db_user
(Db User)
1
Bug 反馈
清晰准确地描述您发现的问题,提供任何可能复现问题的步骤有助于研发同学及时处理问题
【 TiDB 版本】
v7.5.1
【 Bug 的影响】
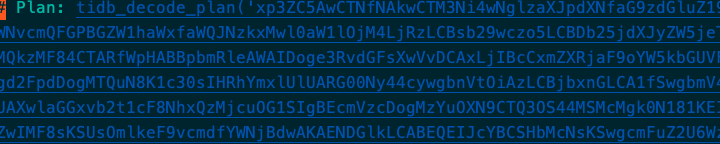
慢日志的plan存储有问题,存储过大,导致无法查询
【可能的问题复现步骤】
【看到的非预期行为】
【期望看到的行为】
【相关组件及具体版本】
【其他背景信息或者截图】
max_allowed_packet已经调整为1G了,但是依旧不够,应该是为了维护plan的格式,导致了这里面的空格字符被放大了无数倍,整体的信息放大了无数倍,不清楚该如何规避
db_user
(Db User)
2
sql确实是个很长的sql,但是是in了一堆值,不太清楚为什么plan会如此长
dashboard上也能看执行计划,看看能否显示这条语句的执行计划
db_user
(Db User)
6
慢日志能直接查,但是dashboard没法看了,而且日志里直接是物理计划了,太长了
大概率是因为分区表
我们曾经有过线上 SQL 因为分区表拉到的执行计划超过 6M 的情况
db_user
(Db User)
8
这个也不是分区表,普通表,只是in的参数很多,执行计划已经超过1个G了
1 个赞
WalterWj
(王军 - PingCAP)
9
这个就是群里说的 in 上百万数量的 sql 么?如果是的话 感觉这执行计划得爆表
db_user
(Db User)
10
没错,就是那个,执行计划爆表了, 报整个集群都拖慢了
WalterWj
(王军 - PingCAP)
11
那这个问题可不算 bug。几百万数据,放内存生产执行计划是枚举的。内存还有放大。。。。
db_user
(Db User)
12
这么看是不算了,但我感觉更想让他像sql记录的那样,对太长的内容有个截取,我改一下标签吧
zhihui
(智慧)
14
慢日志查到的只能是跑完的吧,7以上版本不是这个特性?
zhihui
(智慧)
15
可以从上游的角度上做分批啊,比如说代码,分批执行in的内容呗
db_user
(Db User)
16
确实,那枚举值这种只能无解,这种确实是sql写的有问题,但因为量大写log拖慢了集群也没想到
WalterWj
(王军 - PingCAP)
18
这种 sql 很离谱,这已经不是单纯写 log 了。
之前搞 TiDB 慢查询专项优化的时候看过源码
这个是不能截断的, 因为这数据就是执行计划
操作逻辑就是: 执行计划 => snappy 压缩 => b64 编码
截断后这一列就没有意义了,只能考虑在执行计划层丢弃部分源数据
1 个赞