背景: tidb dumping 导出数据发现针对分区表的导出越来越慢, dumpling 版本 6.5.10
分区表表结构,共 106 个分区
Create Table: CREATE TABLE t1 (
a bigint(20) unsigned NOT NULL AUTO_INCREMENT,
b bigint(20) NOT NULL COMMENT ‘xx’,
…
create_date date NOT NULL COMMENT ‘xx’,
create_time datetime DEFAULT NULL,
PRIMARY KEY (a,create_date) /*T![clustered_index] NONCLUSTERED */
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin AUTO_INCREMENT=xxx /*T! SHARD_ROW_ID_BITS=4 */ COMMENT=‘xxx’
PARTITION BY RANGE COLUMNS(create_date)
(PARTITION p20240419 VALUES LESS THAN (‘20240420’),
PARTITION p20240420 VALUES LESS THAN (‘20240421’),
…
PARTITION p20240802 VALUES LESS THAN (‘20240803’))
发现执行越来越慢:
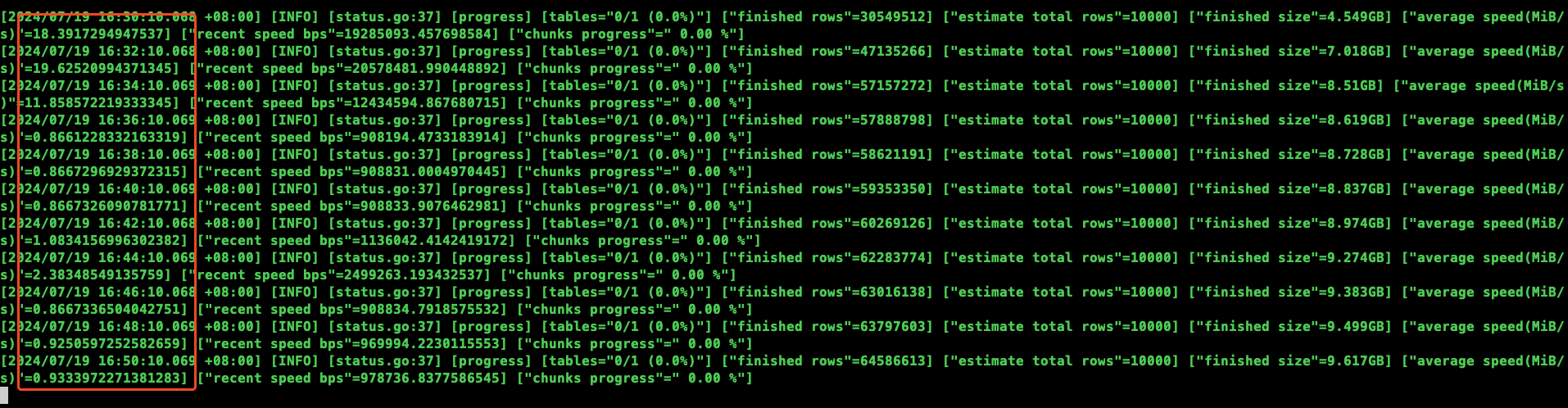
尝试过:
- 修改 GC 时间 10m
- 收集统计信息
在 dump 慢时,发现 SQL 在这步的耗时较长(大约 100s+)
SELECT * FROM xxx.t1 WHERE _tidb_rowid>=8070450535665104911 ORDER BY _tidb_rowid
SELECT * FROM xx.t1 WHERE _tidb_rowid>=6341068278783285469 and _tidb_rowid<6917529031091403347 ORDER BY _tidb_rowid
不确定是什么问题,想请教下,多谢