dba-kit
(张天师)
1
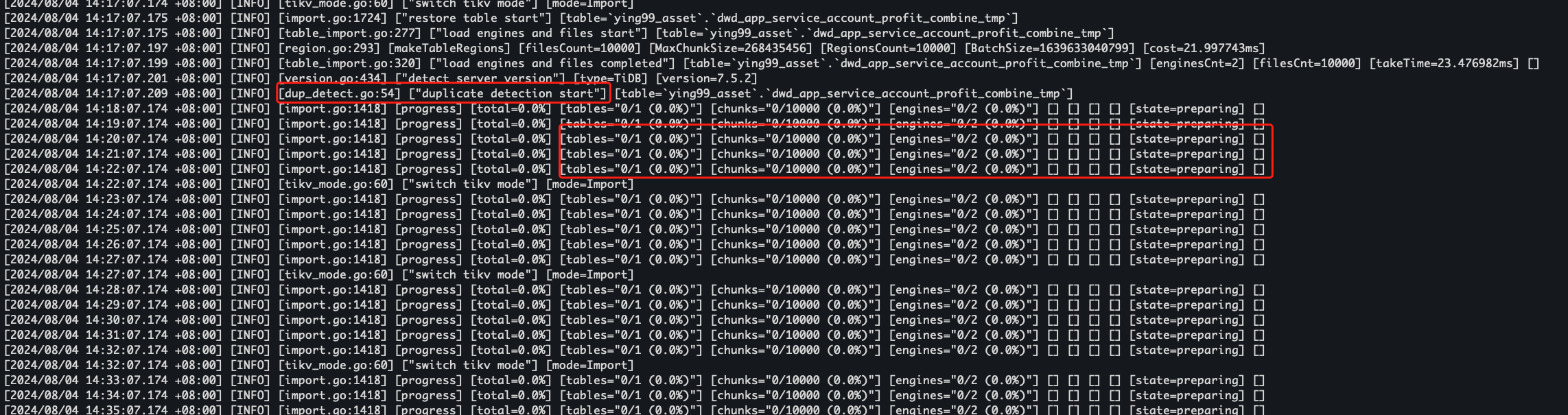
在开启新的冲突检测模式后,配置文件设置如下,在这种模式下,tidb-lightning 一直处于preparing的状态,CPU 使用率也很低。
[conflict]
# 从 v7.3.0 开始引入的新版冲突数据处理策略。默认值为 ""。
# - "":不进行冲突数据检测和处理。如果源文件存在主键或唯一键冲突的记录,后续步骤会报错
# - "error":检测到导入的数据存在主键或唯一键冲突的数据时,终止导入并报错
# - "replace":遇到主键或唯一键冲突的数据时,保留新的数据,覆盖旧的数据
# - "ignore":遇到主键或唯一键冲突的数据时,保留旧的数据,忽略新的数据
# 目前不能与 tikv-importer.duplicate-resolution(旧版冲突检测处理策略)同时使用
strategy = "error"
再改为普通的duplicate-resolution = 'none'模式下,速度立刻就提升了,CPU 使用率也上去了。
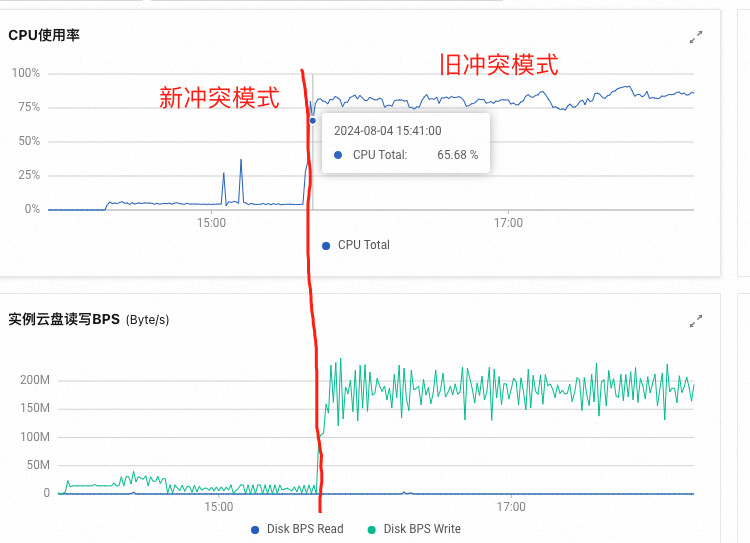
两者的 CPU 和 IO 监控更明显,
kevinsna
(Ti D Ber P O Zcnp Ja)
2
在 TiDB Lightning 中,duplicate-resolution 配置项用于指定如何处理导入过程中遇到的重复数据问题。当您将 duplicate-resolution 设置为 'none' 时,TiDB Lightning 不会对数据进行任何冲突检测,这通常会加快导入速度,因为省去了检查和处理冲突的步骤。
然而,当您启用了新的冲突检测模式(例如设置 strategy = "error"),TiDB Lightning 需要进行额外的检查来确保数据的唯一性,这可能会导致性能下降。以下是一些可能的解决方案和建议:
- 优化数据源:确保您的数据源尽可能干净,减少重复数据。在导入之前进行数据清洗和去重可以减少 TiDB Lightning 在准备阶段的工作量。
- 调整冲突检测策略:根据您的业务需求,选择合适的冲突检测策略。如果您可以接受在发现冲突时忽略新数据,可以将策略设置为
"ignore"。如果可以接受覆盖旧数据,可以使用 "replace" 策略。
- 资源分配:确保 TiDB Lightning 有足够的计算资源,包括 CPU 和内存。在资源有限的情况下,TiDB Lightning 的性能可能会受到影响。
- 并行度调整:TiDB Lightning 允许您通过配置文件调整并行度,例如
region-concurrency 和 table-concurrency。增加这些值可以提高并行处理能力,但也要注意不要超过系统资源的限制。
- 索引优化:在 TiDB 集群中,确保表上有适当的索引,这可以帮助 TiDB Lightning 更快地检测到重复数据。
dba-kit
(张天师)
3
你这个是 AI 回答的?看起来虽然有些靠谱,但是很多都是官方文档里摘出来的,对解决问题并没有什么帮助。 
dba-kit
(张天师)
4
从官方文档描述来看,是预期内的步骤,但是速度相差也太多了,其实导出文件大概率是没有冲突数据的,最好是做到遇到冲突再决定如何处理,而不是提前检查一遭。
dba-kit
(张天师)
5
在导入之前,前置冲突检测会先读取全部数据并编码,以检测潜在的冲突数据。
-----
看起来是在检查冲突时候,没有使用并发,或者是并发默认用的比较少。最终实验结果是临时买了128C 的机器,开了新版冲突检测只用了7C 多,而老版监测可以使用120C 解析文件。
dba-kit
(张天师)
6
conflict.precheck-conflict-before-import这个参数应该就是控制是否提前进行冲突检测的,并且默认值就是 false。不过这个参数 8.1才有,7.5版本的还没有,如果想使用新版冲突监测逻辑,请使用 8.1 版本以上的 tidb-lightning 来导入。
dba-kit
(张天师)
关闭
7
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。