背景:
近一个月发现了 tikv 的 leader 有大量的 region miss 导致了稳定性问题,业务比较复杂多种 SQL 混合在一起,给问题排查带来了一定难度
环境:
3pd, 7tidb, 8tikv(单机多实例)
影响:
报错期间有大量的 1062 错误(猜测可能是由于抖动,阻塞了大量的插入,而业务侧产生的 uuid 有重复的情况)
报错期间有一个 tidb 节点的内存比较高,实际看日志没有发现单独的大 SQL 语句,实际看到的情况也确实抖动期间 SQL 阻塞。
监控:
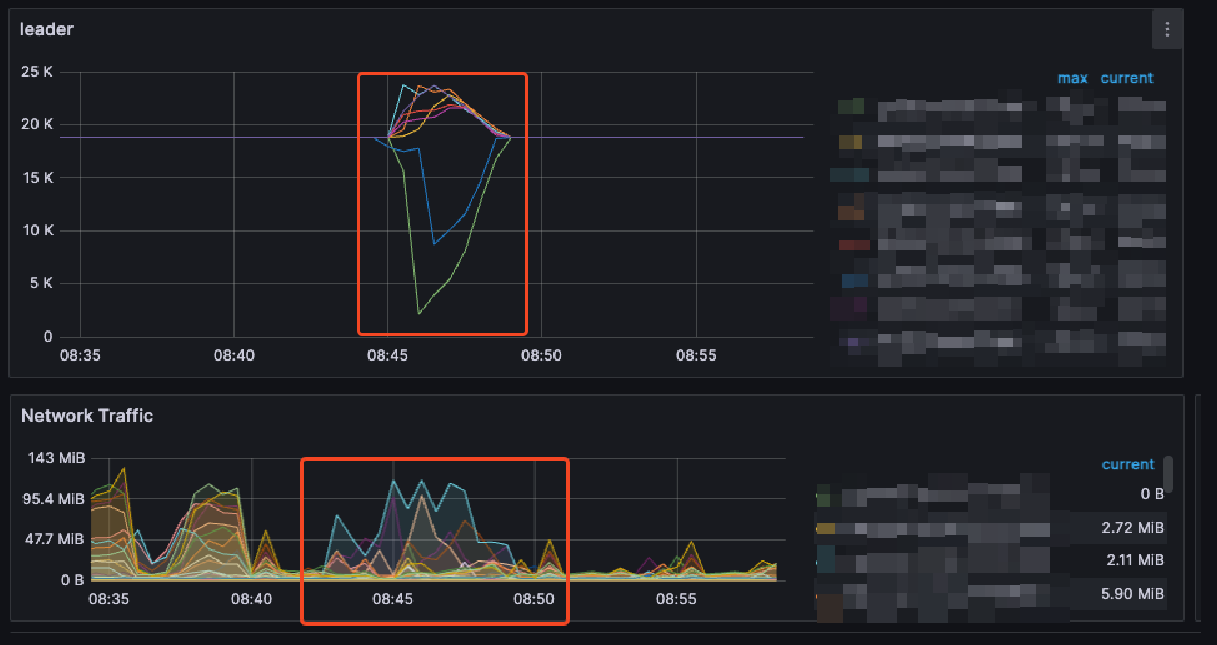
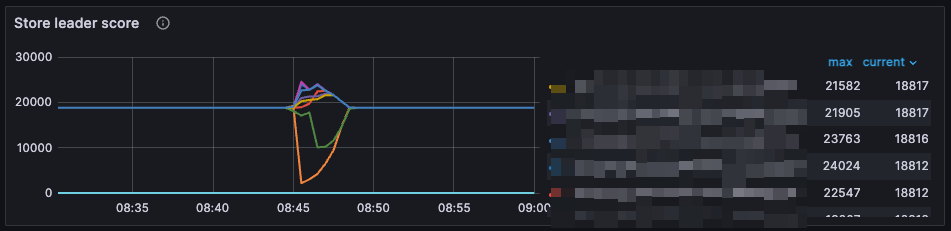


做过的操作
- 升级 tidb 版本从 5.4.2 升级到 7.5.2
- 硬件升级 tikv ,磨平了所有 kv 层的硬件差异
- tidb_allow_tiflash_cop off → on (感觉关系不大)
- 修改了 performance.enforce-mpp: false → true (感觉关系不大)
疑问:我理解 leader 迁移是 tikv 所在主机的评分较低或心跳,主机一直为存活状态所以排除了心跳问题,发现抖动期间的评分较低,(确实集群中存在写热点,但是写热点并非 leader 迁移的主机)想请教下,为什么会给某个 store 的评分设置的比较低
