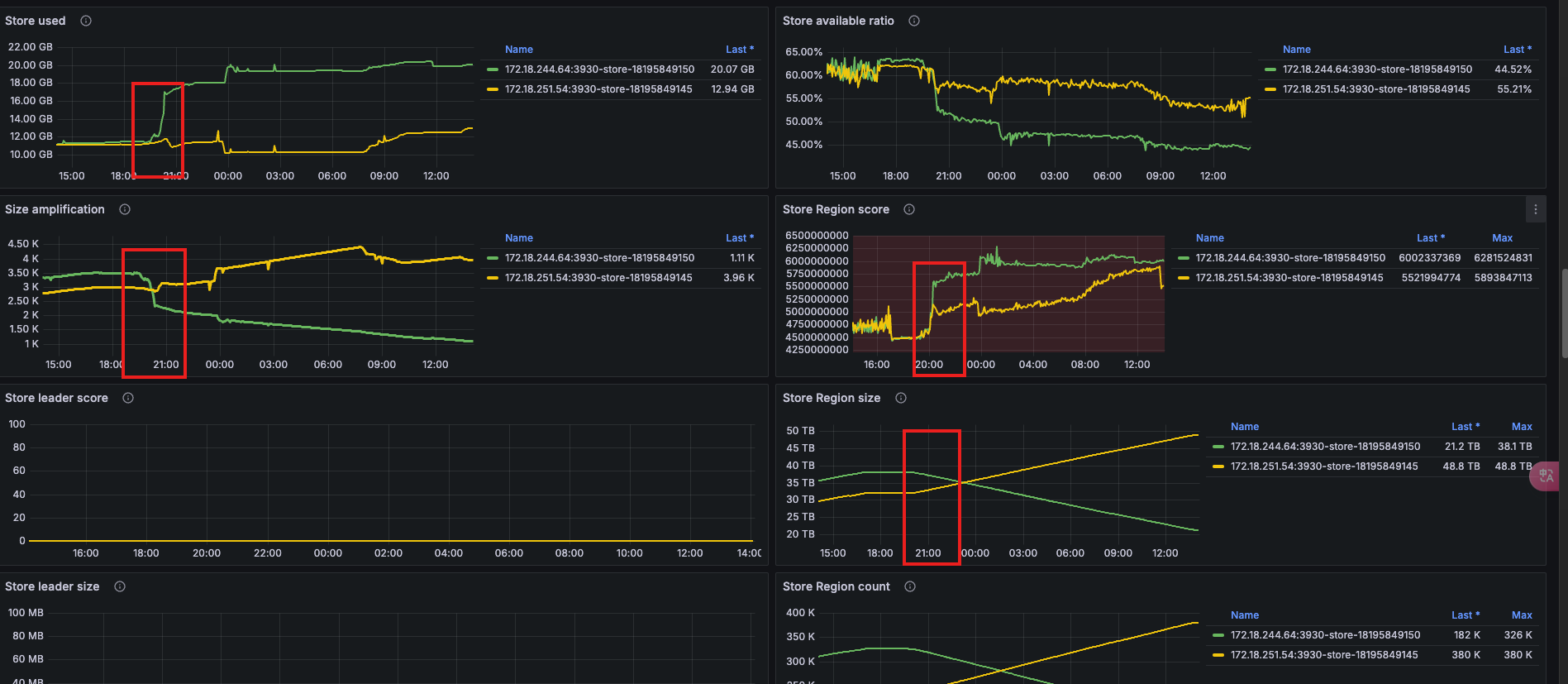
可以看到,昨天 20点之后,两台机器的 Score 得分开始不一样, store-18195849145 的Score 还是变低。从Local磁盘大小来说确实store-18195849145 的使用量更少,但是实际上 Remote 的数据,store-18195849150已经远远比store-18195849145更少了,还一直在进行 balance 从18195849150到18195849145搬移数据.
1 个赞
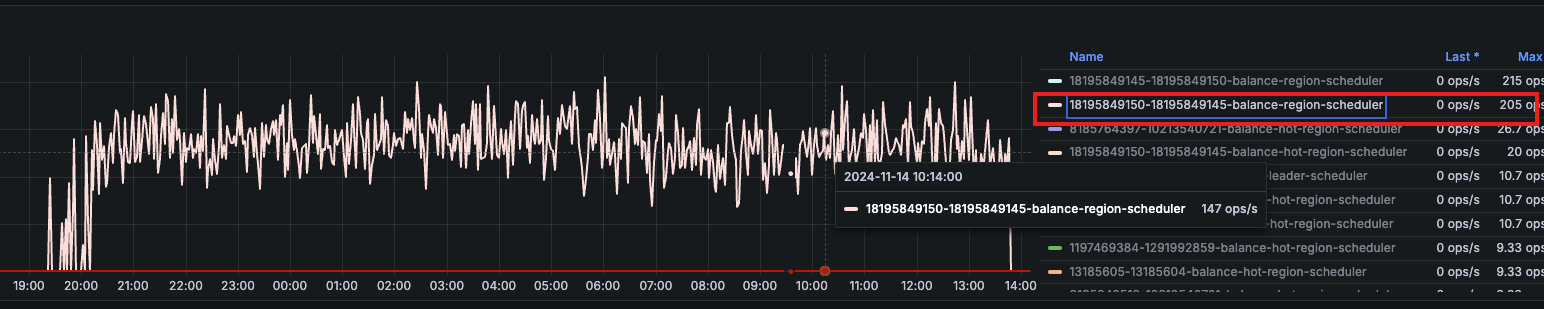
这里贴一下群里的反馈总结:
- 为什么会导致分布倾斜?
PD 目前没有对象存储使用量的上报口。如果 tiflash 把对象存储的使用量当作 used size 上报,当对象存储的存储量接近本地盘容量的话,会导致 PD 停止调度 region 到那个 store 上。无法达到减少 write node 硬件成本的目的。
目前 write node 上报的 store 的使用量按照本地盘算,确实可能会导致调度不均衡。 - 最终会达到稳态么?
TiFlash 的数据分为 Delta 层(新写入的小数据块)和 Stable 层。Delta 层的数据写入后累积达到阈值(一般 100w 行左右)会 Compact 为 Stable 层。Delta 层的数据也会上传 S3,但是本地数据需要等 Compact 为 Stable 层的时候才会清理。Stable 层的数据在上传 S3 之后会清理本地数据。本地的 delta 数据涨到一定程度后,维持在一个稳定的位置。
也就是如果数据一直都有大量写入,最终两者会是均衡的,但是如果两者写入速度有差异,一个先写完,另外一个写的比较慢,两者 Local 盘数据量有差异,就会导致这个差异一直存在,两者永远不会均衡。
解决方案:
设置两个 tiflash write node,并且表的 tiflash 副本也设置为 2 副本,并且设置 LOCATION LABELS。
alter database db_name.table_name set tiflash replica 2 LOCATION LABELS "host";
- 优点: 既能保证数据不倾斜,也可以保证高可用,在滚动重启 Write Node 时不会引起业务查询报错
- 缺点: 内存使用量翻倍,Remote 存储容量也会翻倍,成本更高。
2 个赞
这里再补充一下,还有个前提条件,需要对 Write Node 设置Labels,否则 LOCATION LABELS 并不会生效。只有设置了不同的 Labels,才能真正保证同一个 Region 的两个副本一定分散到两个节点上。
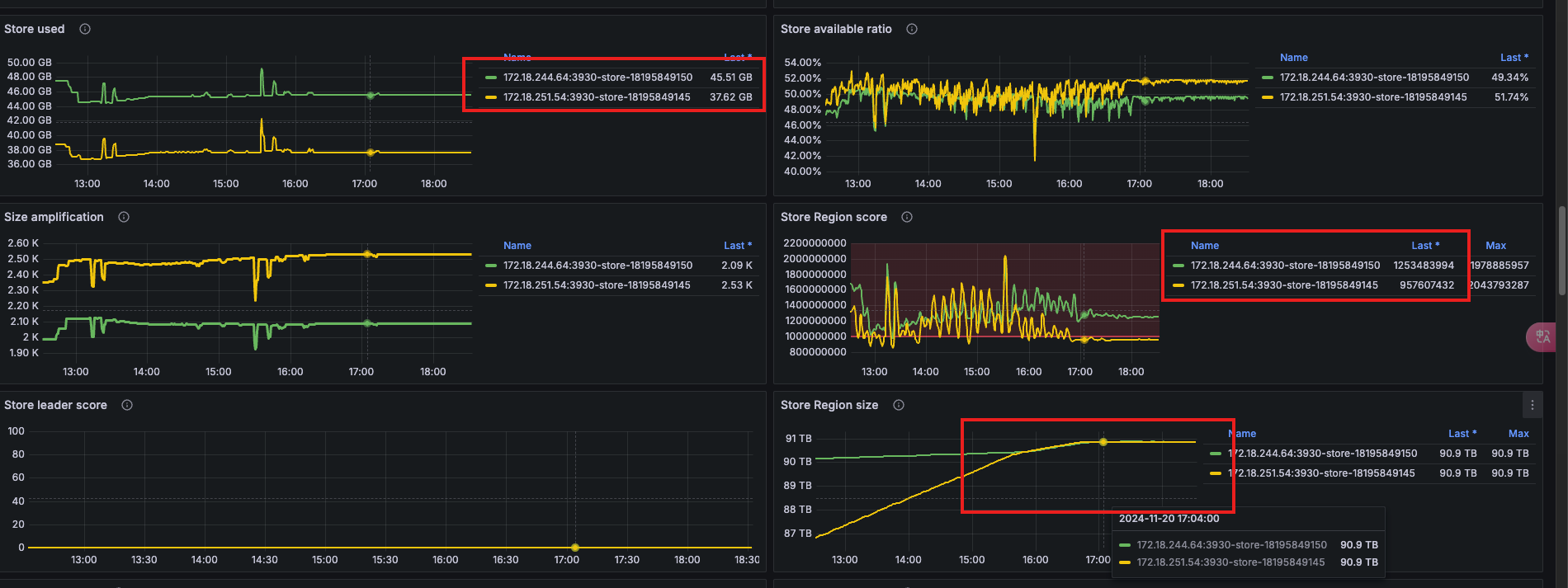
最终效果如下:虽然两个 Write 节点的 Store Score 还是不一样,但是 Region 是平均分配的。
1 个赞
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。