最近要做一些基于 TiDB 数据库的测试,需要搭建一套基于 TiDB 的主从集群容灾架构,使用 3+3 共 6 个节点的虚拟机环境,即每套 TiDB 集群使用 3 个节点的混合部署方案。
从开始部署到部署完成,总共花费 1 分钟左右,我部署完成了 2 套 TiDB 集群,相当于一套集群的部署花费约 5 分钟的时间(两套集群是先后部署,并非并行部署)。部署完成后,我同事惊讶于这效率,他才刚去楼下抽完一根烟。。
典型案例:某基于postgresql底座的国产数据库安装部署—约 2 小时
跟着唐总部署pg的时候。他总骂我笨。这怪我吗?怪pg。软件难用不能怪人。
tidb的性能需要磁盘支持
但公司费用需要我们降本增效
那怎么最大化tidb的性能呢
评估业务是ap业务还是tp业务。
如果公司给30000 你得把15000元用在磁盘的性能上
tidb是计算和存储分离的产品。tidb中计算是tidb组件负责。但tikv也负责计算。并且tikv还负责存储。调度数据。所以tikv的性能需要比tidb大很多。建议tidb4核心的话tikv得配置16核心。因为tikv的cpu部分还负责下发计算的工作,磁盘还需要调度也需要cpu参与,一般io会默认占用0线程和1线程。
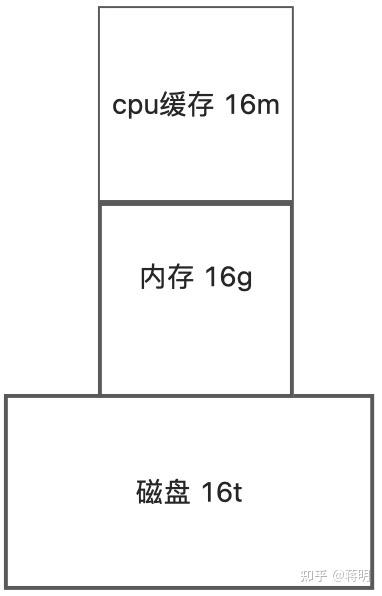
在功能上,我们可以把内存条看成一个连接CPU与硬盘的“中介”。
比如我们打开Photoshop这款软件,首先是内存从硬盘中读取Photoshop这款软件的文件,写入到硬盘当中。因为内存的读写速度要比硬盘快的多,所以CPU会跟内存进行数据的交换,而不是跟硬盘进行数据交换。

2.3 速度上的区别
下图是同一台电脑硬盘跟内存的读写速度跑分图,图上可以看到内存的读写性能是硬盘的二三十倍。
(作图为硬盘跑分,右图为内存跑分)

所以在tidb设计中也需要加大中介的带宽。
在功能上,我们可以把带宽看成一个连接CPU与硬盘的“中介”。
比如我们打开Photoshop这款软件,首先是内存从硬盘中读取Photoshop这款软件的文件,写入到硬盘当中。因为内存的读写速度要比硬盘快的多,所以CPU会跟内存进行数据的交换,而不是跟硬盘进行数据交换。

2.3 速度上的区别
云上不同的磁盘性能是不一样的。
gp3默认100m。读写只有16m 价格便宜
hhd盘默认读写500m。如果遇到顺序读写性能会比gp3的性能还要好。
io1默认1000m上 按量付费价格最贵。 企业从成本考虑很少会选择这个磁盘。
那如何又不花钱又得到最好的性能呢。
你可以无限制的增加tikv的数量。12个tikv性能会好很多。哪怕每个带宽是10m。总性能也会突破1200m。真正做到了不花钱提升tidb的性能。
你可以单个kv选择2核心32g内存的类型。努力选择大内存的缓存。这样会抵消tikv磁盘带宽性能差带来的损失。
计算机架构上,万能用到缓存,缓存大则性能好。磁盘io再好,也没内存性能好。整套tidb集群内存突破了12*32g=356g内存。而mysql 同样的价格因为rds费用比ec2价格贵三倍。怎么买都只能买到128g内存
从内存性能自然差3三倍。
再叠加网络带宽的影响。带宽差12倍。这也是tidb慢慢替代mysql的原因之一。

这时候同事说了 你这需要部署几百台机器需要人力成本。
我给他祭出tidb的自动扩容。
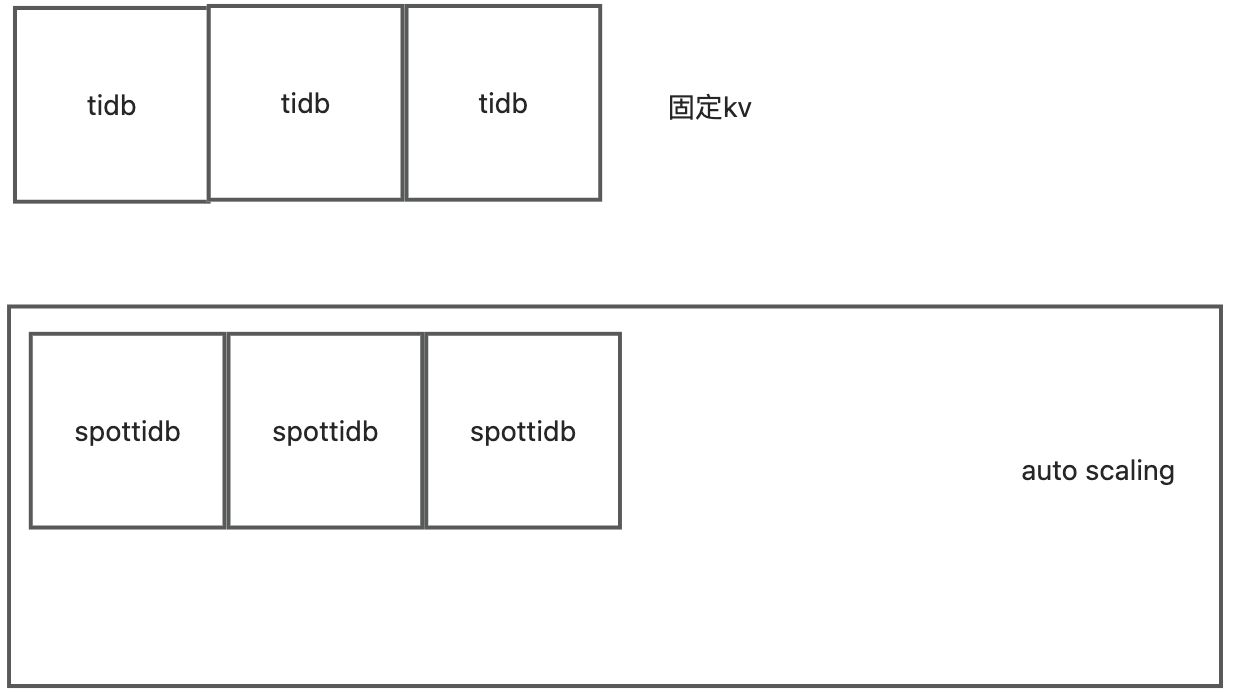
tidb的计算自动扩容
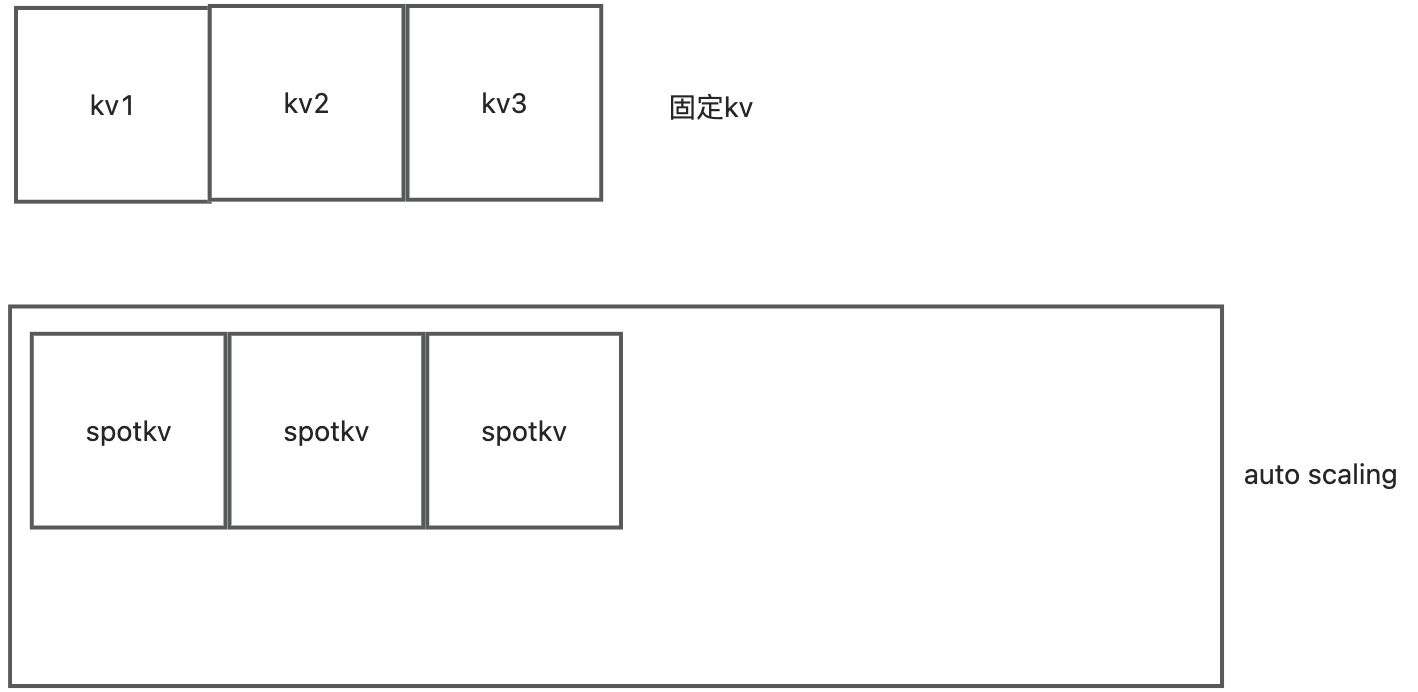
tikv的存储自动扩容
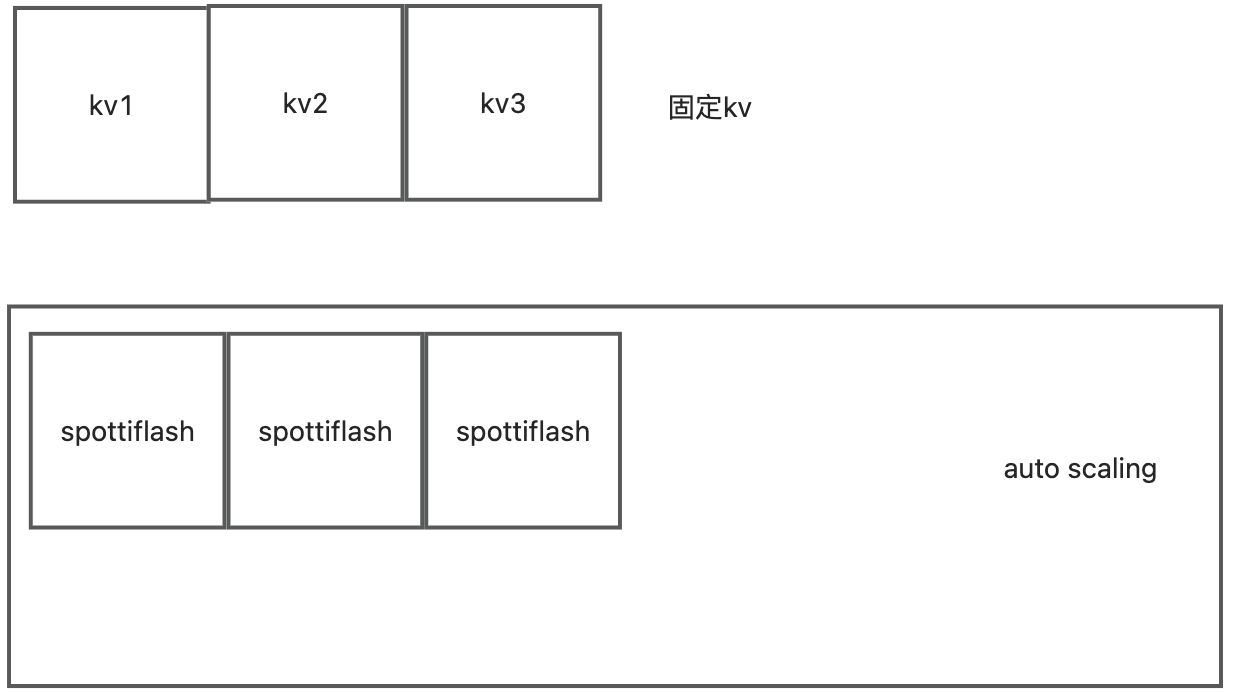
tiflash的大数据自动扩容
今天我实现了个人版本的serverless。
云原生架构上最基本的就是硬件可编程和硬件可改造。
让我们来看pingcap的文章
每年我都有一个时间会特别激动,就是产品大版本发布的时候,通常也是社区年度技术大会 TiDB DevCon 举办的时间。去年 TiDB DevCon 2019,我们发布了 TiDB 3.0 Beta,当然今年 TiDB 4.0 GA 也如约而至。

Serverless
很长一段时间 TiDB 用户使用的集群规模都很大,然后就会再提出一个诉求说“怎么降低我的使用成本”。TiDB 4.0 拥有了 Serverless 能力之后,会根据用户的实际业务负载,基于 K8s 自动做弹性伸缩。
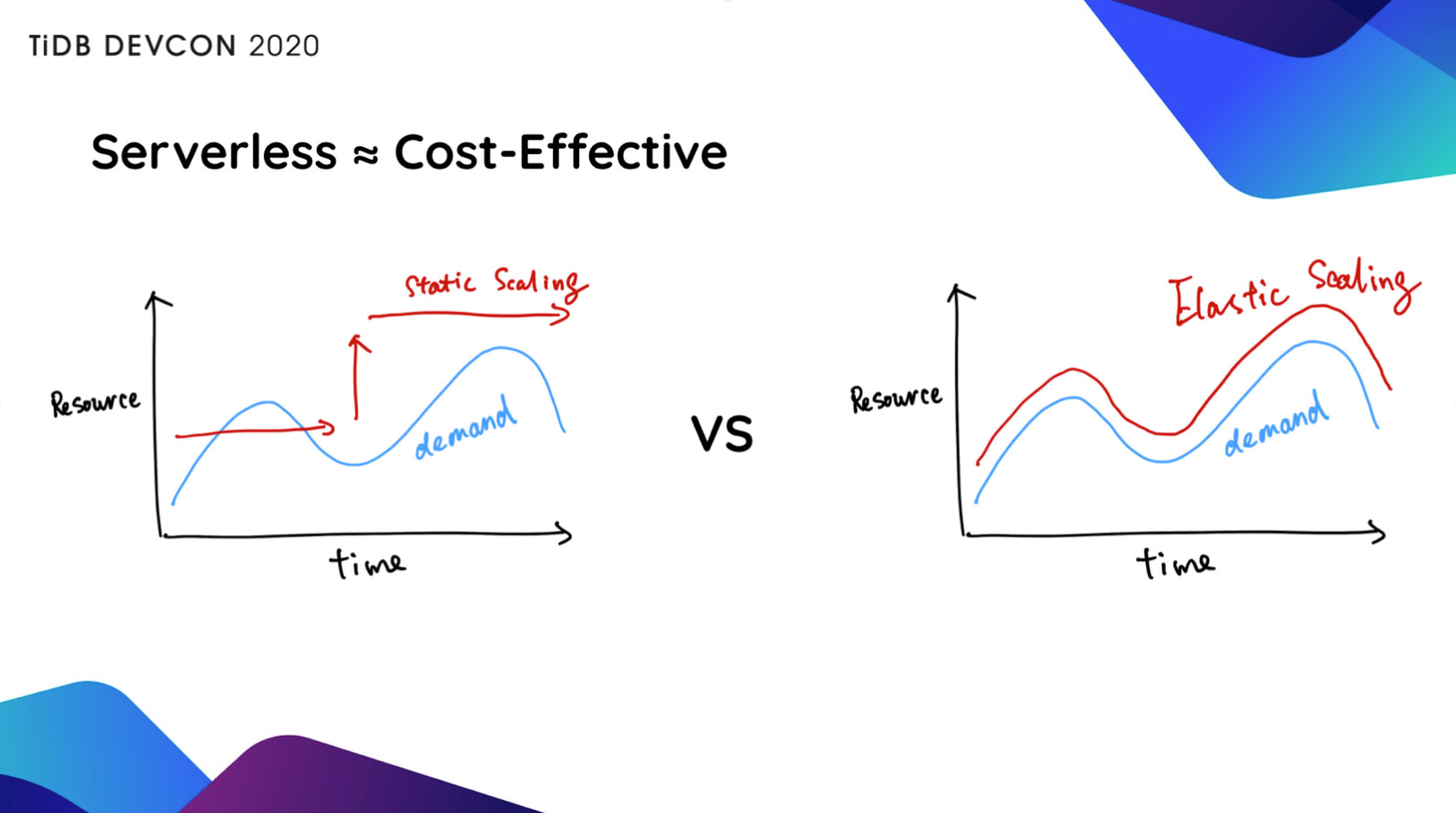
从前,当我们在上线一个系统的时候,第一件事就是 Capacity Planning,去评估一下我们大概需要多少台服务器,比如提前准备了 50 台,但是实际上线之后跑了一个月,发现 5 台机器就够了。这就导致了大量的资源浪费。如果整个系统能够在云上全自动弹性伸缩,就能避免这种资源浪费。
更重要的是,TiDB 的弹性伸缩,意味着你永远不需要按照业务的峰值配备系统资源 。比如大家的业务会有早、晚两个明显的高峰,但实际上每个高峰持续时间通常只有 2 个小时左右,也就是说,为了这 4 个小时的高峰,而我们配置了 24 小时的最高资源配置,并为此付费,但非高峰时间的资源和成本完全是可以节省的,可能算下来,我们能够节省的成本大概在 70% 左右,甚至更高。

另外,能够弹性伸缩的 TiDB 可以应对无法预测的 Workload,没有人知道哪一个商品在什么时候会大卖,没有人知道我卖的哪一个基金在什么时候会火,这时如果我们给系统一个权限,让它能够自动根据业务当前的实际情况,扩充服务器,这对某个企业或者某个业务来说,可能是“救命之道”,比如像上图的情况,人为介入往往是太慢了,来不及了。
文章中只说了tidb可以自动伸缩。 但其实tikv也可以自动伸缩。包括tiflash也可以自动伸缩。代码如下。
------------------创建auto scaling-------
import boto3
import time
import yaml
import subprocess
创建 EC2 客户端
ec2_client = boto3.client(‘ec2’, region_name=‘ap-northeast-1’)
autoscaling_client = boto3.client(‘autoscaling’, region_name=‘ap-northeast-1’)
创建启动配置
launch_configuration_name = ‘my-launch-configuration’
autoscaling_client.create_launch_configuration(
LaunchConfigurationName=launch_configuration_name,
ImageId=‘ami-0a0b7b240264a48d7’, # 替换为 Ubuntu 2024 的 AMI ID
KeyName=‘dba-used-key-pair’,
InstanceType=‘t2.large’,
SecurityGroups=[‘launch-wizard-3’],
)
创建 Auto Scaling 组
autoscaling_group_name = ‘my-auto-scaling-group’
autoscaling_client.create_auto_scaling_group(
AutoScalingGroupName=autoscaling_group_name,
LaunchConfigurationName=launch_configuration_name,
MinSize=1,
MaxSize=2,
DesiredCapacity=1,
VPCZoneIdentifier=‘subnet-05f2763471de42b2a,subnet-00a7f63247b5824d4’, # 替换为你的子网 ID
Tags=[
{
‘Key’: ‘Name’,
‘Value’: ‘my-spot-instance’
}
]
)
------------------自动扩容监控脚本-------
import boto3
import time
import yaml
import subprocess
autoscaling_group_name = ‘my-auto-scaling-group’
创建扩展策略
scale_out_policy = autoscaling_client.put_scaling_policy(
AutoScalingGroupName=autoscaling_group_name,
PolicyName=‘scale-out’,
AdjustmentType=‘ChangeInCapacity’,
ScalingAdjustment=1,
Cooldown=30
)
创建缩减策略
scale_in_policy = autoscaling_client.put_scaling_policy(
AutoScalingGroupName=autoscaling_group_name,
PolicyName=‘scale-in’,
AdjustmentType=‘ChangeInCapacity’,
ScalingAdjustment=-1,
Cooldown=30
)
def run_shell_addcommand(ip_address):
command = f"tiup cluster scale-out tidb-test ./deploybackup.yaml --user ubuntu -i dba.pem -y"
subprocess.run(command, shell=True)
def run_shell_removecommand(ip_address):
command = f"tiup cluster scale-in tidb-test -N ‘{ip_address}:20160’"
subprocess.run(command, shell=True)
创建 CloudWatch 警报
cloudwatch_client = boto3.client(‘cloudwatch’, region_name=‘ap-northeast-1’)
扩展警报
cloudwatch_client.put_metric_alarm(
AlarmName=‘scale-out-alarm’,
MetricName=‘CPUUtilization’,
Namespace=‘AWS/EC2’,
Statistic=‘Average’,
Period=60, # 1 小时
EvaluationPeriods=1, # 2 小时
Threshold=10.0,
ComparisonOperator=‘GreaterThanOrEqualToThreshold’,
ComparisonOperator=‘LessThanOrEqualToThreshold’,
AlarmActions=[scale_out_policy[‘PolicyARN’]],
Dimensions=[
{
‘Name’: ‘AutoScalingGroupName’,
‘Value’: autoscaling_group_name
}
]
)
缩减警报
cloudwatch_client.put_metric_alarm(
AlarmName=‘scale-in-alarm’,
MetricName=‘CPUUtilization’,
Namespace=‘AWS/EC2’,
Statistic=‘Average’,
Period=86400, # 24 小时
Period=86400, # 24 小时
EvaluationPeriods=1,
Threshold=10.0,
ComparisonOperator=‘LessThanOrEqualToThreshold’,
AlarmActions=[scale_in_policy[‘PolicyARN’]],
Dimensions=[
{
‘Name’: ‘AutoScalingGroupName’,
‘Value’: autoscaling_group_name
}
]
)
更新 deploy.yaml 文件
def update_deploy_yaml(action, instance_ip):
with open(‘deploy.yaml’, ‘r’) as file:
deploy_config = yaml.safe_load(file)
instance = ec2_client.describe_instances(InstanceIds=[instance_id])
instance_ip = instance[‘Reservations’][0][‘Instances’][0][‘PrivateIpAddress’]
if action == ‘add’:
deploy_config[‘tikv_servers’].append({‘host’: instance_ip})
deploy_config[‘tikv_servers’] = [server for server in deploy_config[‘tikv_servers’] if server[‘host’] != ‘1.1.1.1’]
with open(‘deploybackup.yaml’, ‘w’) as file:
yaml.safe_dump(deploy_config, file)
触发扩容后立即执行 Python 脚本
def execute_scale_out_script():
print(“扩容触发,执行脚本…”)
获取新增实例的 ID
response = autoscaling_client.describe_auto_scaling_groups(AutoScalingGroupNames=[autoscaling_group_name])
instance_ids = [instance[‘InstanceId’] for instance in response[‘AutoScalingGroups’][0][‘Instances’] if instance[‘LifecycleState’] == ‘InService’]
for instance_id in instance_ids:
描述实例以获取网络接口信息
describe_instances_response = ec2_client.describe_instances(InstanceIds=[instance_id])
instance_data = describe_instances_response[‘Reservations’][0][‘Instances’][0]
for network_interface in instance_data[‘NetworkInterfaces’]:
if network_interface[‘NetworkInterfaceId’] == instance_data[‘NetworkInterfaces’][0][‘NetworkInterfaceId’]:
private_ip = network_interface[‘PrivateIpAddress’]
print(f"Instance ID: {instance_id}, Private IP: {private_ip}")
update_deploy_yaml(‘add’, private_ip) # 假设
run_shell_addcommand(private_ip)
print(private_ip)
触发缩减后立即执行 Python 脚本
def execute_scale_in_script():
print(“缩减触发,执行脚本…”)
获取被移除实例的 ID
response = autoscaling_client.describe_auto_scaling_groups(AutoScalingGroupNames=[autoscaling_group_name])
instance_ids = [instance[‘InstanceId’] for instance in response[‘AutoScalingGroups’][0][‘Instances’] if instance[‘LifecycleState’] == ‘Terminating’]
for instance_id in instance_ids:
update_deploy_yaml(‘remove’, instance_id)
run_shell_removecommand(ip_address)
模拟扩容和缩减触发
while True:
检查扩展警报状态
alarms = cloudwatch_client.describe_alarms(AlarmNames=[‘scale-out-alarm’])
for alarm in alarms[‘MetricAlarms’]:
if alarm[‘StateValue’] == ‘ALARM’:
execute_scale_out_script()
检查缩减警报状态
alarms = cloudwatch_client.describe_alarms(AlarmNames=[‘scale-in-alarm’])
for alarm in alarms[‘MetricAlarms’]:
if alarm[‘StateValue’] == ‘ALARM’:
execute_scale_in_script()
time.sleep(60) # 每 5 分钟检查一次
执行效果如下