3个tidb,第一个是从1开始,第二个从30001开始,第三个从60001开始,重启第一个,第一个从90001开始
自增 id 以及序列均会在 tikv 记录已分配的最大 ID 值,新划分的区间永远是 max(tikv 记录的 id) +1 以上。不会出现重复问题。可以把这里的 tikv 当成分配中心。
针对负载均衡组件
首推硬负载,性能好,功能强大,有原厂支持,
其次考虑各家云厂商的 LB 负载,
最后考虑 nginx/haproxy/tiproxy 等负载。
单独针对 tiproxy 和 haproxy 对比的话
tiproxy 属于官方工具,但是还在持续迭代,当前的局限可参考官方文档,优点是有商业支持。
haproxy 属于比较成熟的工具了,但是本身软件不具备高可用,没有商业支持。
个人觉得非核心业务场景 tiproxy 和 haproxy 没啥明显的优劣势,以满足业务需求为主。
核心场景的话最好还是搞有商业支持的产品。
我看你连接没有变,在一个界面呢以为是 一个server呢,那你 通过proxy登录的是吧
这里是有疑问的,官方文档提示ID区间都是3w为单位的,所以server服务发生重启的话,起始值都是3w的倍数+1吧 ,且区间范围长度也是3w
新划分的区间永远是 max(tikv 记录的 id) +1 以上 ==> 你这个是针对的什么场景, 起始值是这个计算,那么范围上限呢?
有商业支持肯定是好的,问题是公司老板不愿意花这个钱 ![]() ,所以只能另寻他法了
,所以只能另寻他法了
分布式数据库的自增,确实要复杂一些
tikv 上记录的值,不一定是 3w 的倍数。 tidb server 重启后会从 tikv 查询 ID 最大值,然后把 ID + 范围的新的 ID1 值写入到 tikv,以此来确保所有节点拿到的都是当前集群的最大值。
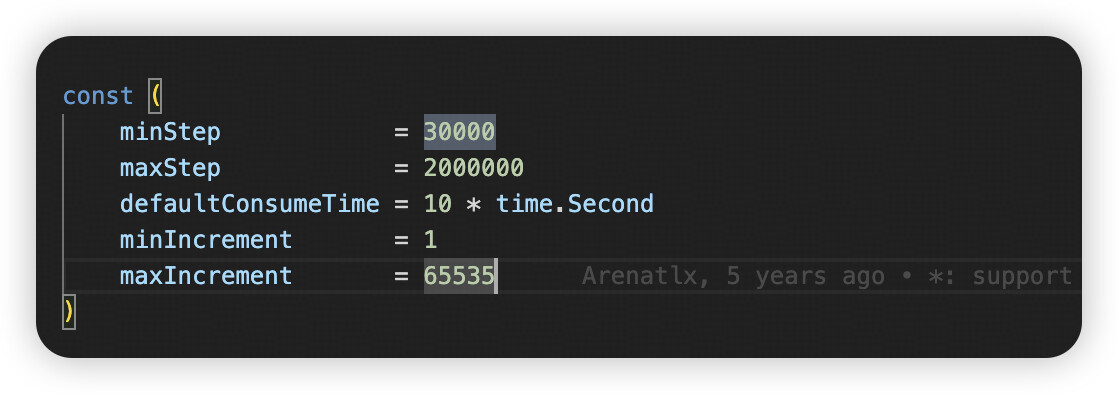
范围默认 3w ,然后范围会根据自增 id 的使用速率自适应变大。https://github.com/pingcap/tidb/pull/10978
1 个赞
大概明白你的意思了 。那我现在遇到一个ID大小从当前一个比较大的值 跳回到 之前某个ID范围(server也从A跳到B)中的值,就是你描述的这个逻辑了
初始值(本次范围的最小值)是当前server节点最大值加1,最大值不一定就是当前server节点最大值加 3W了,按照实际情况应该就是上次分配没有使用完的ID 区间的后半部分 (或者说上限是某个3W的倍数-1)
最好还是用haproxy吧,我们一值用的这个,tidb8版本可以用tiproxy
tiproxy 可以考虑一下
统计了下,貌似大多数还是选择haproxy ,目前生产7.5.1 我也是打算用haproxy
嗯,目前也是调试haproxy中
HAProxy是成熟稳定,有支持
![]() 我们现在用和haproxy
我们现在用和haproxy
haproxy 之上有没有再做keepalived?
做了,haproxy+keepalived
1 个赞
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。