晓峰008
2024 年10 月 21 日 01:24
1
【 TiDB 使用环境】生产环境http://xx.2:2379 operator add remove-peer 786763068 147http://xx.2:2379 operator add remove-peer 786763068 146http://xx.2:2379 operator add remove-peer 786763068 155
– 不成功失败http://xx.2:2379 operator add remove-peer 786763068 8http://xx.2:2379 operator remove 786763068
– 3,重启tikv,参照:https://ztn.feishu.cn/wiki/wikcnSEPzpX1PrZRyBLeFtVOwfb
– 3,核实启动情况
– 4,发现xx.8还是down,做了scale-in下线操作
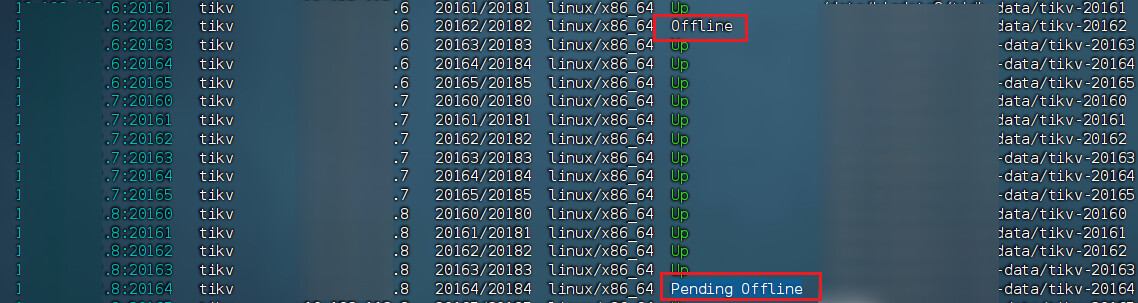
【遇到的问题:】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
Region 不过自己出问题的,除非环境发生异常变化和不合规操作导致。梳理一下问题,当前问题看起来 2 TiKV 手动下线过程中,可能有其他 region 故障导致无法下线问题?可以看一下 TiKV 日志中的报错 region id 并检查 region group 状态是否正常,有没有副本丢失情况。
有猫万事足
2024 年10 月 21 日 02:58
3
xx.6:20162 kv节点
这个节点的storeid 是多少?
本来就坏了一个tikv,然后你上来第一步就要删除这个region 786763068的副本,可能直接把这个xx.6:20162上的副本删掉了。3个副本丢两个,raft组就不可用了。xx.6:20162也就offline了。
小龙虾爱大龙虾
2024 年10 月 21 日 03:33
4
TiDB 宕机时间再长也不会这样的,你不各种强制删除就不会有问题,底层有机制保证 Region 元数据正确的,TiDB 集群能自动判断哪个 Region 是更新的,老旧的无用的 Region 会由 TiDB 自动的删除。参考:TiKV 源码解析系列文章(二十)Region Split 源码解析 | PingCAP 平凯星辰
1 个赞
晓峰008
2024 年10 月 21 日 03:35
5
1,store id这边删除了145,146和147这3个。这3个要怎么进行定位他是在哪个region或tikv上。http://xx.2:2379 region down-peer和pending-peer可以查询出很多数据
晓峰008
2024 年10 月 21 日 03:37
6
报错的region id已确认。目前为786763068这个id。如下:ctl: /root/.tiup/components/ctl/v4.0.7/ctl pd -u http://xx.2:2379 region 786763068
@晓峰008 参考一下楼上的建议,另外如果是调度比较慢,可以通过调整 PD 的 scheduler region 和 leader 调度加速处理一下。
https://docs.pingcap.com/zh/tidb/stable/pd-control#根据副本数过滤-region
1 个赞
晓峰008
2024 年10 月 21 日 03:43
8
好的。昨天同步做了调度上面的加速,不知到过不过。http://xx.2:2379 config set leader-schedule-limit 240http://xx.2:2379 config set region-schedule-limit 720http://xx.2:2379 config set replica-schedule-limit 384
晓峰008:
好的。昨天同步做了调度上面的加速,不知到过不过。
调整以后,region 的调度速度加快了吗?现在 offline 的 region count 还剩下多少?另外读写影响角度是什么样的 ?
晓峰008
2024 年10 月 21 日 03:56
10
1,速度有快些。但整体没有降很多。原先是750G,现在660G左右。读写影响不大。本身磁盘全是固态盘。现在继续给大参数?http://xx.2:2379 region --jq=“.regions
晓峰008
2024 年10 月 21 日 04:03
12
1,region count这个指令要怎么调用计算呢
晓峰008
2024 年10 月 21 日 04:10
14
1,上面的结果筛选副本数不等3的,还有9个region id。昨天排查的异常region 786763068 由1副本变为3副本了
图中Status中的Up|L的就代表是leader对吧
3,调度的数量,同步增加10倍
– 由240调整为2400
tiup ctl:v4.0.7 pd -u
http://xx.2:2379 config set leader-schedule-limit 2400
– 由720调整到7200
tiup ctl:v4.0.7 pd -u
http://xx.2:2379 config set region-schedule-limit 7200
– 由384调整到3840
tiup ctl:v4.0.7 pd -u
http://xx.2:2379 config set replica-schedule-limit 3840
1 个赞
晓峰008
2024 年10 月 21 日 05:36
15
pd leader日志通过哪些关键字查询pending offline信息呢
system
2024 年10 月 28 日 05:37
16
此话题已在最后回复的 7 天后被自动关闭。不再允许新回复。