tidb 6.1.7
架构 pd *3,tidb *3,tikv *3,grafana,prometheus,alertmanager
背景:集群已经开启悲观事务模型,且业务的insert操作是显示事务(非自动提交),但是会频繁delete,insert后马上delete,所以目标表记录数较少不超过十行,集群gc时间为24h,后来改成2h没有明显的改善。
现象:【事务消息表】的简单的insert(单value的insert)操作在prewrite阶段耗时几百毫秒。


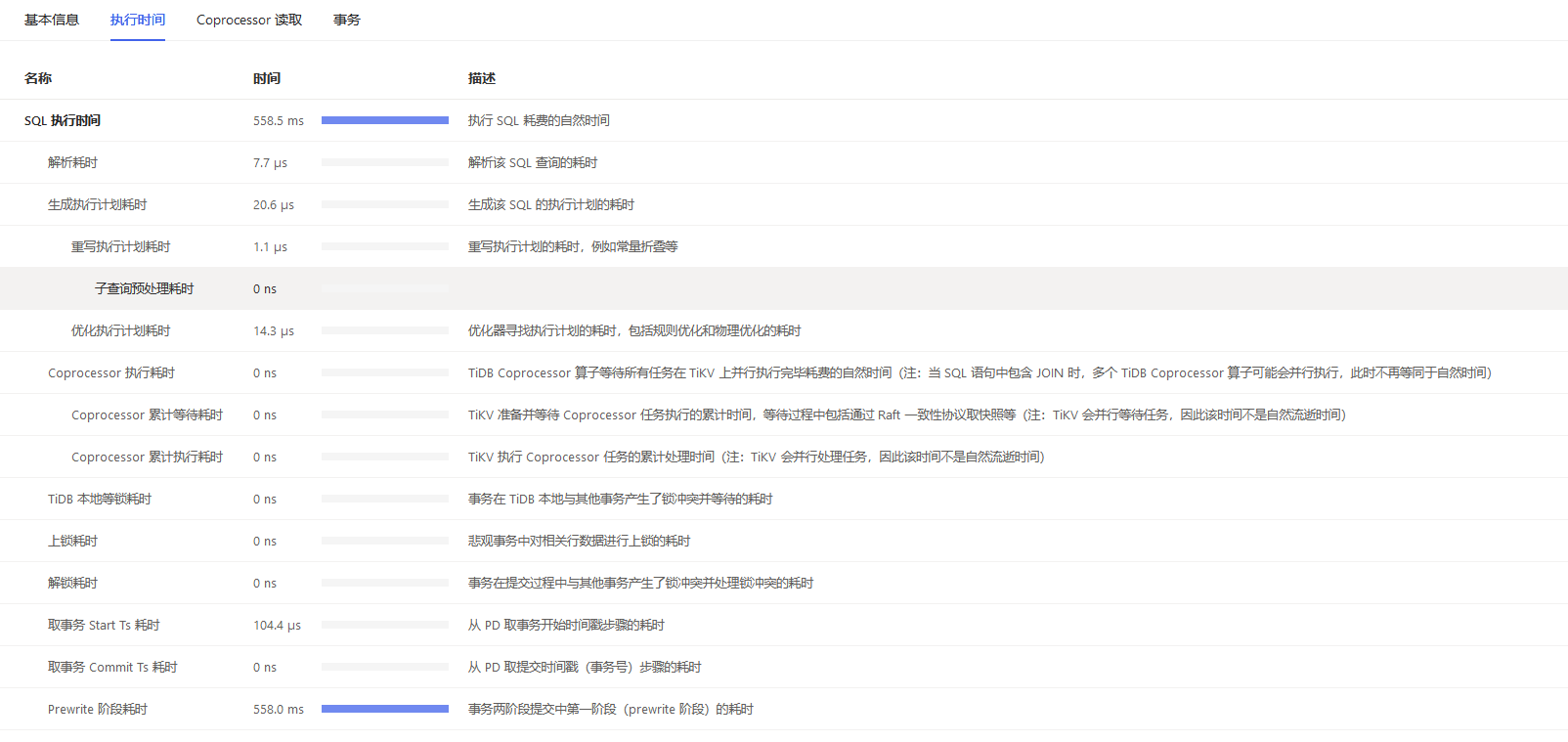
同表查询操作也较慢,全表count一下需要近400毫秒
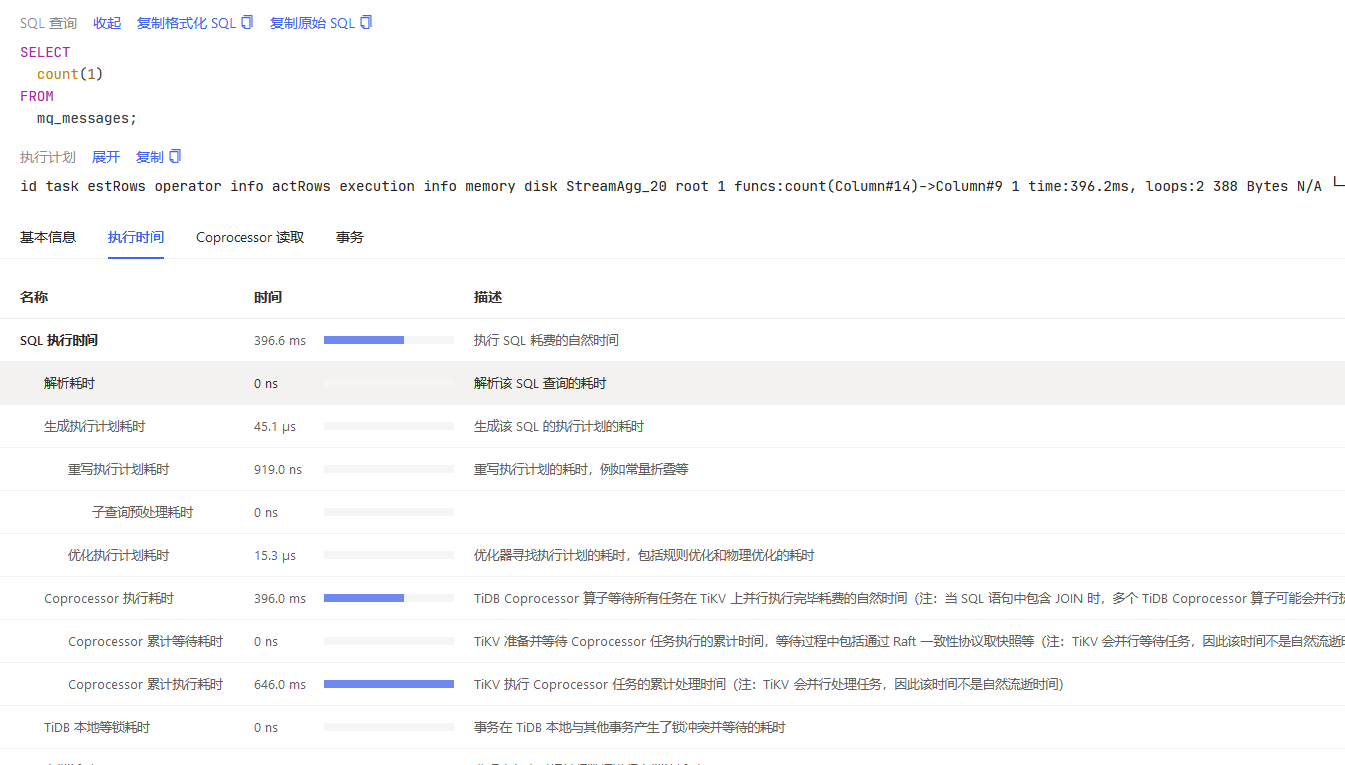
id task estRows operator info actRows execution info memory disk
StreamAgg_20 root 1 funcs:count(Column#14)->Column#9 1 time:396.2ms, loops:2 388 Bytes N/A
└─IndexReader_21 root 1 index:StreamAgg_8 0 time:396.2ms, loops:1, cop_task: {num: 25, max: 395.4ms, min: 266.5µs, avg: 26.3ms, p95: 252.1ms, tot_proc: 646ms, rpc_num: 25, rpc_time: 656.6ms, copr_cache_hit_ratio: 0.92} 1.05 KB N/A
└─StreamAgg_8 cop[tikv] 1 funcs:count(1)->Column#14 0 tikv_task:{proc max:438ms, min:125ms, p80:340ms, p95:400ms, iters:25, tasks:25}, scan_detail: {total_process_keys: 0, total_process_keys_size: 0, total_keys: 2351547, rocksdb: {delete_skipped_count: 25152, key_skipped_count: 2392165, block: {cache_hit_count: 1402, read_count: 0, read_byte: 0 Bytes}}} N/A N/A
└─IndexFullScan_19 cop[tikv] 142 table:mq_messages, index:idx_create_time(create_time), keep order:false, stats:pseudo 0 tikv_task:{proc max:438ms, min:125ms, p80:340ms, p95:400ms, iters:25, tasks:25} N/A N/A
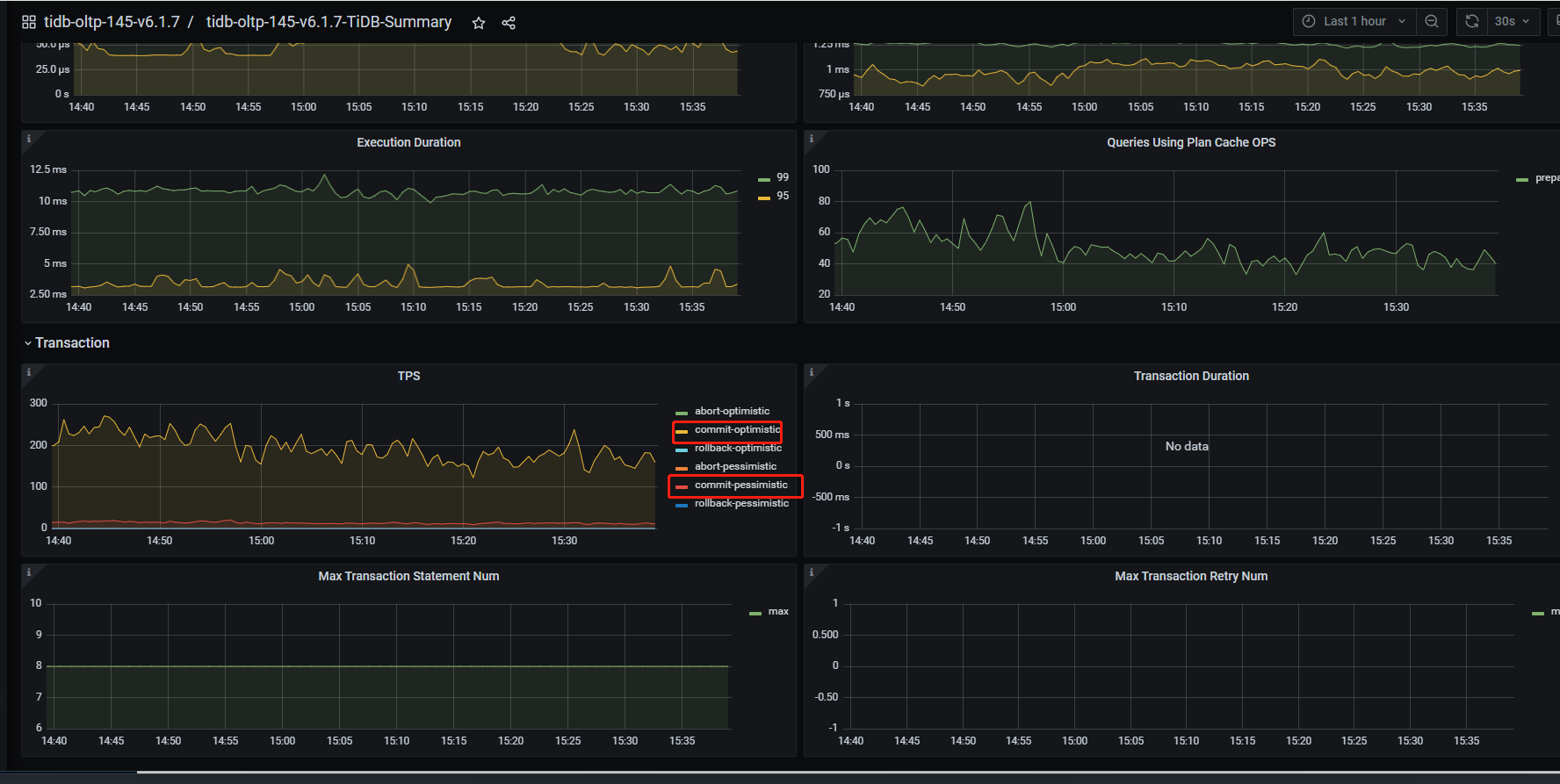
目标集群tps也较低
三个tikv节点io相应时间如下
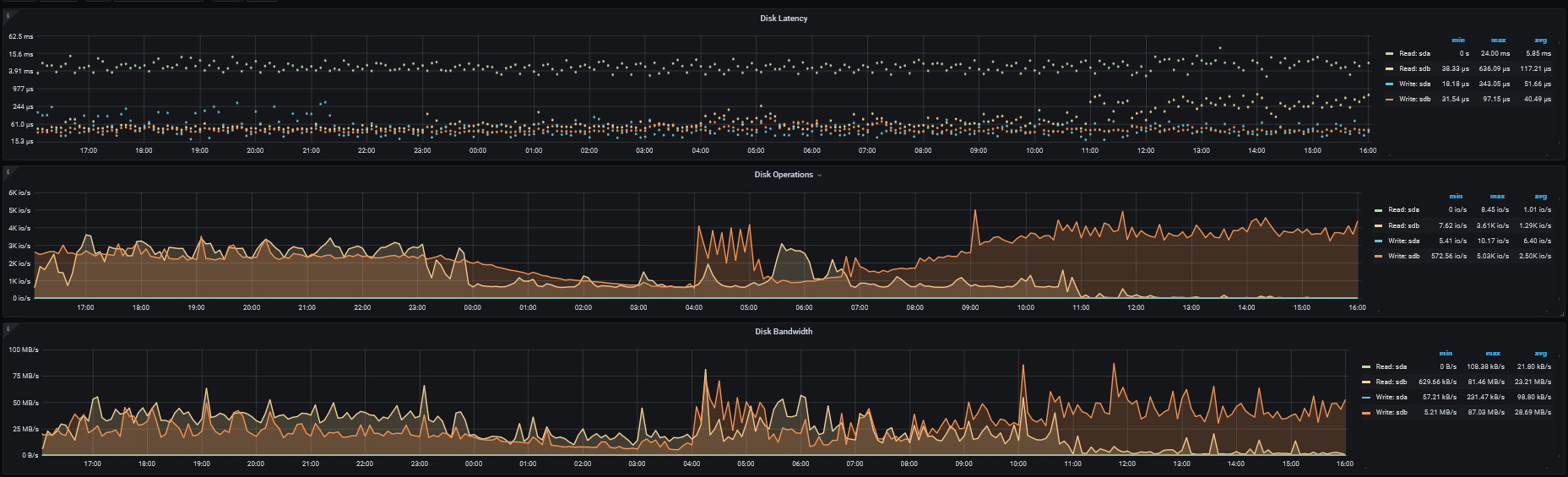
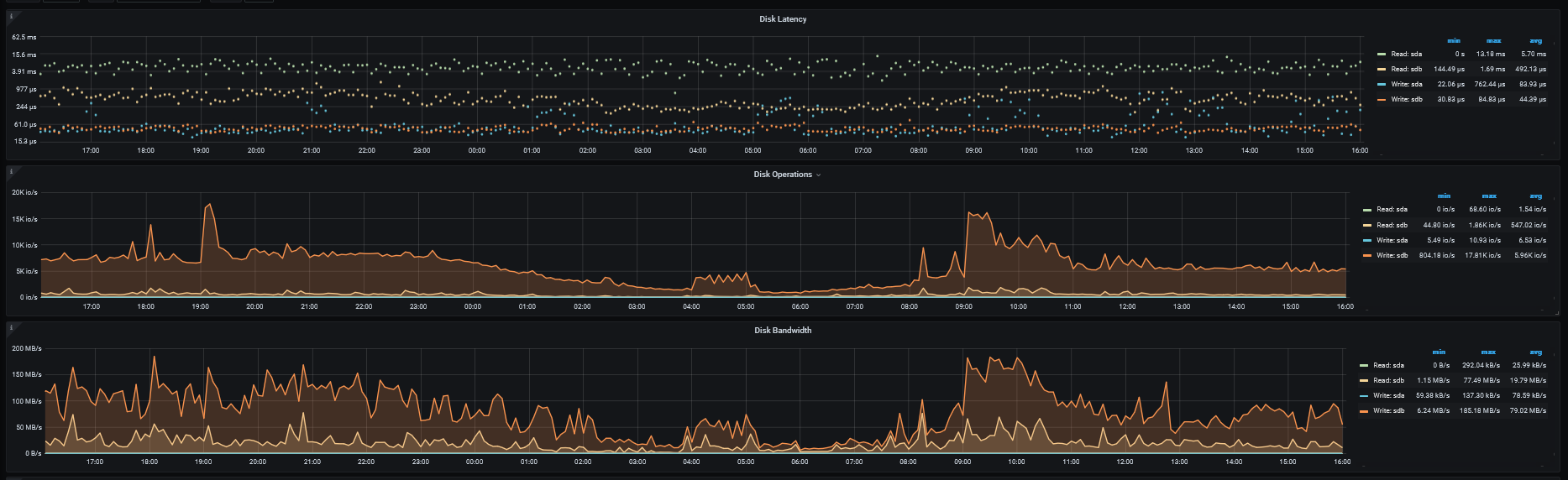
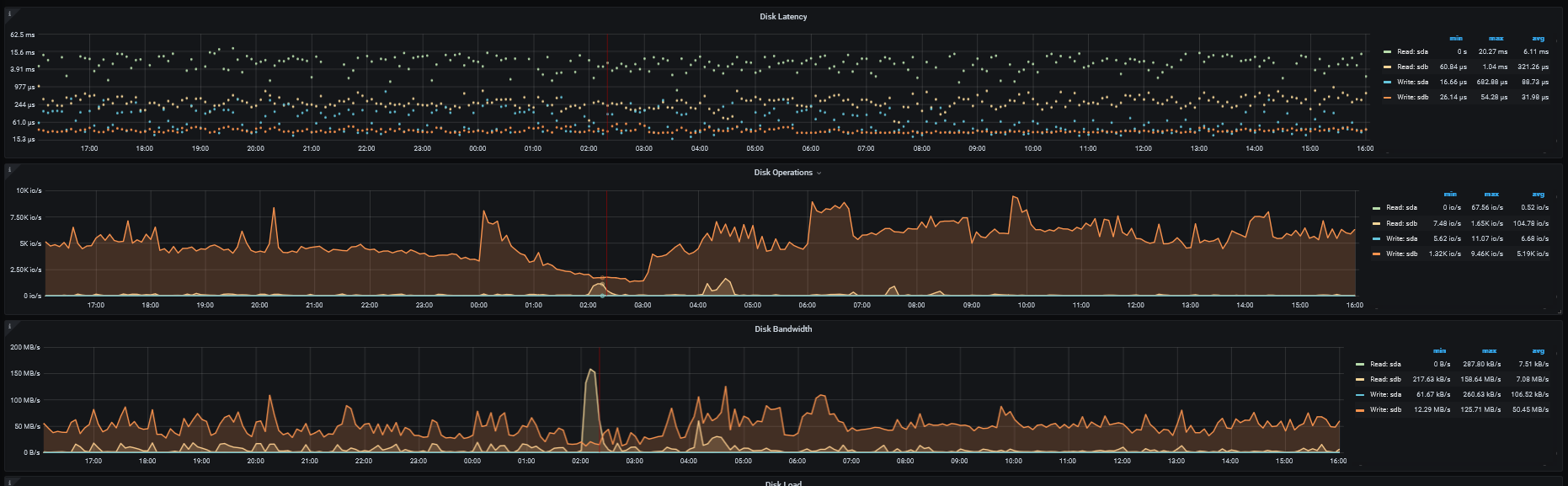
集群的cpu负载都不高,48c的机器,最高不超过30

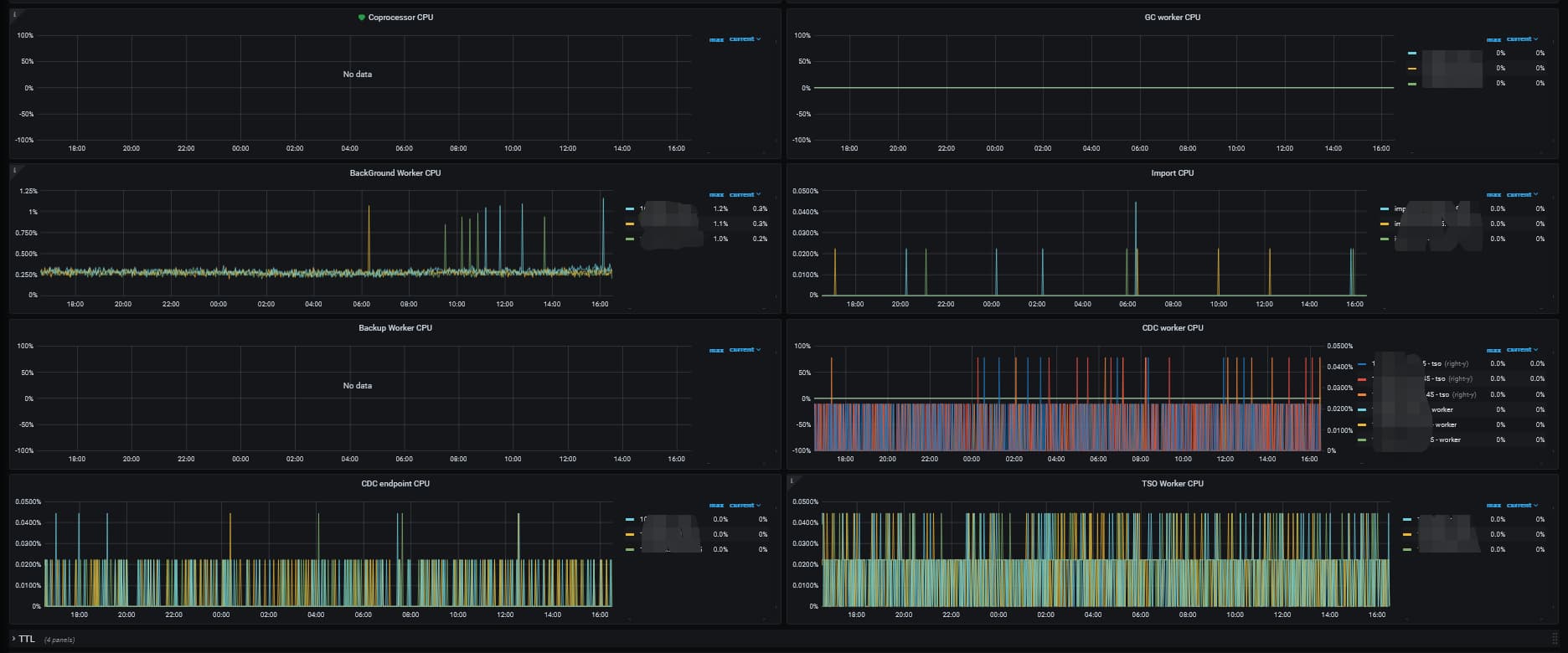
tikv-detail-thread-cpu监控面板