你这标题说的有点夸张了,各有优劣势,而且你开头说的tikv还负责存储,调度数据不太准确。调度是pd节点的事情,tikv负责行式存储,tidb虽然做计算,但是也会将部分算子下推到tikv各节点计算,然后再汇总到tidb进行汇总。另外,tidb重点是分布式、高性能、高可用场景,同等配置的情况下,甚至不一定有mysql性能好,而且数据量小的情况下,性能也体现不出来。但是当你的单表数据千万级别甚至亿级别的时候,才能发挥出tidb的优势。
我没做过运维,不过老哥。你图里的磁盘性能有点差。
PCIE 3.0 x4的磁盘读3500M/S,4.0X4可以达到7000M/s。PCIE 5.0就更加快了。
tidb就是利用NVME盘的这种高IO来设计的,确实可以把mysql摁在地上摩擦的。
要是换成HDD,只能说,违背了tidb的设计初衷了。
mysql需要分库分表,这个对业务就十分不友好,而tidb是真正的分布式,扩展能力强,业务无感知。
强大的tidb
tidb是后出来的分布式数据库,肯定比传统的mysql要好。
tidb的确是快
TiDB、PostgreSQL和MongoDB是三种不同类型的开源数据库,它们各自具有独特的优势和劣势,适用于不同的业务场景。
- TiDB 是一个分布式关系型数据库,它支持在线事务处理与在线分析处理(HTAP),具备以下特点:
- 强一致性和高可用性,采用多副本存储和Raft协议保证数据一致性。
- 存储计算分离架构,允许按需对计算和存储分别进行在线扩容或缩容。
- 兼容MySQL协议和生态,易于从MySQL迁移。
- 云原生设计,支持自动化部署。
- 适用于金融行业
分布式场景,tidb肯定好于mysql
tidb是为了分布式事务产生的,比mysql设计理念要先进。
你kv得多
嗯嗯,写的不错
tidb代码写的效率高。
tidb机器费用省。成本为mysql的1%。性能提高100倍
tidb的计算自动扩容
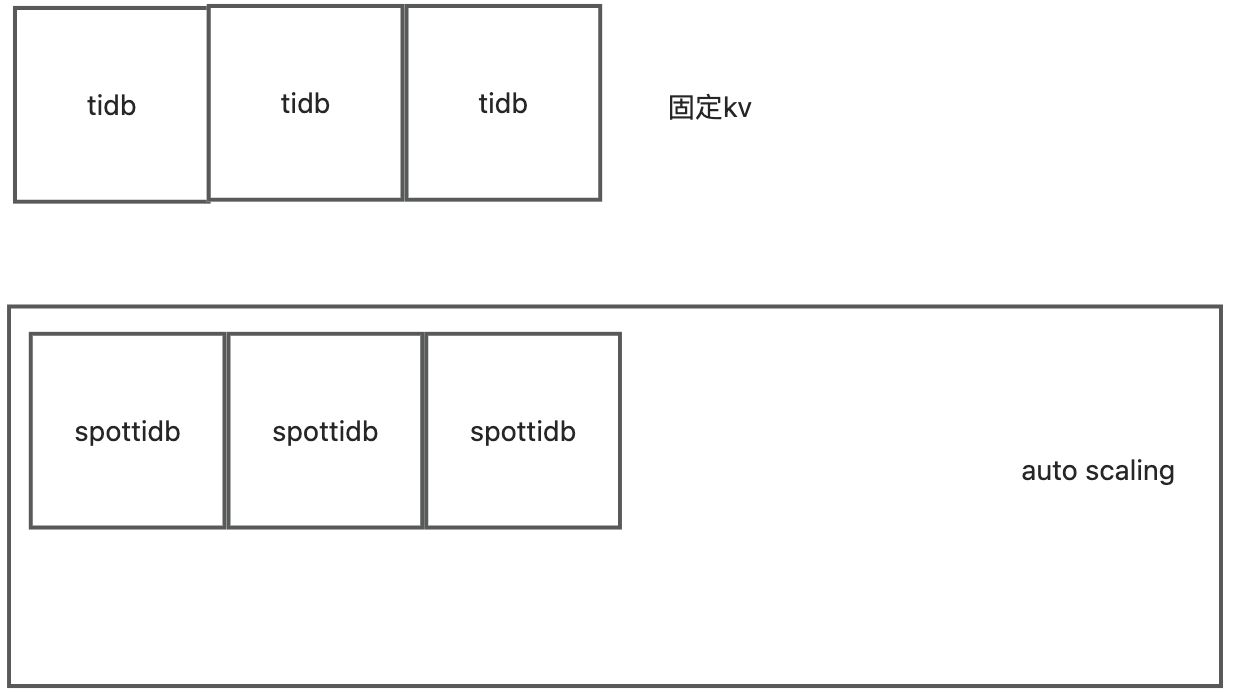
tikv的存储自动扩容
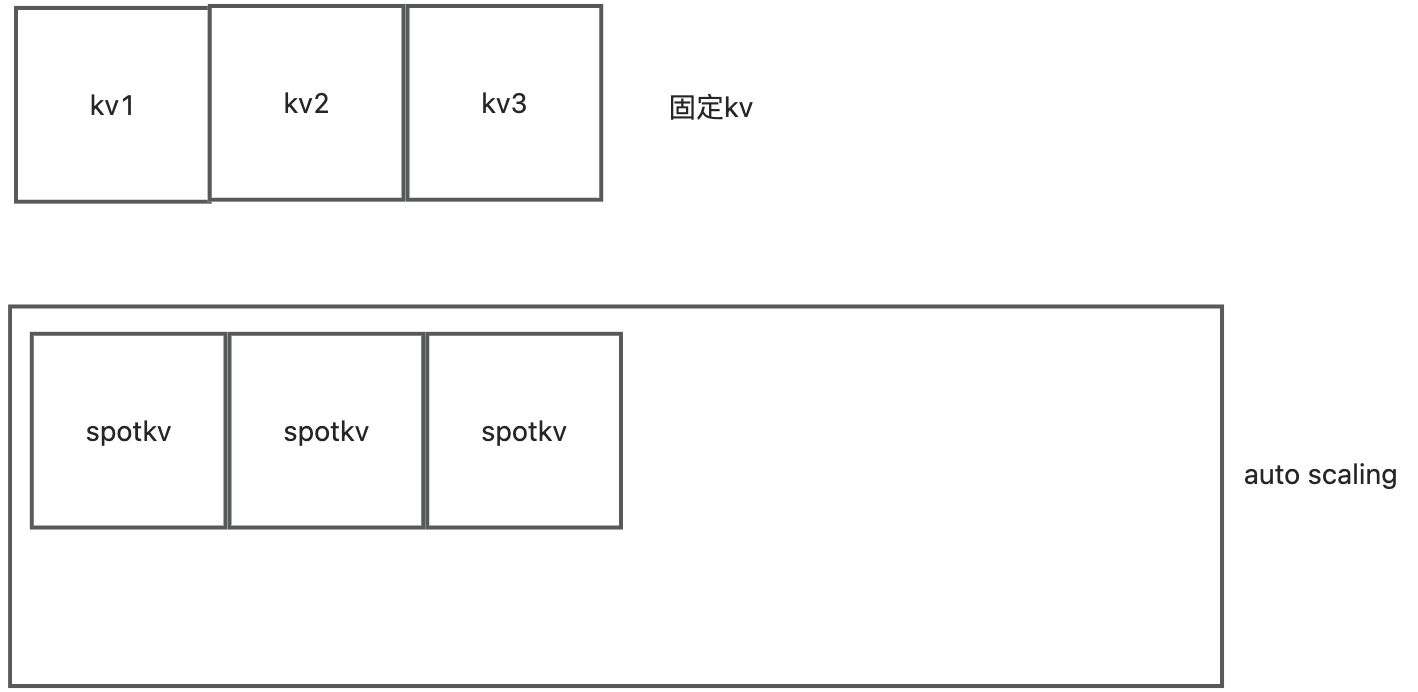
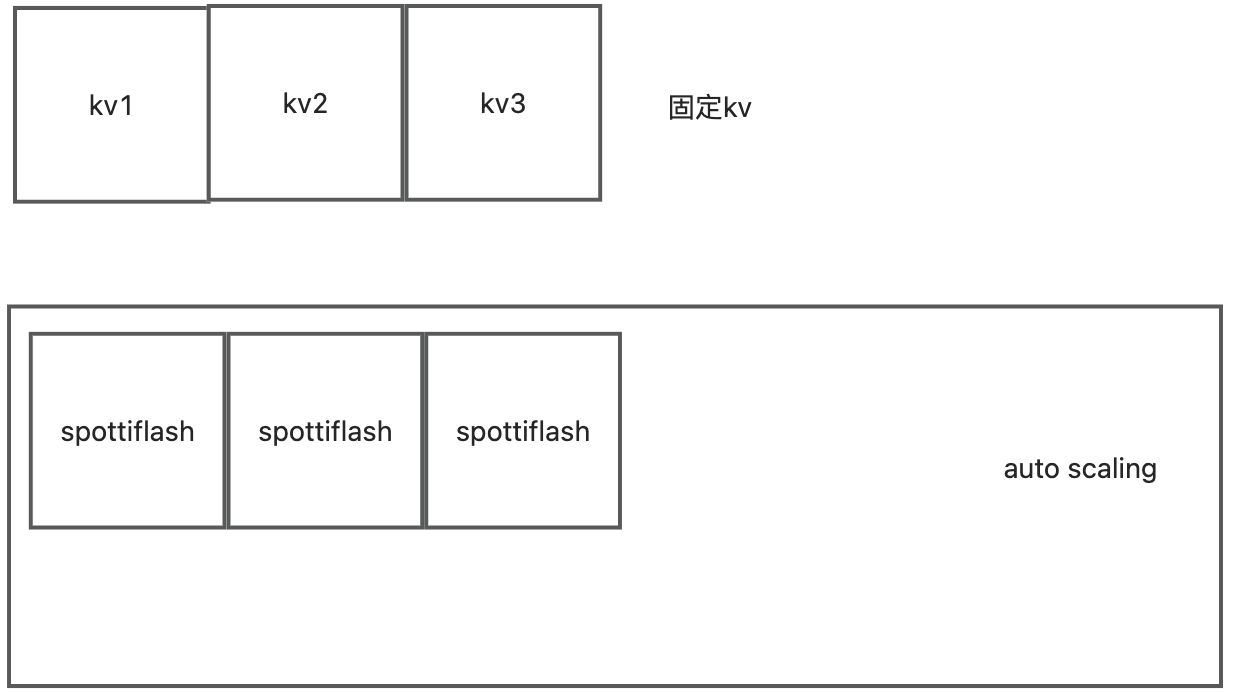
tiflash的大数据自动扩容
今天我实现了个人版本的serverless。
云原生架构上最基本的就是硬件可编程和硬件可改造。
让我们来看pingcap的文章
每年我都有一个时间会特别激动,就是产品大版本发布的时候,通常也是社区年度技术大会 TiDB DevCon 举办的时间。去年 TiDB DevCon 2019,我们发布了 TiDB 3.0 Beta,当然今年 TiDB 4.0 GA 也如约而至。

Serverless
很长一段时间 TiDB 用户使用的集群规模都很大,然后就会再提出一个诉求说“怎么降低我的使用成本”。TiDB 4.0 拥有了 Serverless 能力之后,会根据用户的实际业务负载,基于 K8s 自动做弹性伸缩。
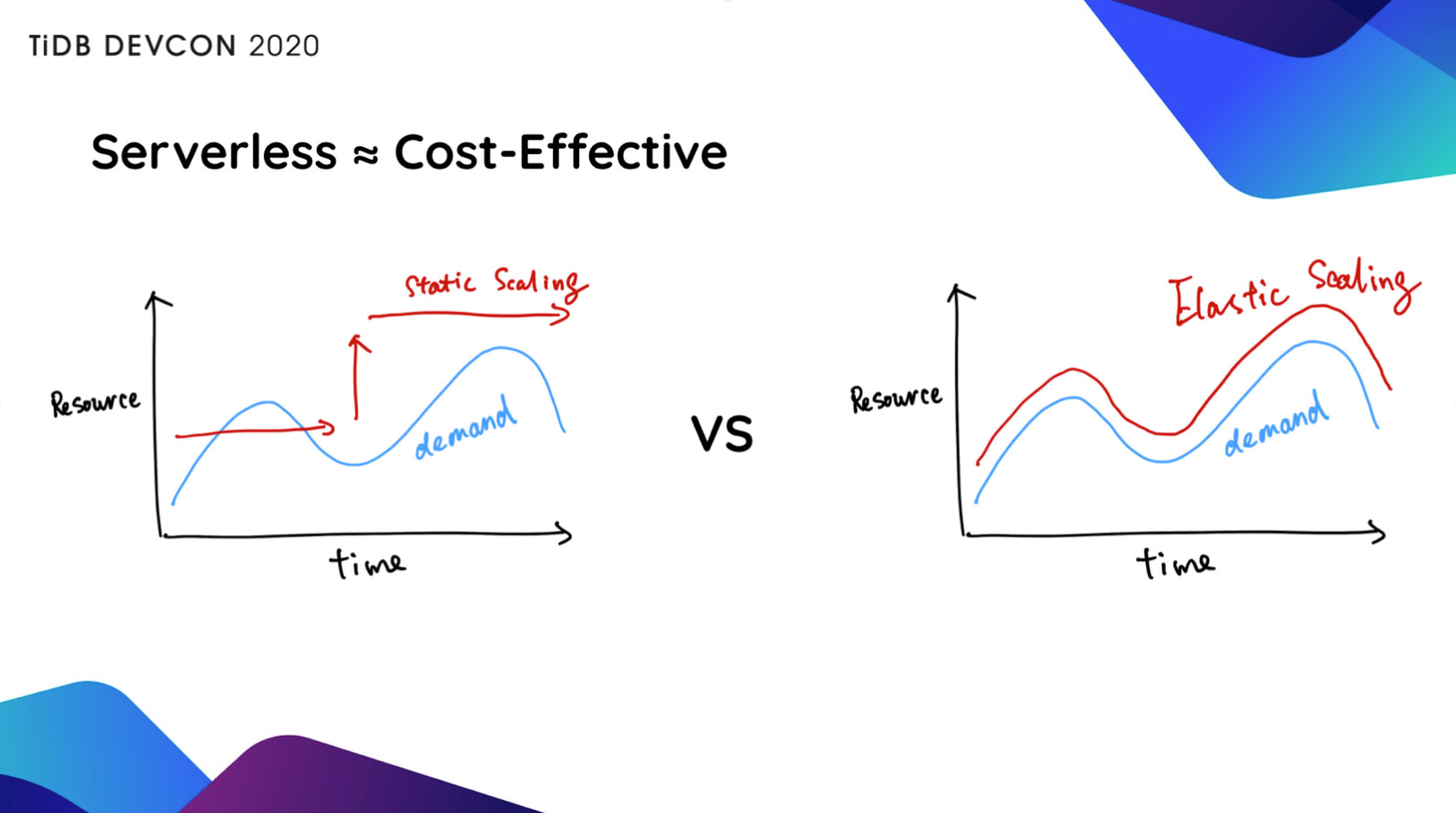
从前,当我们在上线一个系统的时候,第一件事就是 Capacity Planning,去评估一下我们大概需要多少台服务器,比如提前准备了 50 台,但是实际上线之后跑了一个月,发现 5 台机器就够了。这就导致了大量的资源浪费。如果整个系统能够在云上全自动弹性伸缩,就能避免这种资源浪费。
更重要的是,TiDB 的弹性伸缩,意味着你永远不需要按照业务的峰值配备系统资源 。比如大家的业务会有早、晚两个明显的高峰,但实际上每个高峰持续时间通常只有 2 个小时左右,也就是说,为了这 4 个小时的高峰,而我们配置了 24 小时的最高资源配置,并为此付费,但非高峰时间的资源和成本完全是可以节省的,可能算下来,我们能够节省的成本大概在 70% 左右,甚至更高。

另外,能够弹性伸缩的 TiDB 可以应对无法预测的 Workload,没有人知道哪一个商品在什么时候会大卖,没有人知道我卖的哪一个基金在什么时候会火,这时如果我们给系统一个权限,让它能够自动根据业务当前的实际情况,扩充服务器,这对某个企业或者某个业务来说,可能是“救命之道”,比如像上图的情况,人为介入往往是太慢了,来不及了。
文章中只说了tidb可以自动伸缩。 但其实tikv也可以自动伸缩。包括tiflash也可以自动伸缩。代码如下。
------------------创建auto scaling-------
import boto3
import time
import yaml
import subprocess
创建 EC2 客户端
ec2_client = boto3.client(‘ec2’, region_name=‘ap-northeast-1’)
autoscaling_client = boto3.client(‘autoscaling’, region_name=‘ap-northeast-1’)
创建启动配置
launch_configuration_name = ‘my-launch-configuration’
autoscaling_client.create_launch_configuration(
LaunchConfigurationName=launch_configuration_name,
ImageId=‘ami-0a0b7b240264a48d7’, # 替换为 Ubuntu 2024 的 AMI ID
KeyName=‘dba-used-key-pair’,
InstanceType=‘t2.large’,
SecurityGroups=[‘launch-wizard-3’],
)
创建 Auto Scaling 组
autoscaling_group_name = ‘my-auto-scaling-group’
autoscaling_client.create_auto_scaling_group(
AutoScalingGroupName=autoscaling_group_name,
LaunchConfigurationName=launch_configuration_name,
MinSize=1,
MaxSize=2,
DesiredCapacity=1,
VPCZoneIdentifier=‘subnet-05f2763471de42b2a,subnet-00a7f63247b5824d4’, # 替换为你的子网 ID
Tags=[
{
‘Key’: ‘Name’,
‘Value’: ‘my-spot-instance’
}
]
)
------------------自动扩容监控脚本-------
import boto3
import time
import yaml
import subprocess
autoscaling_group_name = ‘my-auto-scaling-group’
创建扩展策略
scale_out_policy = autoscaling_client.put_scaling_policy(
AutoScalingGroupName=autoscaling_group_name,
PolicyName=‘scale-out’,
AdjustmentType=‘ChangeInCapacity’,
ScalingAdjustment=1,
Cooldown=30
)
创建缩减策略
scale_in_policy = autoscaling_client.put_scaling_policy(
AutoScalingGroupName=autoscaling_group_name,
PolicyName=‘scale-in’,
AdjustmentType=‘ChangeInCapacity’,
ScalingAdjustment=-1,
Cooldown=30
)
def run_shell_addcommand(ip_address):
command = f"tiup cluster scale-out tidb-test ./deploybackup.yaml --user ubuntu -i dba.pem -y"
subprocess.run(command, shell=True)
def run_shell_removecommand(ip_address):
command = f"tiup cluster scale-in tidb-test -N ‘{ip_address}:20160’"
subprocess.run(command, shell=True)
创建 CloudWatch 警报
cloudwatch_client = boto3.client(‘cloudwatch’, region_name=‘ap-northeast-1’)
扩展警报
cloudwatch_client.put_metric_alarm(
AlarmName=‘scale-out-alarm’,
MetricName=‘CPUUtilization’,
Namespace=‘AWS/EC2’,
Statistic=‘Average’,
Period=60, # 1 小时
EvaluationPeriods=1, # 2 小时
Threshold=10.0,
ComparisonOperator=‘GreaterThanOrEqualToThreshold’,
ComparisonOperator=‘LessThanOrEqualToThreshold’,
AlarmActions=[scale_out_policy[‘PolicyARN’]],
Dimensions=[
{
‘Name’: ‘AutoScalingGroupName’,
‘Value’: autoscaling_group_name
}
]
)
缩减警报
cloudwatch_client.put_metric_alarm(
AlarmName=‘scale-in-alarm’,
MetricName=‘CPUUtilization’,
Namespace=‘AWS/EC2’,
Statistic=‘Average’,
Period=86400, # 24 小时
Period=86400, # 24 小时
EvaluationPeriods=1,
Threshold=10.0,
ComparisonOperator=‘LessThanOrEqualToThreshold’,
AlarmActions=[scale_in_policy[‘PolicyARN’]],
Dimensions=[
{
‘Name’: ‘AutoScalingGroupName’,
‘Value’: autoscaling_group_name
}
]
)
更新 deploy.yaml 文件
def update_deploy_yaml(action, instance_ip):
with open(‘deploy.yaml’, ‘r’) as file:
deploy_config = yaml.safe_load(file)
instance = ec2_client.describe_instances(InstanceIds=[instance_id])
instance_ip = instance[‘Reservations’][0][‘Instances’][0][‘PrivateIpAddress’]
if action == ‘add’:
deploy_config[‘tikv_servers’].append({‘host’: instance_ip})
deploy_config[‘tikv_servers’] = [server for server in deploy_config[‘tikv_servers’] if server[‘host’] != ‘1.1.1.1’]
with open(‘deploybackup.yaml’, ‘w’) as file:
yaml.safe_dump(deploy_config, file)
触发扩容后立即执行 Python 脚本
def execute_scale_out_script():
print(“扩容触发,执行脚本…”)
获取新增实例的 ID
response = autoscaling_client.describe_auto_scaling_groups(AutoScalingGroupNames=[autoscaling_group_name])
instance_ids = [instance[‘InstanceId’] for instance in response[‘AutoScalingGroups’][0][‘Instances’] if instance[‘LifecycleState’] == ‘InService’]
for instance_id in instance_ids:
描述实例以获取网络接口信息
describe_instances_response = ec2_client.describe_instances(InstanceIds=[instance_id])
instance_data = describe_instances_response[‘Reservations’][0][‘Instances’][0]
for network_interface in instance_data[‘NetworkInterfaces’]:
if network_interface[‘NetworkInterfaceId’] == instance_data[‘NetworkInterfaces’][0][‘NetworkInterfaceId’]:
private_ip = network_interface[‘PrivateIpAddress’]
print(f"Instance ID: {instance_id}, Private IP: {private_ip}")
update_deploy_yaml(‘add’, private_ip) # 假设
run_shell_addcommand(private_ip)
print(private_ip)
触发缩减后立即执行 Python 脚本
def execute_scale_in_script():
print(“缩减触发,执行脚本…”)
获取被移除实例的 ID
response = autoscaling_client.describe_auto_scaling_groups(AutoScalingGroupNames=[autoscaling_group_name])
instance_ids = [instance[‘InstanceId’] for instance in response[‘AutoScalingGroups’][0][‘Instances’] if instance[‘LifecycleState’] == ‘Terminating’]
for instance_id in instance_ids:
update_deploy_yaml(‘remove’, instance_id)
run_shell_removecommand(ip_address)
模拟扩容和缩减触发
while True:
检查扩展警报状态
alarms = cloudwatch_client.describe_alarms(AlarmNames=[‘scale-out-alarm’])
for alarm in alarms[‘MetricAlarms’]:
if alarm[‘StateValue’] == ‘ALARM’:
execute_scale_out_script()
检查缩减警报状态
alarms = cloudwatch_client.describe_alarms(AlarmNames=[‘scale-in-alarm’])
for alarm in alarms[‘MetricAlarms’]:
if alarm[‘StateValue’] == ‘ALARM’:
execute_scale_in_script()
time.sleep(60) # 每 5 分钟检查一次
执行效果如下
流弊~
学习了
tidb是分布式数据库,肯定是快哦。
更重要的是,TiDB 的弹性伸缩,意味着你永远不需要按照业务的峰值配备系统资源 。比如大家的业务会有早、晚两个明显的高峰,但实际上每个高峰持续时间通常只有 2 个小时左右,也就是说,为了这 4 个小时的高峰,而我们配置了 24 小时的最高资源配置,并为此付费,但非高峰时间的资源和成本完全是可以节省的,可能算下来,我们能够节省的成本大概在 70% 左右,甚至更高。
mysql原本需要冗余空闲80%算力 硬对突发情况
有所优化
tidb的确性能好
tidb在分布式环境下,性能卓越。