几个T手工compact估计得跑几天
1 个赞
那估计就是GC的问题,逻辑删了,但是数据还在,要等数据GC了,才会显示region为空,进而合并region。
参考楼上大佬操作一下吧。
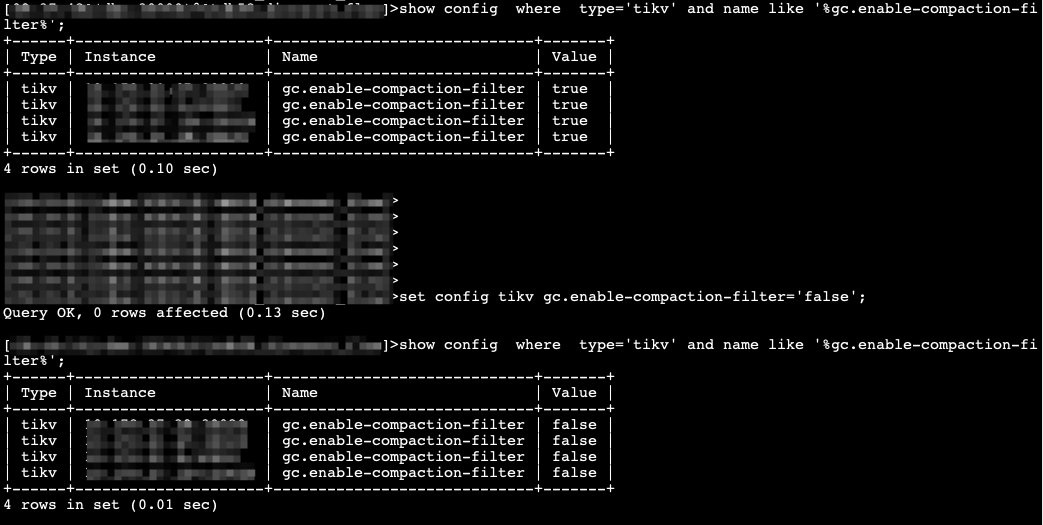
即使实际的数据量少的话,也需要几天吗? ![]()
![]()
![]()
1这个方法改完了之后不是立刻见效的,是需要等一阵的。过段时间再看看。
能看gc进度吗?或者查看rocksdb中的无效key
grafana里面gc的监控里面找找。
SET GLOBAL tidb_enable_region_merging = 1; – 确保合并功能开启
1 个赞
我个人感觉跟 gc 无关,gc 不掉旧的数据确实可能导致版本过多、查询变慢的问题,但是我理解不会导致 region 过多,单个 region 过小(从存储占用和 region 数量计算出来),又不显示空 region 问题,我记得早期版本是有 region 大小计算不对的问题,但是找不到那个 bug 号了,我现在想法还是增大两个 merge 相关参数,让 region 合并
1 个赞
数据量已经为0了,那再次执行truncate后,查询还会慢?
没这个变量呀
SET GLOBAL tidb_enable_region_merging = 1;
ERROR 1193 (HY000): Unknown system variable ‘tidb_enable_region_merging’

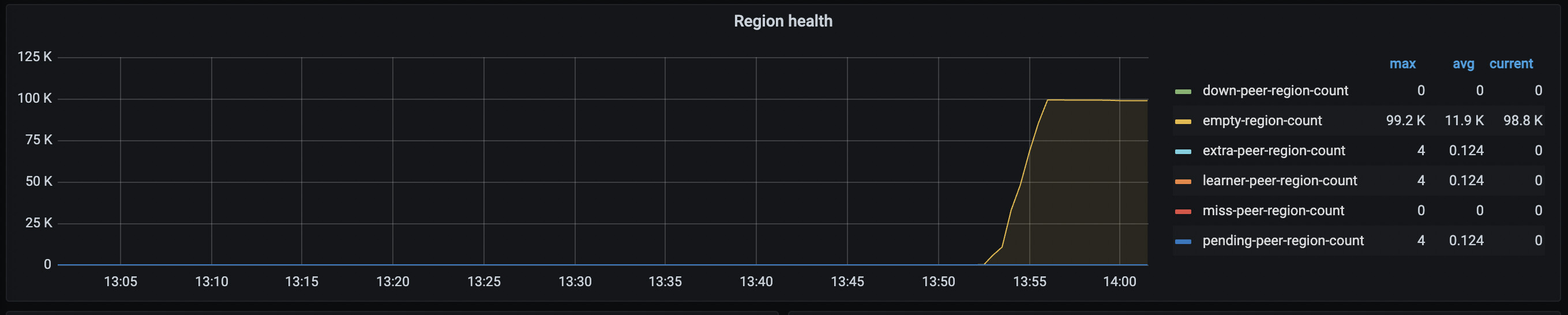
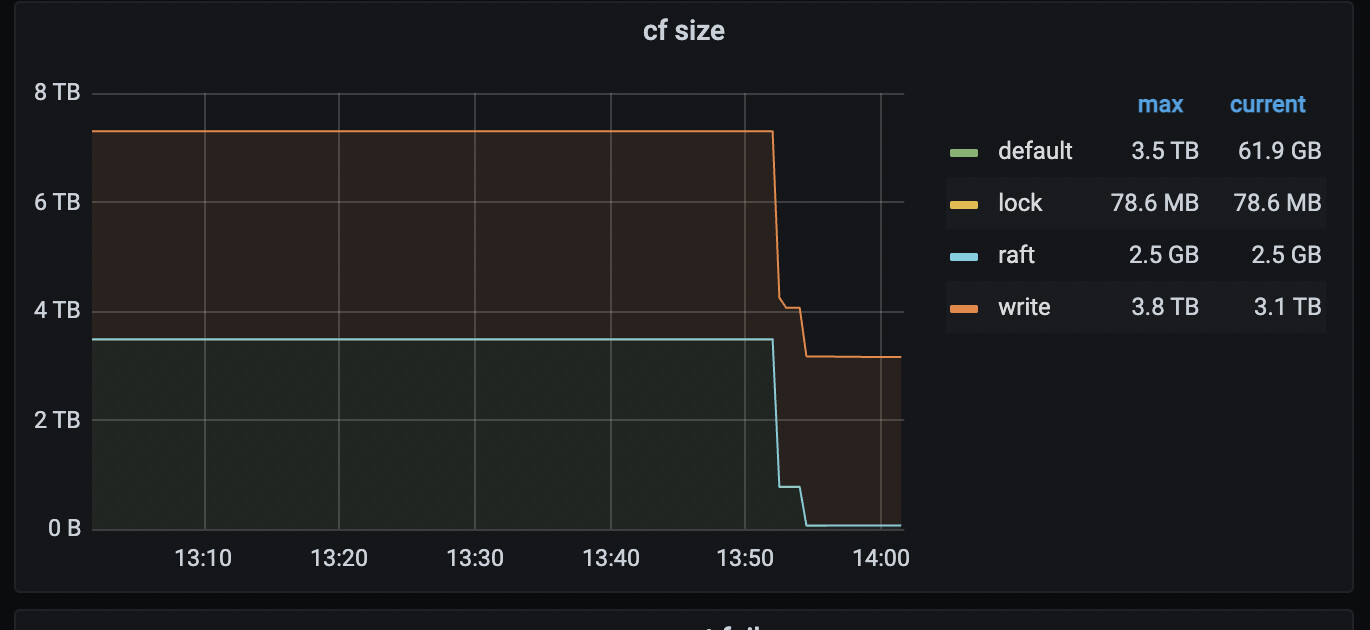
应该就是早期版本的bug问题吧
你这竟然 这么搞???我是保留2年的数据。之前的一直慢慢删,你这只保留一个月数据 太简单了
我其他的只保留一个月的。都是创建一个_2表。让开发在insert源表的时候多写一个sql。insert一个_2表。一个月后。两个表rename。源表直接drop 不更省时省力吗。1个月就行了。
而且大表删除速度比较慢。我这30亿20亿行的数据。2-4T大小,每天只能删除2-3千万数据。
我这边这种用法还是比较普遍的,大表每天写入几千万行数据,每日凌晨删除N天之前的数据,周而复始。沿用的是之前mysql的逻辑。
其实这个场景改成分区表会更好。
对,改成分区很方便,我这办也是能改分区的。_2表我都给他改成分区了,主键开发用的都是UUID ,我给这个UUID加一个日期字段 联合做主键,也不影响。
我现在是除了下班高峰,其他时间一直再删除。10亿以下1T以内的表删除很快。1小时能删除500万。现在大表只剩下3个。都是3T以上的,30亿的。每小时只能删除七八十万。
1. 确认 GC(垃圾回收)设置
TiDB 使用 GC 来清理已经删除的数据。请确认 GC 的配置是否合理。可以用以下命令检查当前的 GC 配置:
sqlCopy Code
SHOW VARIABLES LIKE 'tidb_gc_life_time';
如果 GC 生命周期过长,可以考虑将其调整为更短的时间,以便更快地清理已删除的数据。
2. 手动触发 Region 合并
可以通过手动触发 Region 合并来减少 Region 的数量。使用以下命令:
bashCopy Code
curl -X POST http://{pd-ip}:{pd-port}/pd/api/v1/region-merge
替换 {pd-ip} 和 {pd-port} 为您的 PD 节点的 IP 和端口号。这会请求 PD 合并小的 Region。
3. 调整 Region 的大小
如果数据量较小,可以考虑调整 Region 的大小。通过调整 split-region 参数来改变新 Region 的最大大小。例如:
sqlCopy Code
SET GLOBAL tidb_region_split_size = <new_size>;
将 <new_size> 设置为适合您的表的大小,这样在数据删除后,会更容易进行合并。
4. 查看 Region 状态
使用以下命令检查 Region 的状态和健康状况:
bashCopy Code
./bin/tikv-ctl --db ./data/db region --pd <pd-address>
查看是否有 Region 正常分布,并且没有出现异常情况。
5. 重平衡 Region
可以尝试使用 PD 的重平衡功能,确保数据在所有 TiKV 节点之间均匀分布。可以通过 PD 控制台或 API 执行重平衡操作。
6. 定期维护和优化
定期运行 ANALYZE TABLE 命令以更新统计信息,提高查询性能。此外,可以考虑在数据删除后执行 OPTIMIZE TABLE,这将帮助 TiDB 更好地管理存储结构。
7. 监控和调优
使用监控工具(如 Prometheus + Grafana)观察集群的性能指标,以便识别潜在的瓶颈。