【 TiDB 使用环境】生产环境
【 TiDB 版本】“version”: “3.0.16”,
【 TiDB 环境】虚机自建tidb,tikv配置:32G16C1000GSSD盘
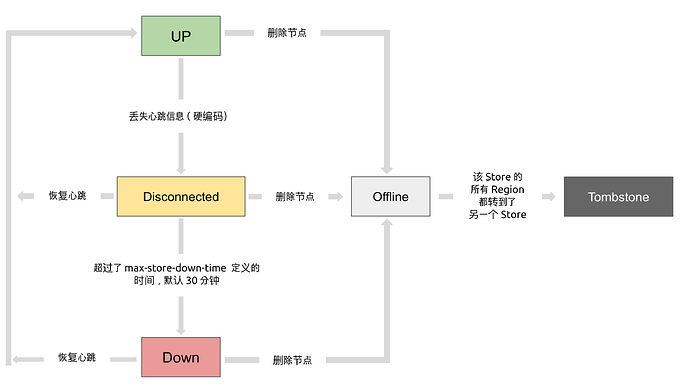
【遇到的问题:问题现象及影响】集群中有两个tikv节点宕机,于是delete了对应的store,但region迁移的很慢,又新加进来一个store,leader-region平衡的也很慢很慢。新加进来的store是会等删除store节点下线了才会快速迁移leader-region么? 或者有什么办法可以将已经下线的两个tikv节点快速彻底踢出去么?求教大神们!
【附件:截图/日志/监控】
这是已经delete状态的两个store
这是新加进来的store
已经修改了两个参数之前是4修改成了8 但速度没有提升
- leader-schedule-limit 调度是用来均衡不同 TiKV 的 leader 数,影响处理查询的负载。
- region-schedule-limit 调度是均衡不同 TiKV 的副本数,影响不同节点的数据量。
还是要先加速region的迁移,把store limit调大一些,测试集群可以调到百万级别,生产集群就调整小一点,万级就行了。删除的store,看看region count是不是在减少,如果是的话就不用管,等待region count变成0就行。如果没有减少,可能需要手动去删除对应的region
store limit 调大就会加快速度。
至于老的下线和新的没关系,俩不掺和
h5n1
(H5n1)
4
除了调整几个Limit参数,增加处理阈值外,加快下线迁移速度最快的方式是手工添加调度,循环多次执行。参考 手动调度 那节的脚本
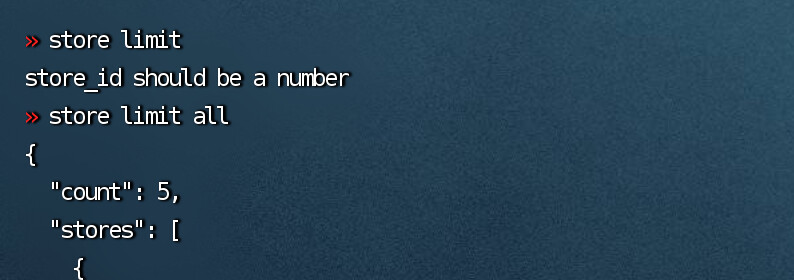
V3.0.16版本不好不能设置storelimit 看不到默认的 设置了也不生效
如果leader region在offline的节点上,应该是会影响查询的
还需要用pd-ctl 修改store limit all xx, 记得最大限制就是200
v6以后的版本有200的限制,v5版本是没有200限制的
哦哦,感觉设置到200后,恢复的速度每秒能到300mb+,这个速度其实很快了