h5n1
(H5n1)
1
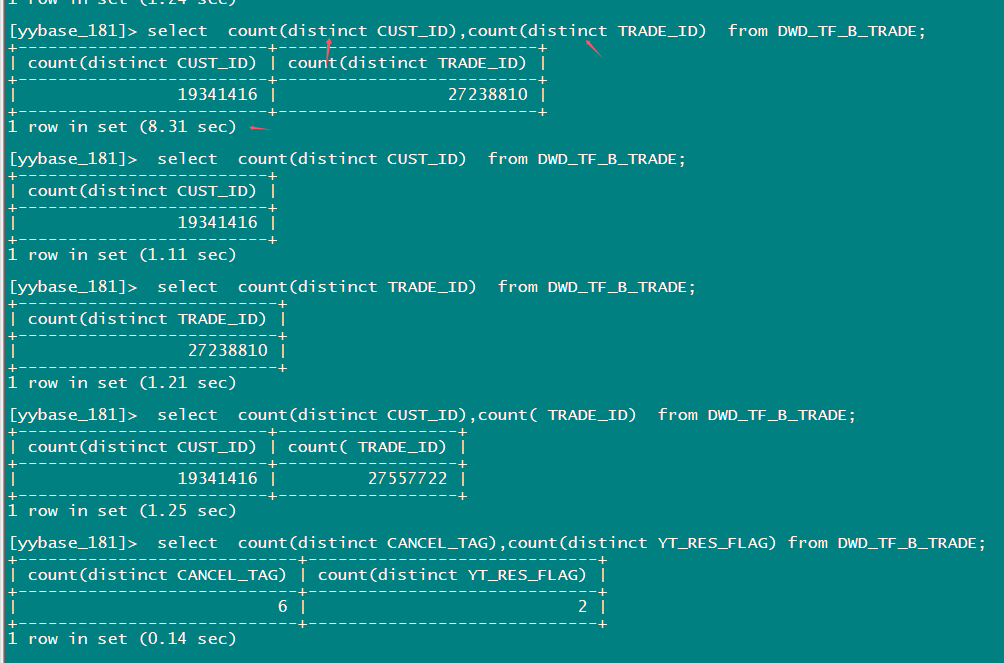
tiflash 32C 2个节点,2700万数据。
问题:
1、 对于id 类 distinct 较高的列 ,为什么增加一个count(distinct ) 后执行时间变的那么长 要8秒多。 2个列单独执行很快只有1秒多,假设处理时2个列可以单独处理,就算是查询2个列的sql 在计算时串行执行 也应该也只要3-4秒才对?
2、ExchangeReceiver_24 这个算子后面显示的thread:32 ,而下面的算子threads都是64, 为什么到接收时threads减了一半,这个受哪里控制。
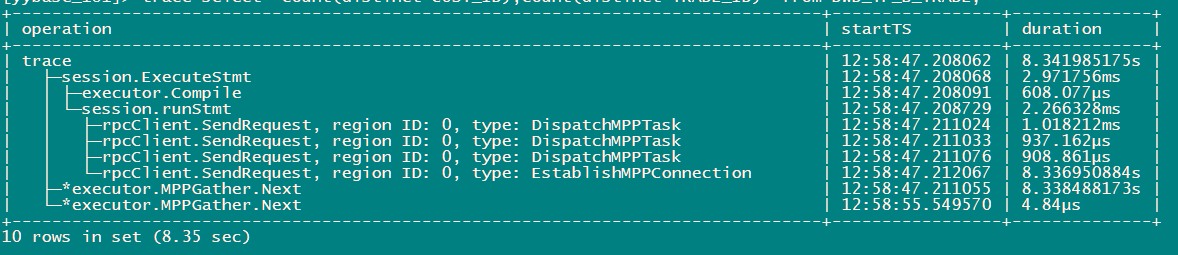
3、从ExchangeReceiver_24 算子往上 记录的时间都是 8.46s , 从该算子和下面的执行时间看 这个执行时间 和算子的父子关系间不是一个包含的关系,也就是说 独立计算的每个算子的执行时间。 而往上的算子 看着似乎又是一个包含关系的时间,且大部分都是位于tiflash侧的时间,这个应该怎样解读时间才正确。 HashAgg_22 的8.46秒怎样判断本身计算花费的时间多还是底层mmp处理的时间多?
那条八秒的 sql 能不能通过日志确认一下是不是触发到了 spill?
速度慢我怀疑是因为两个 distinct 的查询优化器没有选择三阶段 agg ,而是选择了两阶段 agg 。这意味着第一阶段会针对 cust_id 和 trade_id 做分组,然后将所有数据发送给一个 TiFlash 阶段做第二阶段的 agg 。这应该也是为什么第二阶段 agg 线程只有 32 的原因。(这个猜测可以通过 看下 ExchangeSender_23 是否是 PassThrough 确认)
另外为啥单独跑 count distinct 快,我猜测是因为单独跑的时候选择了三阶段 agg ,可以通过 explain 看下是否是这样
2 个赞
h5n1
(H5n1)
5
explain.txt (23.8 KB)
@ guo-shaoge
从执行计划看 1个distinct的sql 里有3个 hashagg
h5n1
(H5n1)
6
grep spill 了一下,麻烦看下是这个信息吗
spill.log (146.7 KB)
刚才看了一下文档,tiflash 的配置默认是不 spill 的,如果没有特意配置过,这条 sql 里面 spill 应该不会发生。
多个 count distinct 的计划由开关 tidb_opt_enable_three_stage_multi_distinct_agg 控制,目前默认关闭。所以没有选择三阶段 agg,所以性能不如两个单独跑的 distinct agg
1 个赞
h5n1
(H5n1)
9
这个打开后 确实快了 ,建议打开吗 ? 关于三阶段聚合 我看官网也没具体的文章介绍,这个能在哪学习下
kang
11
当增加一个count(distinct) 时,执行时间变长的可能是查询优化器没有选择三阶段聚合(three-stage aggregation),而是选择了两阶段聚合。这意味着第一阶段会针对cust_id 和trade_id 做分组,然后将所有数据发送给一个TiFlash阶段做第二阶段的聚合。
h5n1
(H5n1)
关闭
12
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。