huixiang
(huixiang)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】TIDB7.5
【遇到的问题:问题现象及影响】
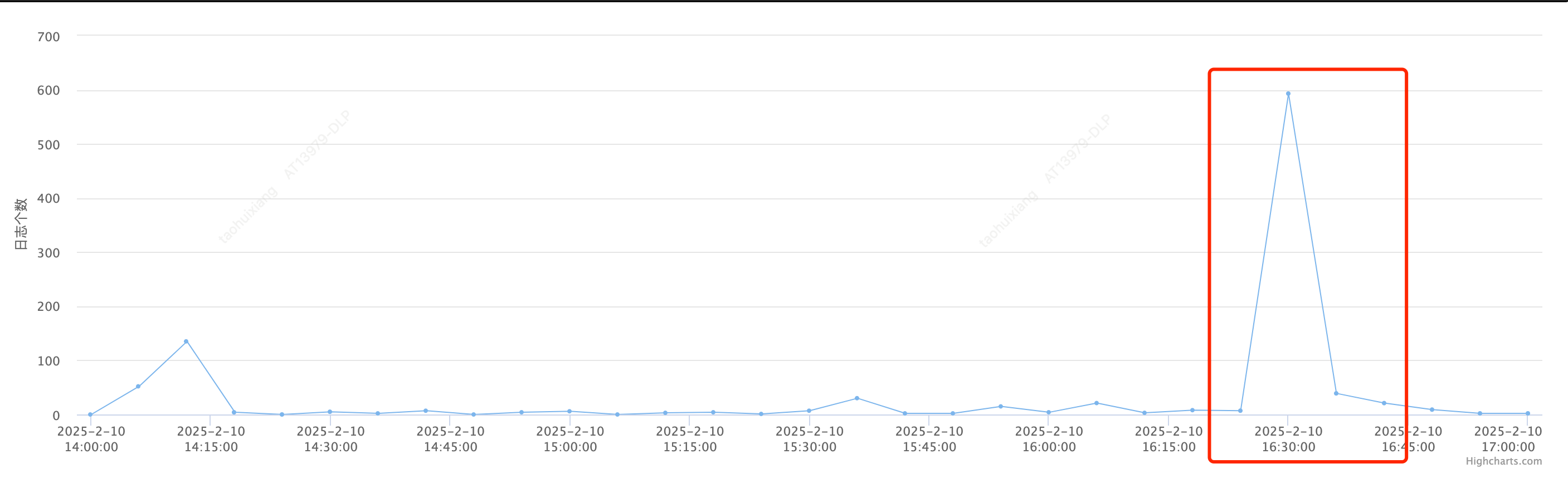
问题:业务反聩TIDB查询最近总有偶发的超时,时间1-几分钟。如16:20-16:40有超时
1)查TIDB监控,TIDB TP99变化不大
2)PD pd_stderr.log 日志有出错
[WARN] [retry_interceptor.go:62] [“retrying of unary invoker failed”] [target=etcd-endpoints://0xc002b405a0/10.27.xx.112:2379] [attempt=0] [error=“rpc error: code = DeadlineExceeded desc = context deadline exceeded”]
3)TIDB日志tidb.log上有错误(但是此类错误一直都有)
3.1) ‘PD:client:ErrClientGetTSO]get TSO failed, rpc error: code = Unknown’
3.2) table reader fetch next chunk failed
【资源配置】
【复制黏贴 ERROR 报错的日志】
【其他附件:截图/日志/监控】
问题时间: 时间16:30左右(但可能有误差+5分钟,取16:25-16:40分析)
1) TP99平稳
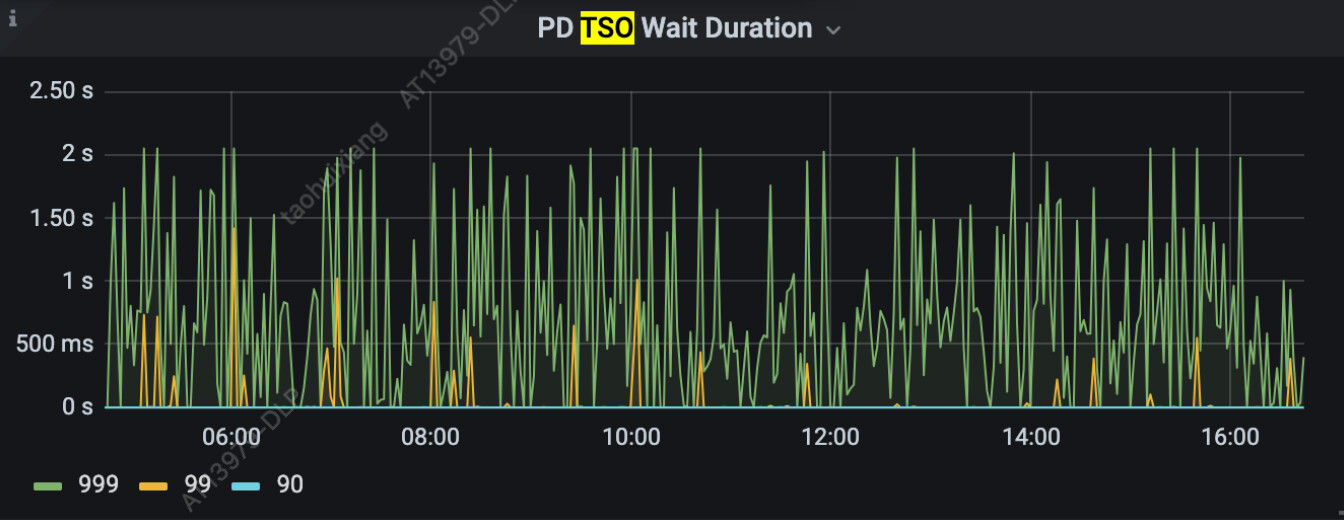
2) * PD TSO Wait Duration
3)其它
4)机器情况
load有时会有大的毛刺,但并不固定是某台机器。
kang
2
client:ErrClientGetTSO] get TSO failed 错误表明TiDB客户端获取时间戳服务(TSO)时失败。这可能是由于PD节点之间的网络延迟
Jasper
(Jasper)
3
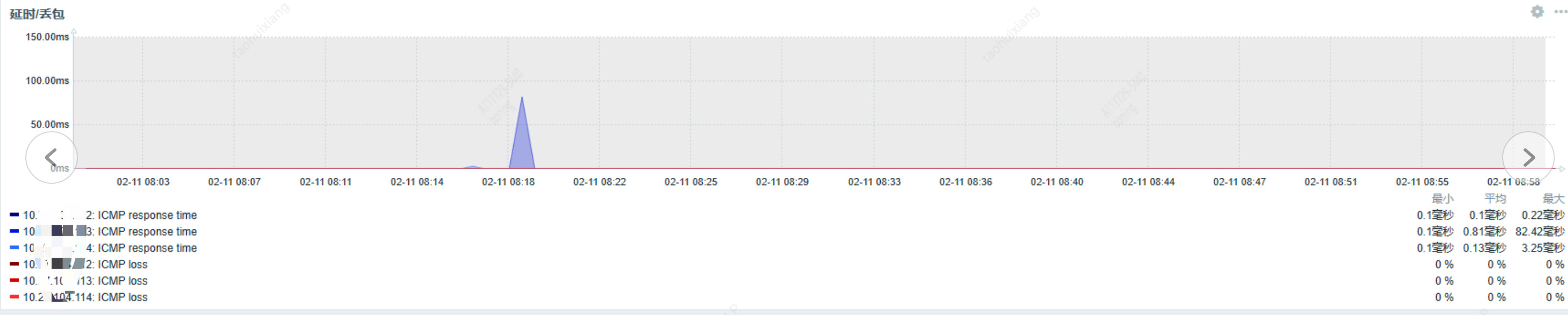
监控看下 blackbox 页面,看看 pd 机器的 ping 延迟情况如何?
nobody
(不定时出现)
4
看下来大概率是 load 过高导致的,先查一查 load 高的原因吧。另外这个日志个数 是 tidb 的日志?
templey
(templey)
5
我觉得你应该检查下是到pd的网络问题还是pd负载问题
1 个赞
有猫万事足
7
这网络太差了。难怪你的tso wait经常到2s。
拿个tso都2s,这一段的所有sql都将会是慢查询。
这个太影响运行稳定性了。找你们网络侧的小伙伴好好调一下。
1 个赞
这个网络是有问题,延迟太高。另外cpu load也不稳定,需要top检查下哪个进程异常导致的
zhanggame1
(Ti D Ber G I13ecx U)
11
网络大概率有问题,直接登录系统查下netstat -i 看看是不是有报错丢包,每个服务器都看看
乡在人间
(Ti D Ber Ki Nyc B Fs)
14
重点还是解决网络问题,延迟太高了。
另外:
一、TSO请求处理瓶颈的处理方向:
高并发场景下 PD 的 TSO 批处理吞吐不足,可调整 PD 参数tso-update-physical-interval(默认 50ms)至更低值(如 30ms),提升 TSO 分配频率。
检查pd-server的tso-save-interval配置,确保 TSO 持久化间隔合理(默认 3s),避免频繁刷盘导致性能波动。
二、v7.5 +可临时启用TiDB的TSO 容错模式(需要测试):
SET GLOBAL tidb_enable_async_commit=ON; – 异步提交降低TSO依赖
SET GLOBAL tidb_enable_1pc=ON; – 一阶段提交减少TSO请求次数