tidb dm 多库多表如何切换数据源
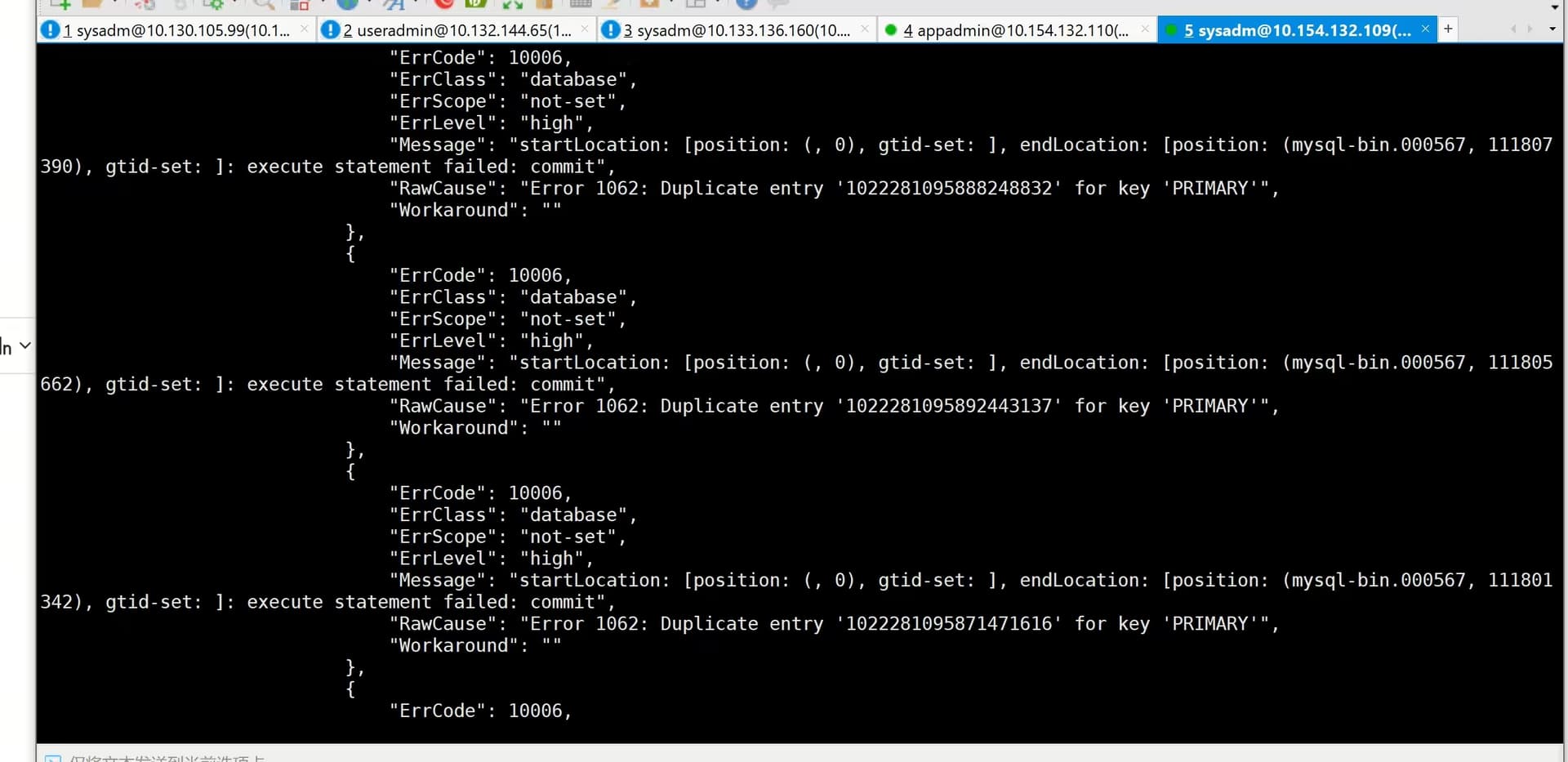
停止task 任务切换数据源后启动task任务报错
报错的原因是 duplication entry。
也就是你换数据源是成功的,但是从binlog里面读出来的数据id重复了。
你确定这是正常现象嘛?
一般来说这意味着你在新的源上的binlog position是有问题的。所以错误里面也给出了position的具体位置。你需要确认一下的。
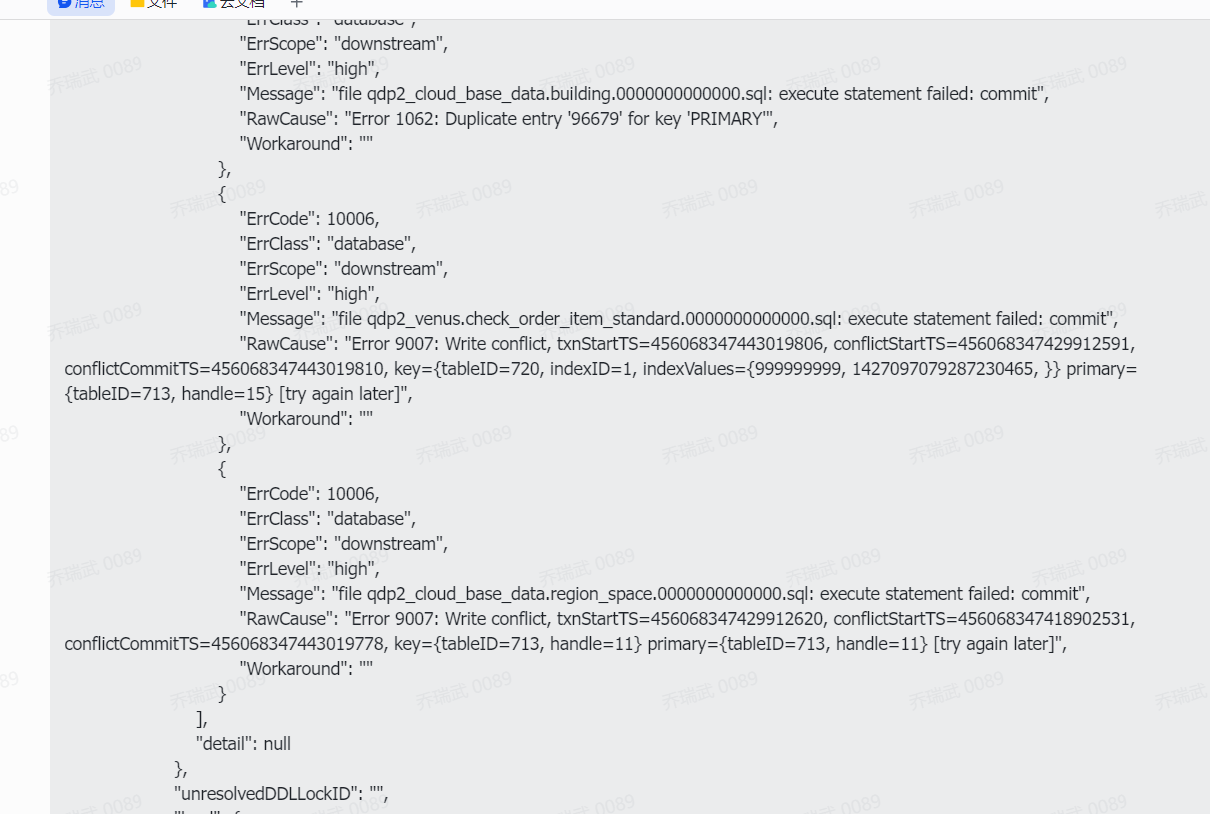
如果你确定binlog position没问题,id冲突应该存在并希望新数据源覆盖写入,那可以开启安全模式。把insert into改写成replace into。

下面的写冲突报错先不管,你上面这个还是主键重复了啊。
我上面写的你再仔细看看呢。
你需要确定这个重复是否符合预期?如果符合预期,那就开安全模式。
loaders: # load 处理单元的运行配置参数
global: # 配置名称
pool-size: 16 # load 处理单元并发执行 dump 处理单元的 SQL 文件的线程数量,默认值为 16,当有多个实例同时向 TiDB 迁移数据时可根据负载情况适当调小该值# 保存上游全量导出数据的目录。该配置项的默认值为 "./dumped_data"。 # 支持配置为本地文件系统路径,也支持配置为 Amazon S3 路径,如: s3://dm_bucket/dumped_data?endpoint=s3-website.us-east-2.amazonaws.com&access_key=s3accesskey&secret_access_key=s3secretkey&force_path_style=true dir: "./dumped_data" # 全量阶段数据导入的模式。可以设置为如下几种模式: # - "logical"(默认)。使用 TiDB Lightning 逻辑导入模式进行导入。文档:https://docs.pingcap.com/zh/tidb/stable/tidb-lightning-logical-import-mode # - "physical"。使用 TiDB Lightning 物理导入模式进行导入。文档:https://docs.pingcap.com/zh/tidb/stable/tidb-lightning-physical-import-mode # 当前 "physical" 为实验特性,不建议在生产环境中使用。 import-mode: "logical" # 逻辑导入模式针对冲突数据的解决方式: # - "replace"(默认值)。表示用最新数据替代已有数据。 # - "ignore"。保留已有数据,忽略新数据。 # - "error"。插入重复数据时报错并停止同步任务。 on-duplicate-logical: "replace"
https://docs.pingcap.com/zh/tidb/stable/task-configuration-file-full
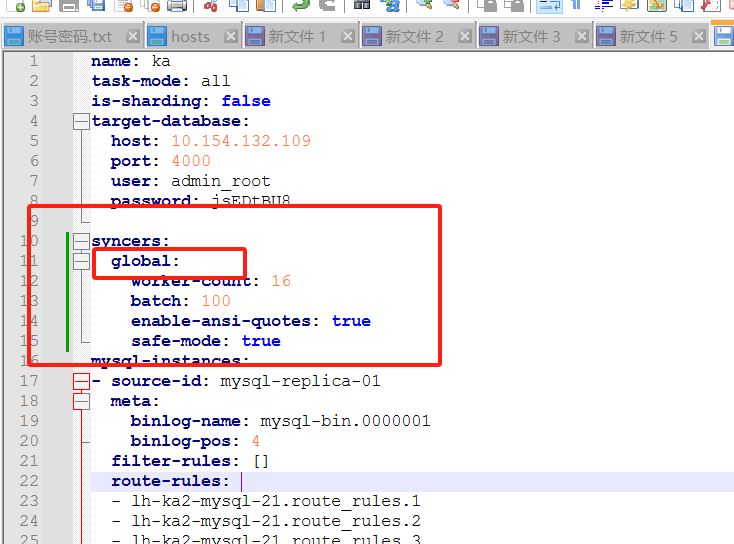
loaders 里面的 on-duplicate-logical是怎么设置的?如果不是syncer那就只有这里的。除此之外,我也想不出哪里还有可能导致这个问题。