作者:王歌 苏丹
技术架构图
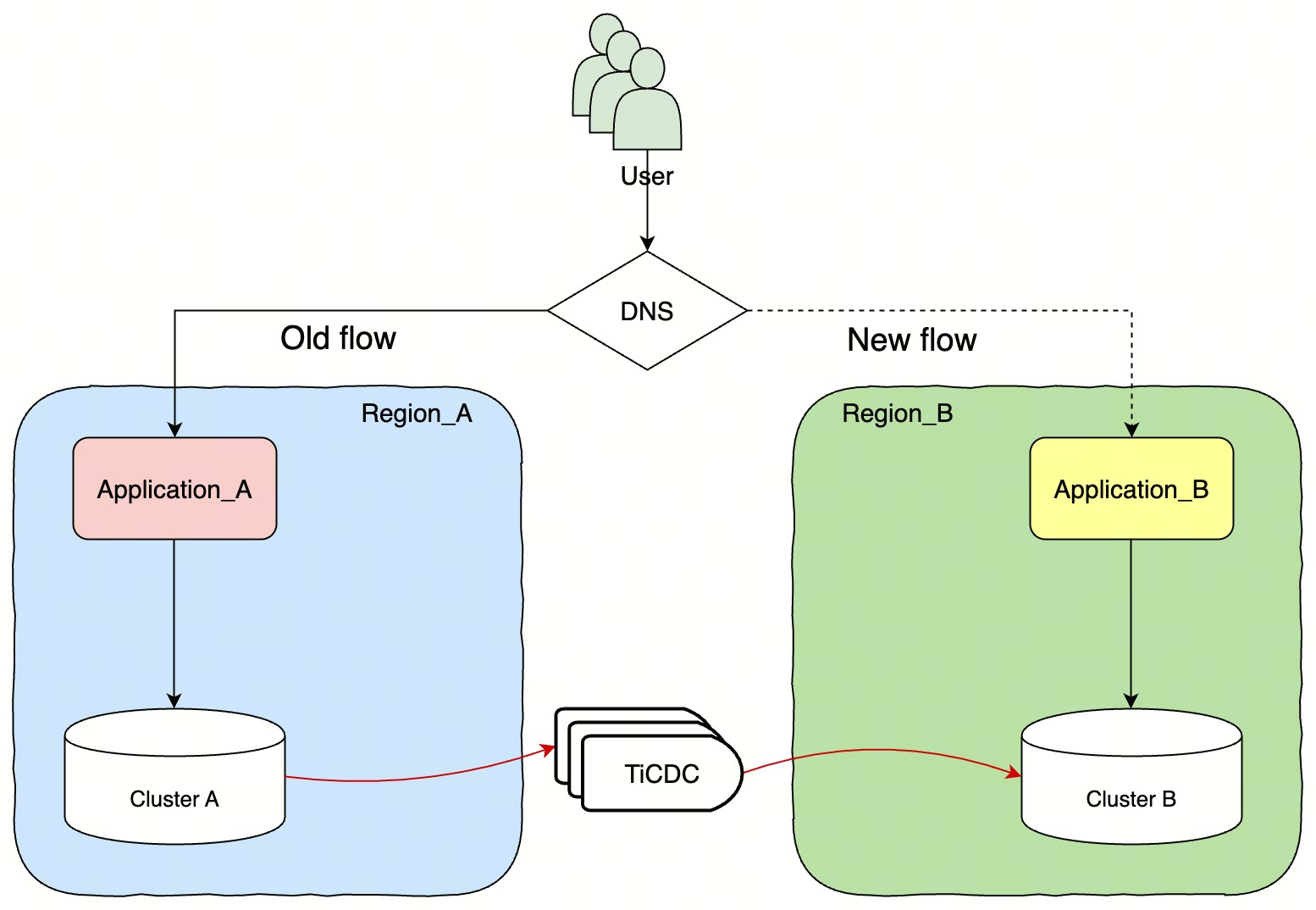
基本能力与限制
-
由于跨 Region 进行数据实时同步,整体同步时延与真实的网络性能有直接关系
-
数据增量复制建议 上下游集群的延迟在 500ms 以下,网络吞吐大于 1Gbps
-
为了保证数据一致请在 开启数据同步侧写入数据,否则可能导致数据同步失败
方案实施
准备工作
确认集群写流量写流量吞吐
-
通过 TiDB 监控 确认 具体写入的 QPS 主要包括 (Insert、Update、Delete)
-
由于存在 数据批量修改情况,还需要关注 Transcation 面板
确定全量数据同步所需资源
-
EC2 机器,用于 dumpling 导出
-
建议机器配置 8c,16g
-
将该机器的网络和 tidb cloud 打通(保证可以访问tidb url即可)
-
部署 dumpling v7.1.1 版本 使用 Dumpling 导出数据
-
curl --proto '=https' --tlsv1.2 -sSf https://tiup-mirrors.pingcap.com/install.sh | sh
tiup install dumpling:v7.1.1
- S3 位于新加坡
确定 数据同步所需资源
-
TiCDC 流量评估
- 4RCU
| Specification | Maximum replication performance |
|---|---|
| 2 RCUs | 5,000 rows/s |
| 4 RCUs | 10,000 rows/s |
| 8 RCUs | 20,000 rows/s |
| 16 RCUs | 40,000 rows/s |
| 24 RCUs | 60,000 rows/s |
| 32 RCUs | 80,000 rows/s |
| 40 RCUs | 100,000 rows/s |
编写增量数据复制规则
- 数据增量同步,可直接使用 Cloud TiCDC 默认配置进行数据同步
调整 GC Lift time 到 48H
# 设置 gc 时间
set global tidb_gc_life_time = 2880m0s;
# 查看 gc 时间
show variables like 'tidb_gc_life_time';
将当前账号和权限记录
建议手动将JP的用户迁移到SG
## 拼接出需要获取的权限
SELECT CONCAT('SHOW GRANTS FOR ''', user, '''@''', host, ''';') AS query FROM mysql.user;
## 查看当前user
select Host,User,authentication_string from mysql.user;
查看当前 sql binding
SHOW [GLOBAL|SESSION] BINDINGS
SHOW GLOBAL BINDINGS;
在 SG 集群创建 binding:CREATE [GLOBAL|SESSION] BINDING
示例:
CREATE SESSION BINDING FOR
SELECT * FROM t1 WHERE b = 123
USING
SELECT * FROM t1 IGNORE INDEX (b) WHERE b = 123;
JP 和 SG 网络打通(pingcap操作)
-
Vpc peering
-
开放白名单
全量数据迁移
全量数据备份
-
为保证数据备份对在线业务最小影响,需要对数据进行分批导出
-
每 Dumpling 建议设置 16 线程进行数据导出
-
预计 90min 可以导出 1.5T 数据
-
参与复制的表都存在主键或唯一索引
-
-T 指定需要同步的表db.table, 如有多个,用","分隔
tiup dumpling -u root -p xxx -h {tidb-url} -P 4000 -t 16 -r 200000 -F 256MiB -T db.table --filetype csv -o "s3://${Bucket}/${Folder}"
备份成功日志输出
[INFO] [collector.go:239] ["backup success summary"] [total-ranges=] [ranges-succeed=] [ranges-failed=0] [total-take=s] [total-kv-size=TB] [average-speed=MB/s] [total-rows=]
全量数据拷贝
将数据直接备份到 SG 的 S3 上,可省去这一步骤
将 S3 的数据从JP移动到 SG,可使用 aws s3 cp/sync s3://bucket/source s3://bucket/dest
参考文档:
https://awscli.amazonaws.com/v2/documentation/api/latest/reference/s3/cp.html
https://repost.aws/zh-Hans/knowledge-center/move-objects-s3-bucket
全量数据还原
参考:https://docs.pingcap.com/tidbcloud/import-csv-files,AWS S3 导入 TiDB Cloud 集群操作手册
在 tidb cloud console 将操作,将文件导入 SG 集群
增量数据迁移(示例仅供参考)
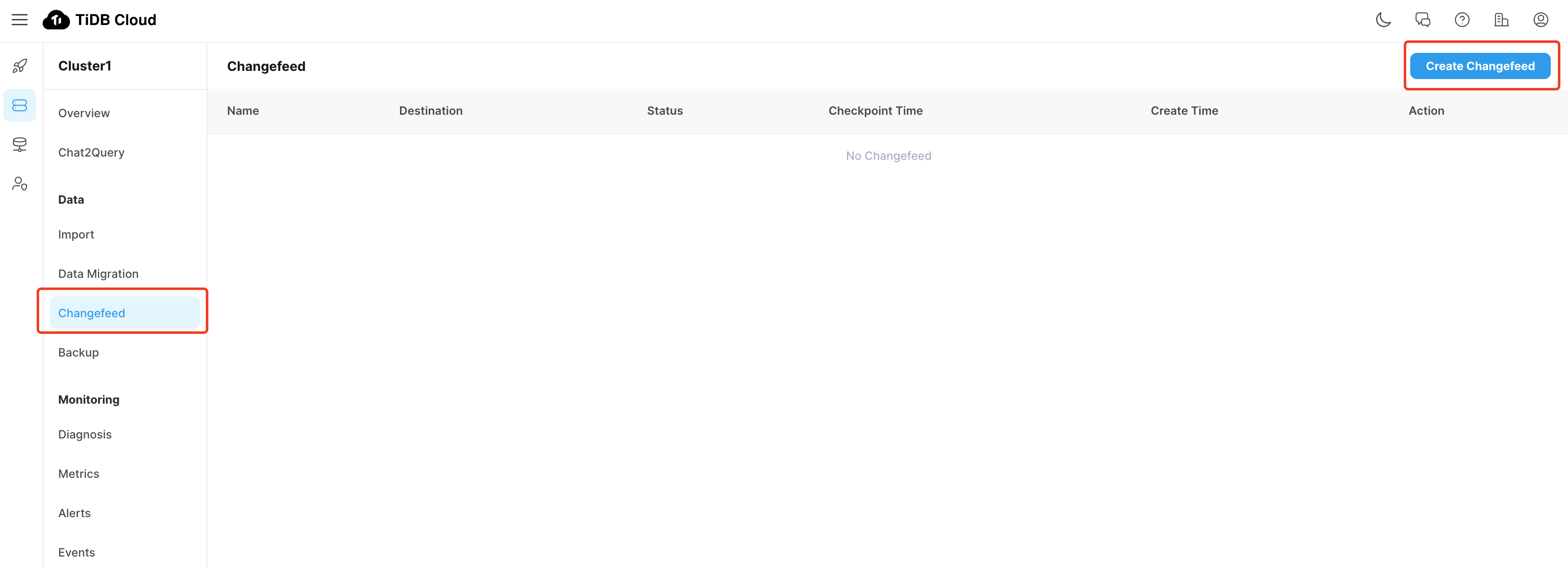
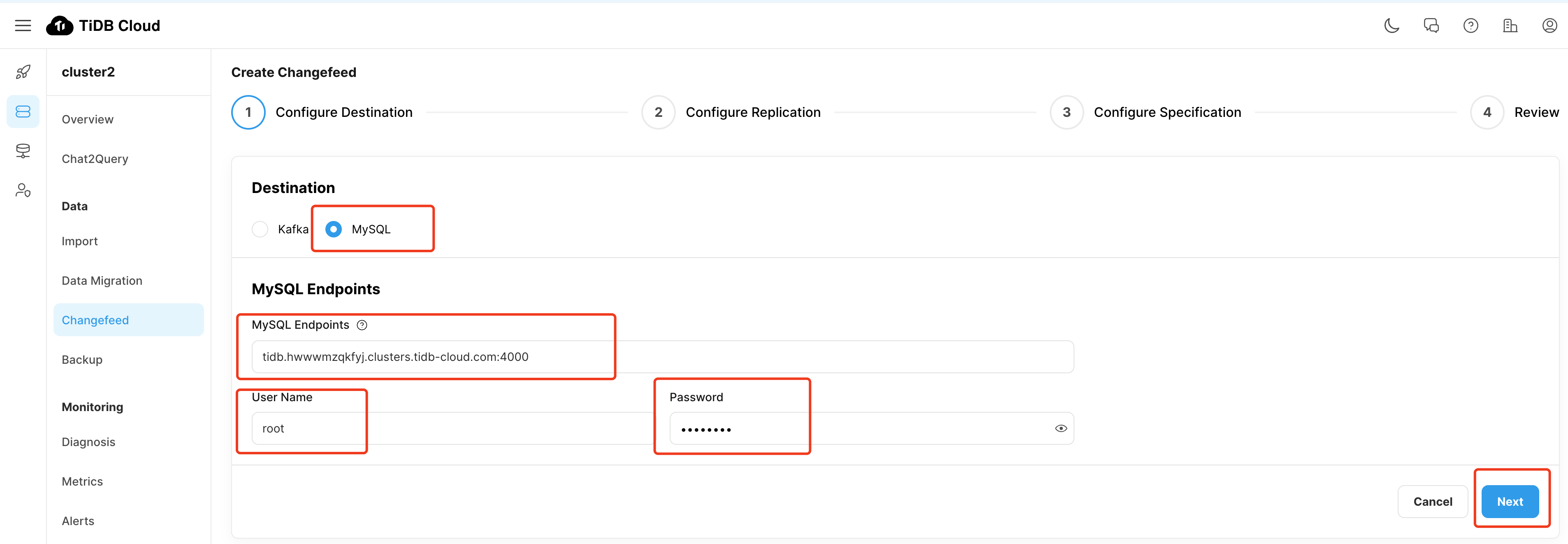

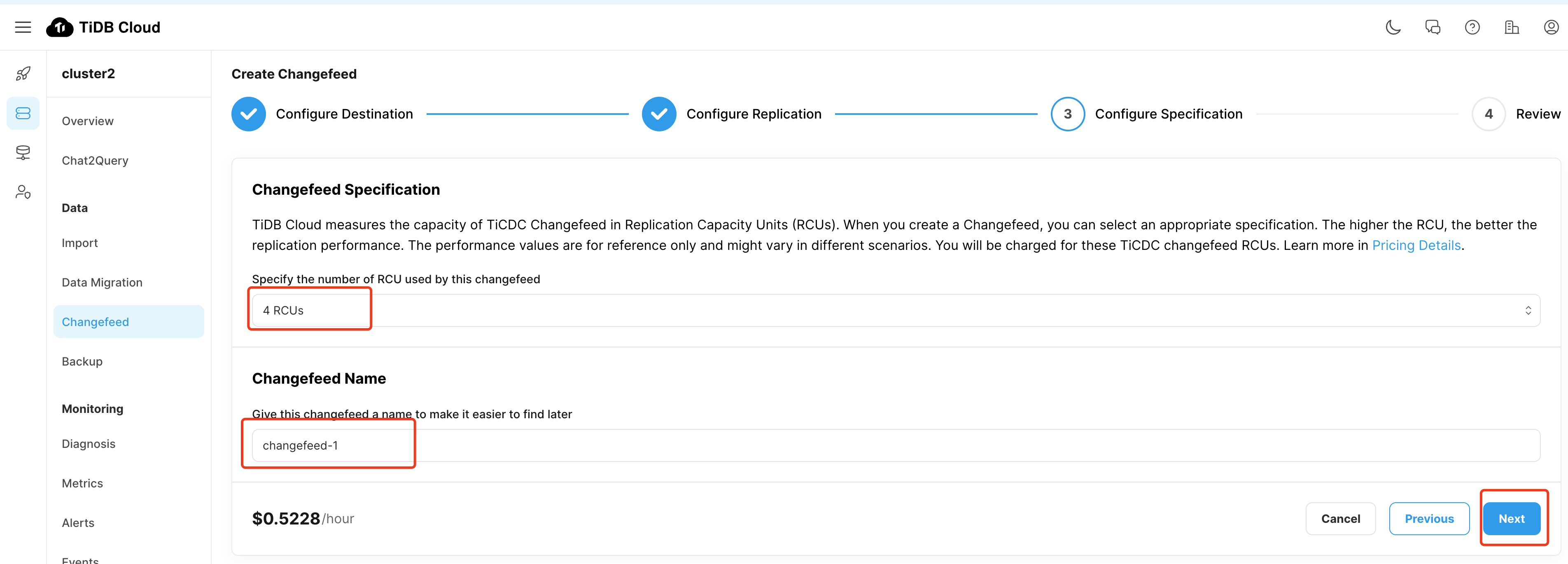
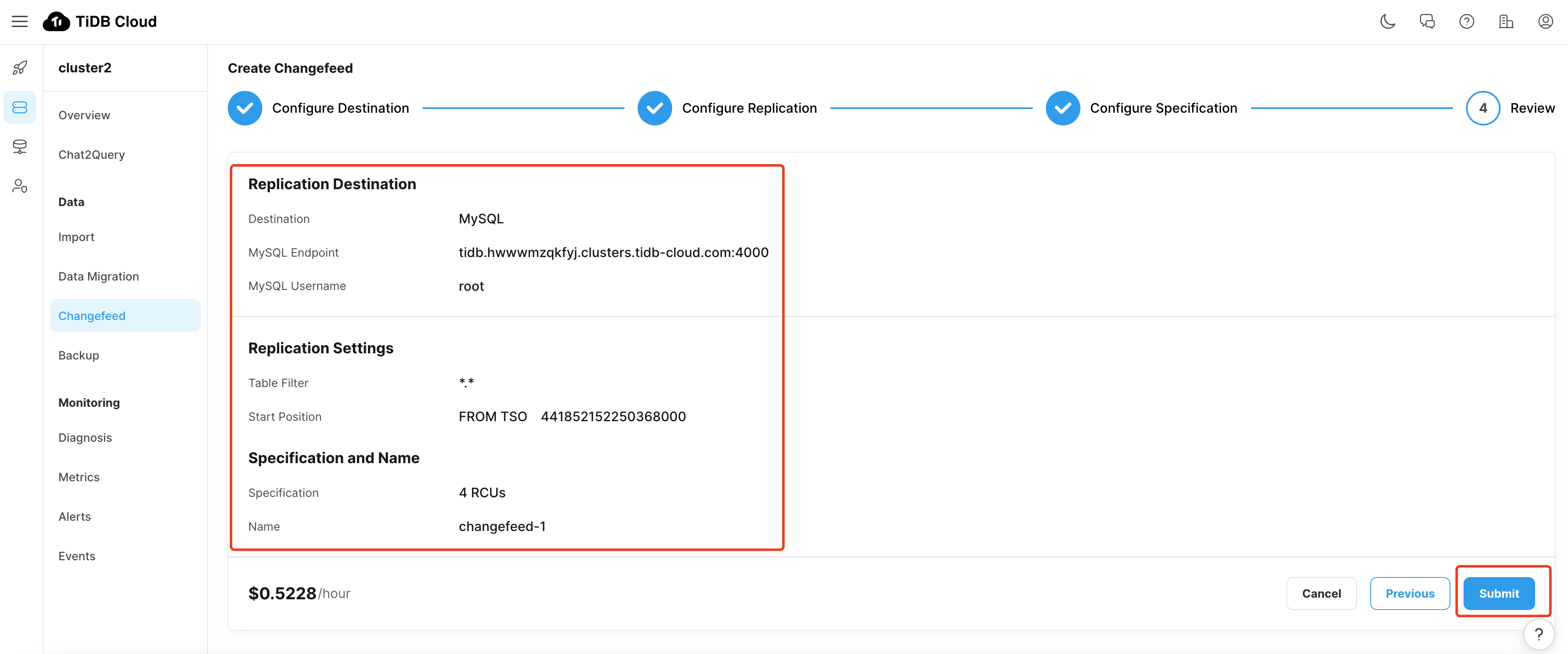
等待 CDC 创建成功
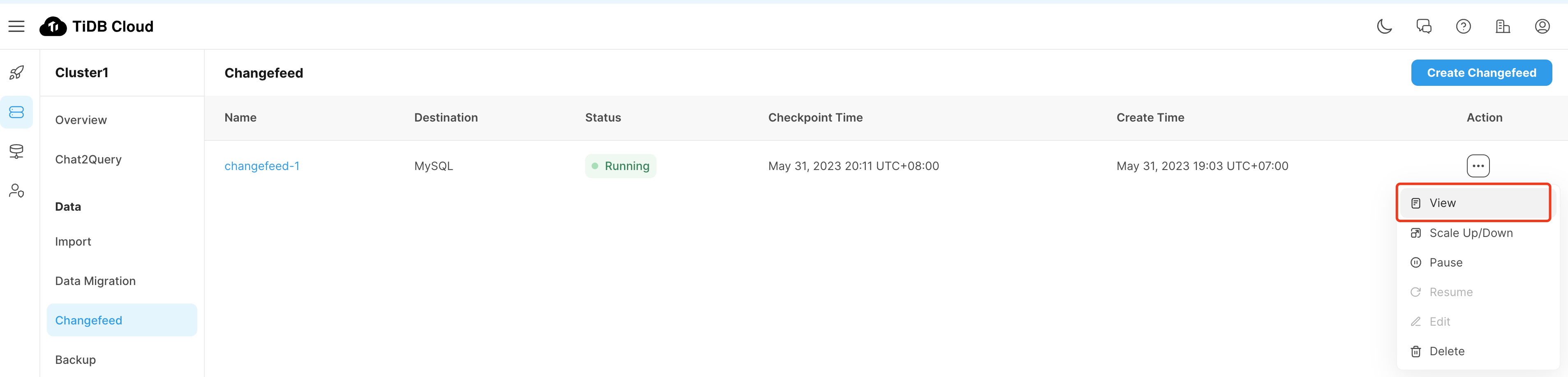
检查 Checkpoint TS 在推进,并且为当前时间
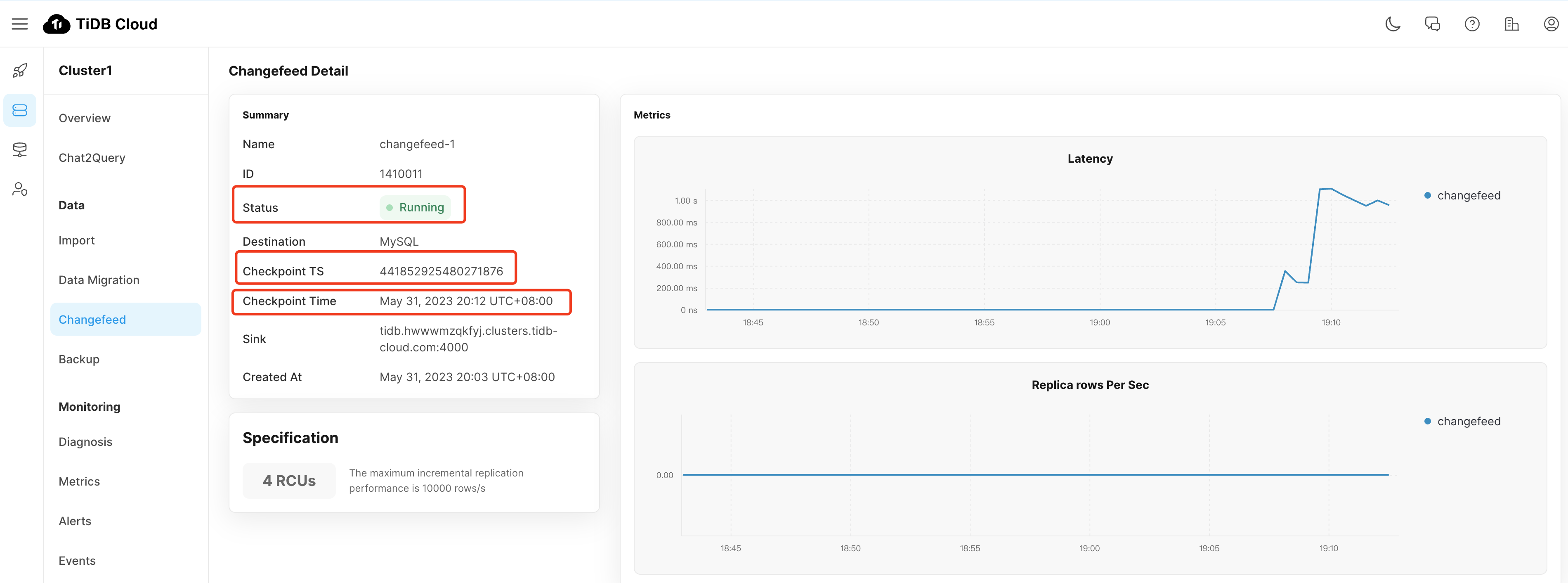
SG集群配置确认
恢复 GC Lift time
默认为 10min,建议设置为 30min,或根据实际情况进行调整
# 设置 gc 时间
set global tidb_gc_life_time = 30m0s;
# 查看 gc 时间
show variables like 'tidb_gc_life_time';
确认 sql binding情况
SHOW GLOBAL BINDINGS;