能不能再我已经给的信息中给解决
你再看下报错中的key ,多找几个 ,在information_schema.tikv_region_status根据start_key end_key 确认下这个key所属的region_id, 然后pd-ctl region xxx 看下这个region的信息
其实有一个简单解决方法,那就是你逻辑备份重建一个集群肯定没问题了。
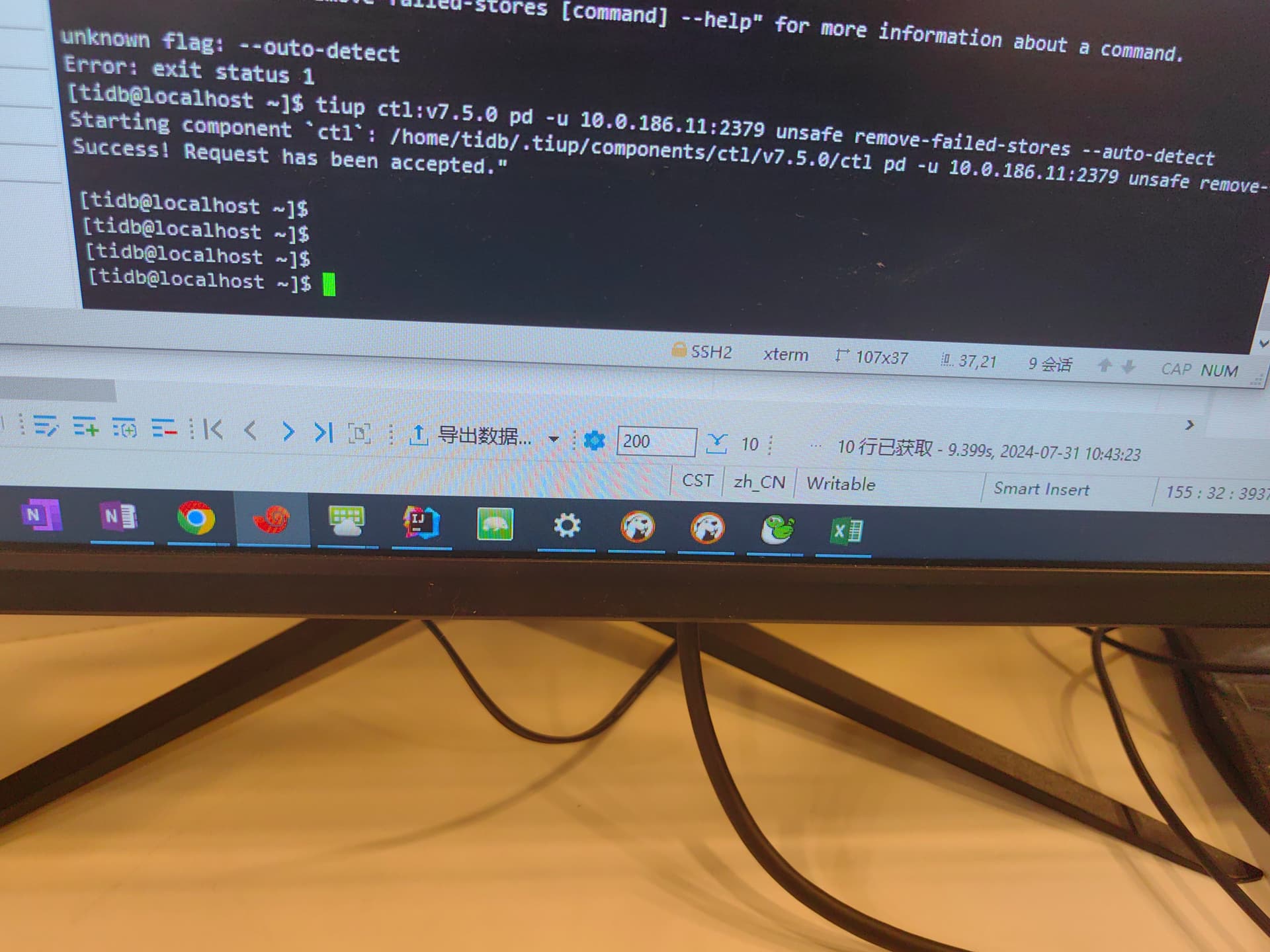
或者再试试 recover 能否自我修复,使用类似:auto detect:
tiup ctl:${cluster_version} pd -u http://${pd_conn} unsafe remove-failed-stores --auto-detect
2 个赞
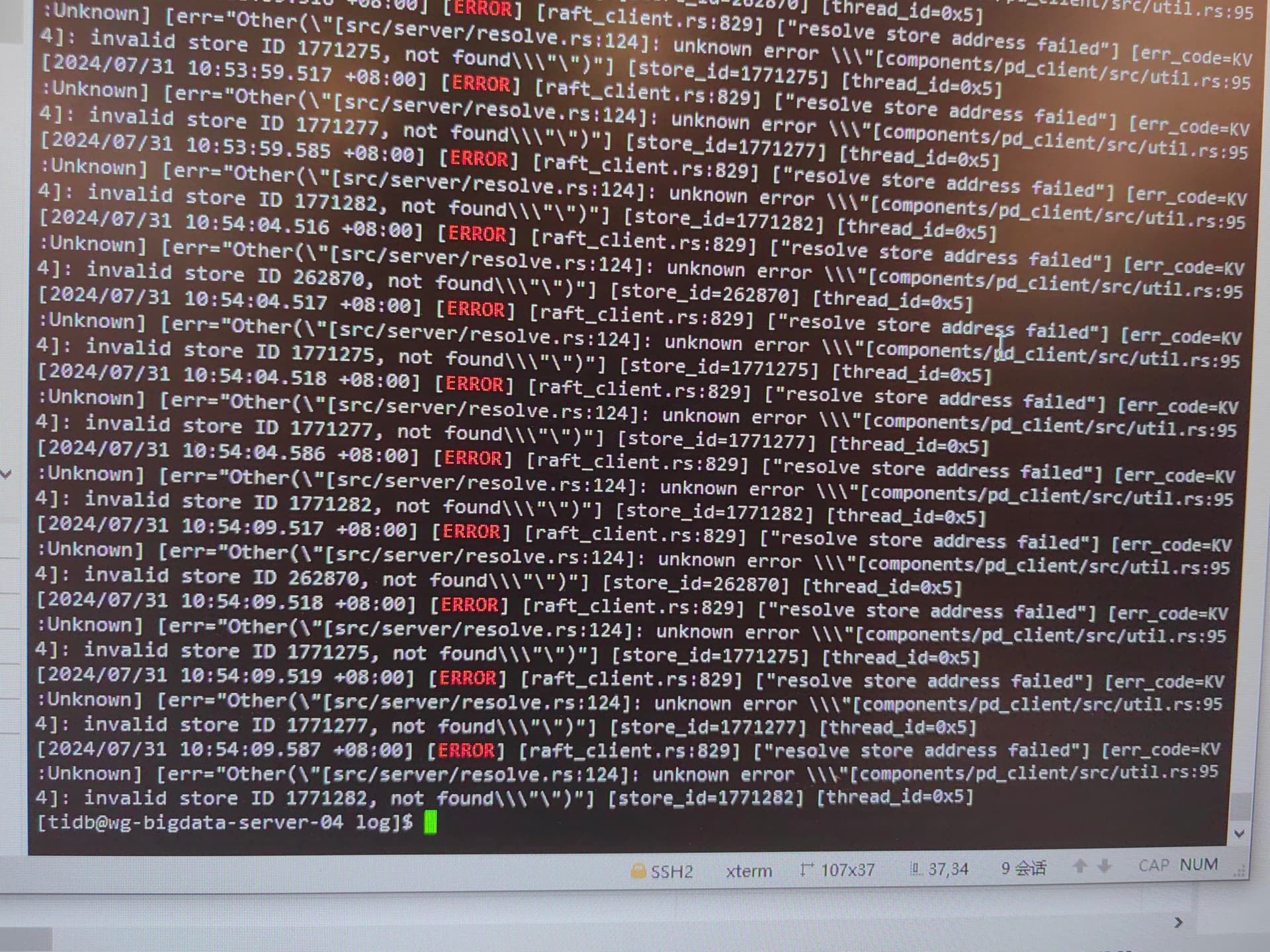
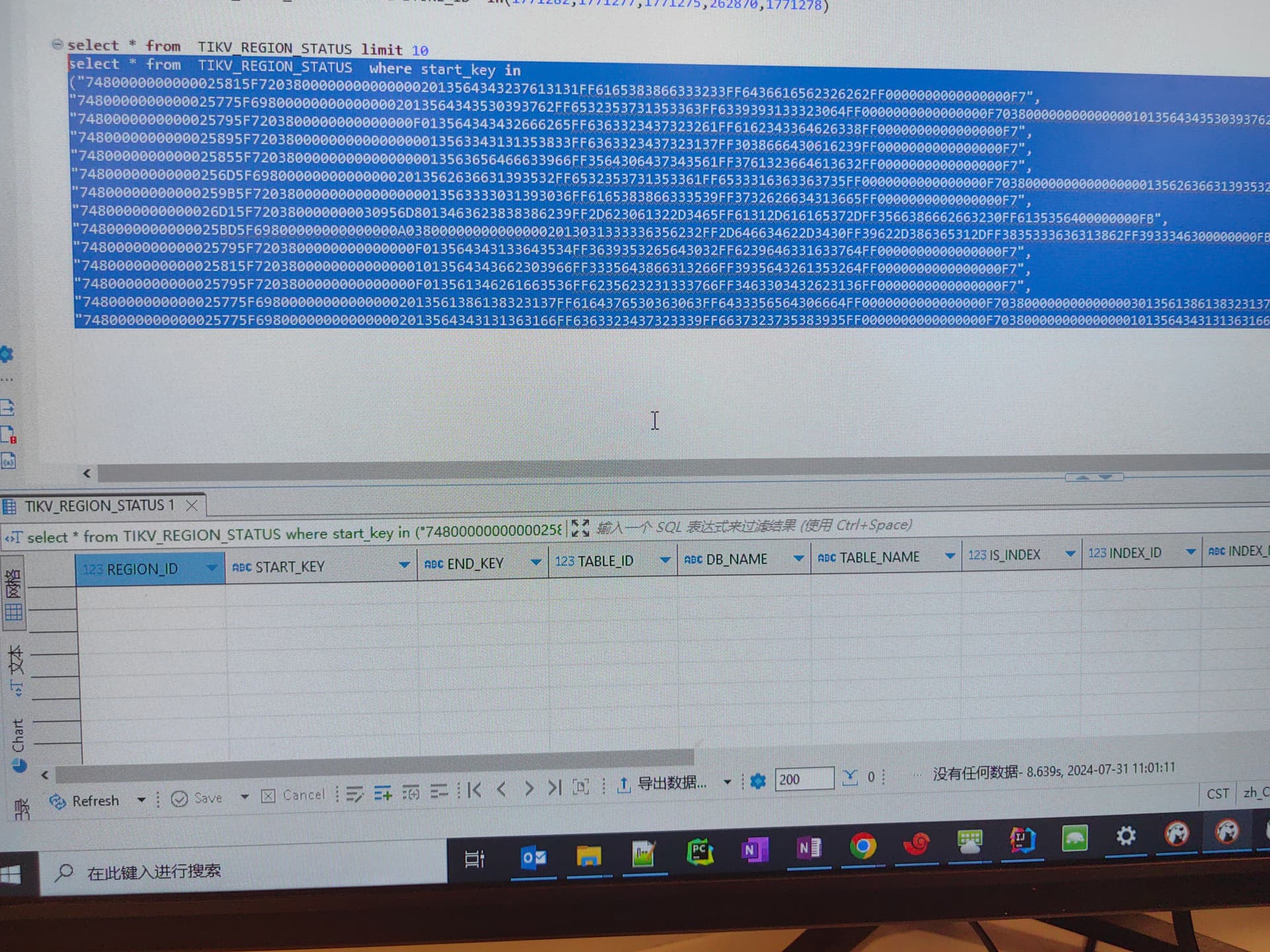

找到的key between start_key and end_key。 你看下key的大小写

好的,unsafe recover 后续一定要慎用、慎用、慎用。
unsafe recover 命令最好在官方判断下使用,这个是强行清理相关节点数据的命令。这个一旦敲下去,集群就很有可能丢数据。
就是不确定这个GC是否后续还会不会卡住
你先观察一段时间吧。不一定。
学到了一招
这个看下来都可以作为一个故障排除的经典案例了
请问:空洞 region是什么意思呢?一般什么情况下会产生空洞region呢?
但总觉得即便这个空间降下来了,集群状态还是有问题,从日志中看到:访问pd一直报错。
我觉得比较稳妥的做法是新建一个集群,然后dumpling+lighting+binlog将数据同步到新集群,然后找个时间生产切换到新集群,<1TB的集群,1小时内能完成,若应用不接受那么长的停机维护,加上binlog同步,几分钟的应用切换,能搞定。
这样成本太高,需要一个新的集群,切换还会影响业务
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。