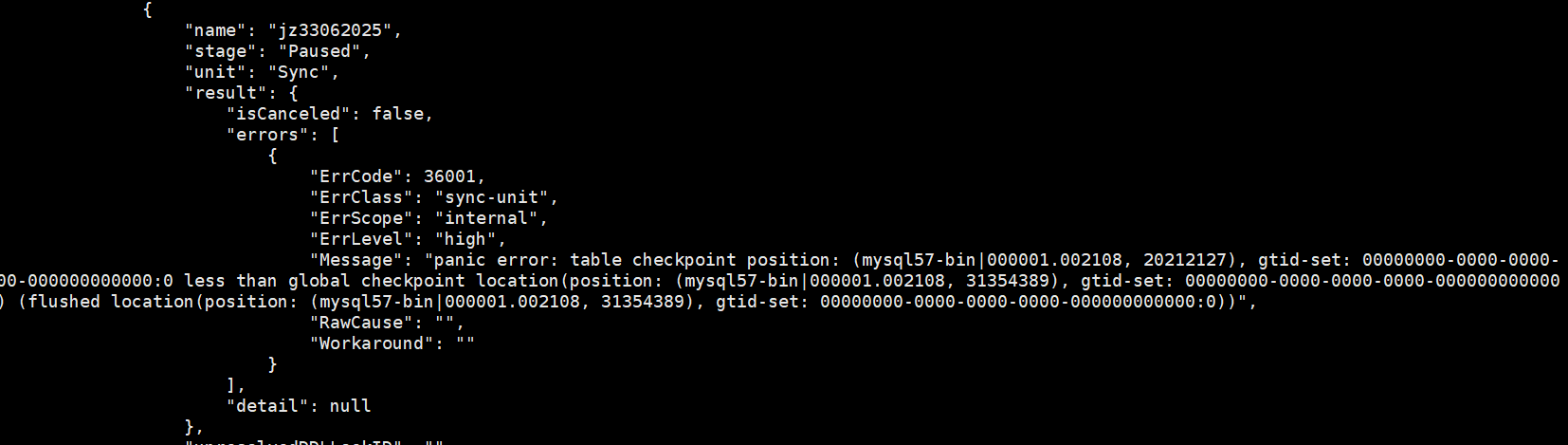
我看了半天,其实就是把binlog拷贝过来,本身log中的pos位置已经不对了(int32溢出)。你就算再执行也不对

这里还是报错lessthan啊,你按照这个步骤做了么,停止迁移任务,更改原信息表
1.通过 stop-task 停止迁移任务。
2.更改元信息表
将下游 dm_meta 数据库中 global checkpoint 与每个 table 的 checkpoint 中的 binlog_name 更新为出错的 binlog 文件,将 binlog_pos 更新为已迁移过的一个合法的 position 值,比如 4。
例如:出错任务名为 dm_test,对应的 source-id 为 replica-1,出错时对应的 binlog 文件为 mysql-bin|000001.004451,则执行 UPDATE dm_test_syncer_checkpoint SET binlog_name=‘mysql-bin|000001.004451’, binlog_pos = 4 WHERE id=‘replica-1’;。
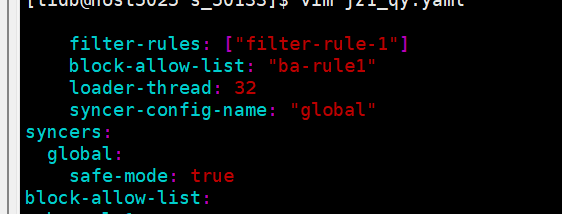
3.更改复制模式为安全模式
在迁移任务配置中为 syncers 部分设置 safe-mode: true 以保证可重入执行。
前半段是对的,这个修复方法的关键在于,把binlog拷贝过来当作relay log使用,relay log这块是dm自己实现的,可以绕开4g。
所以你后半的理解差一步。前半是对的。
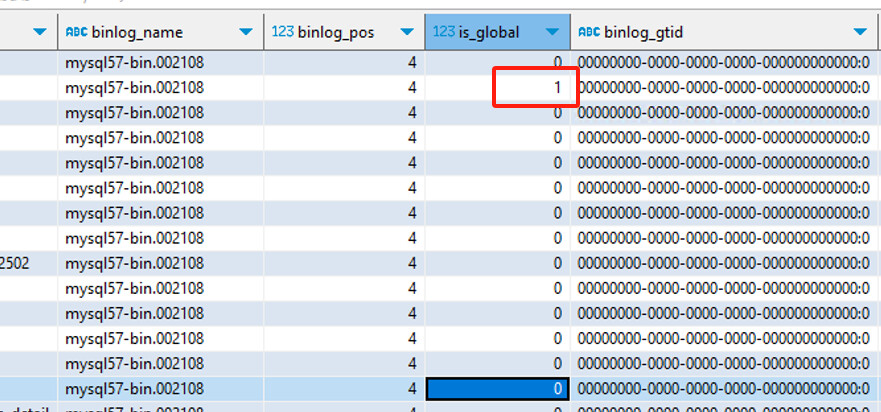
你就看看dm_meta库里面[task-name]-_syncer_checkpoint这个表里面还有没有 31354389这个数字。这个global checkpoint的地方可能是漏改了。

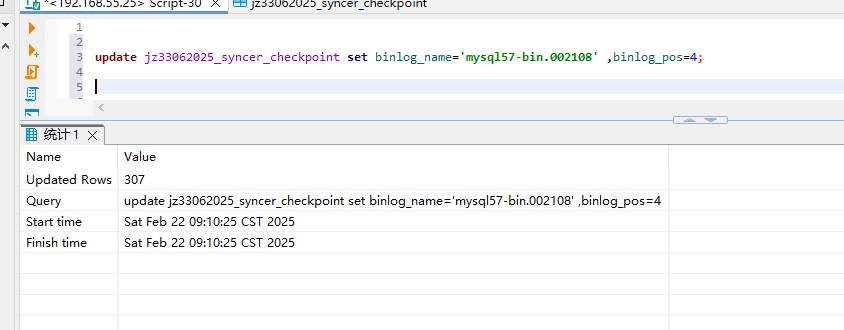
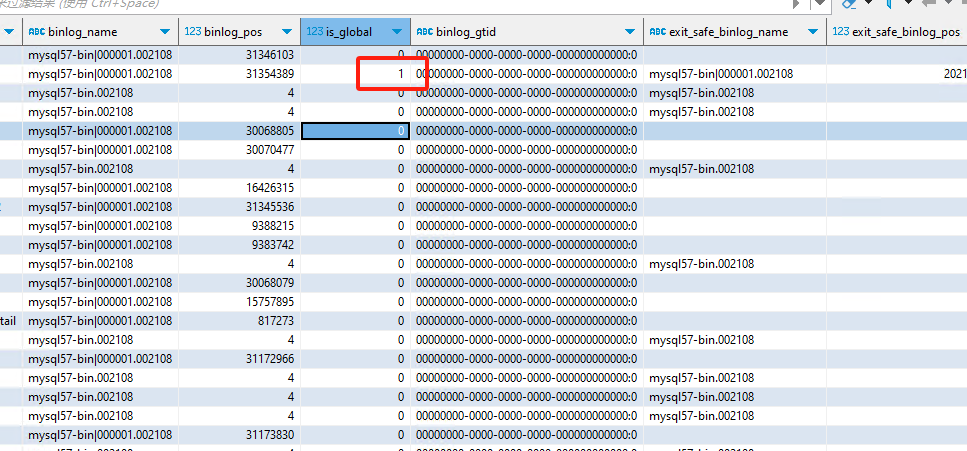
原来就是远程分析,后来不行才改为本地模式
不应该呀,网络没问题,需要的源端服务器CPU资源很少呀。那就就改mysql吧吧binlog改成1G