【 TiDB 使用环境】生产环境
【 TiDB 版本】升级前是v5.3.0,升级后是v7.5.2
【复现路径】升级集群
【遇到的问题:问题现象及影响】
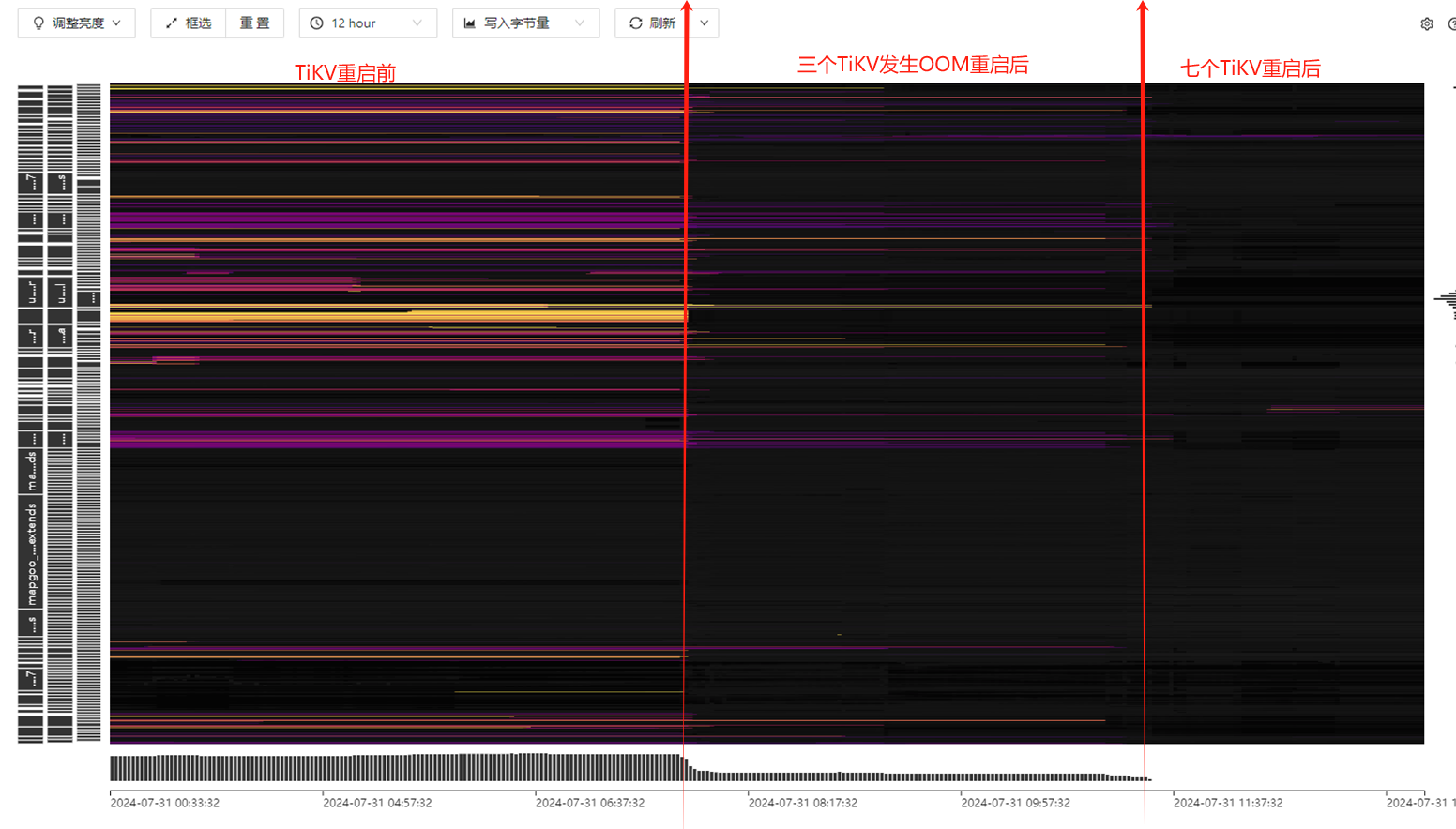
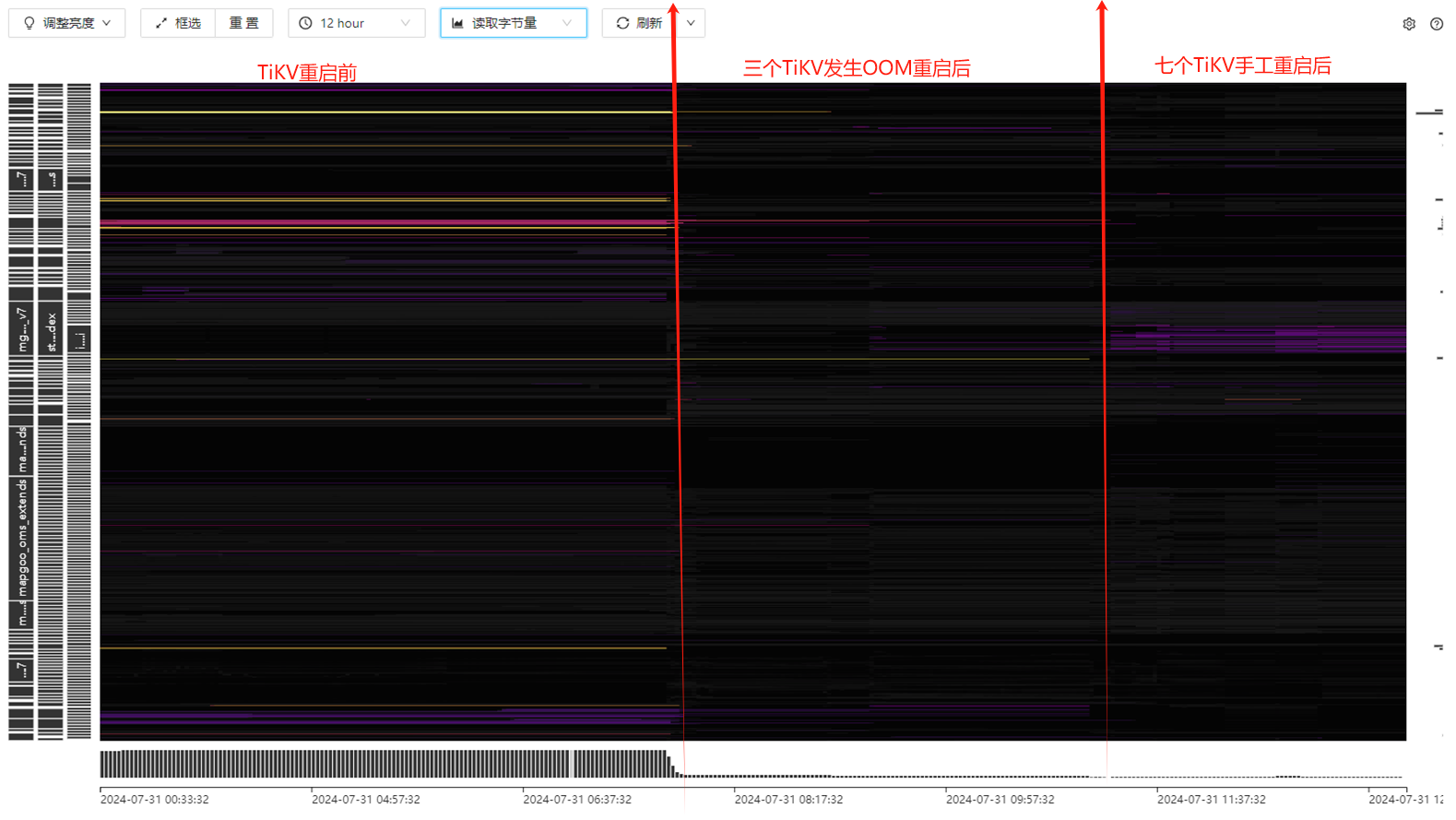
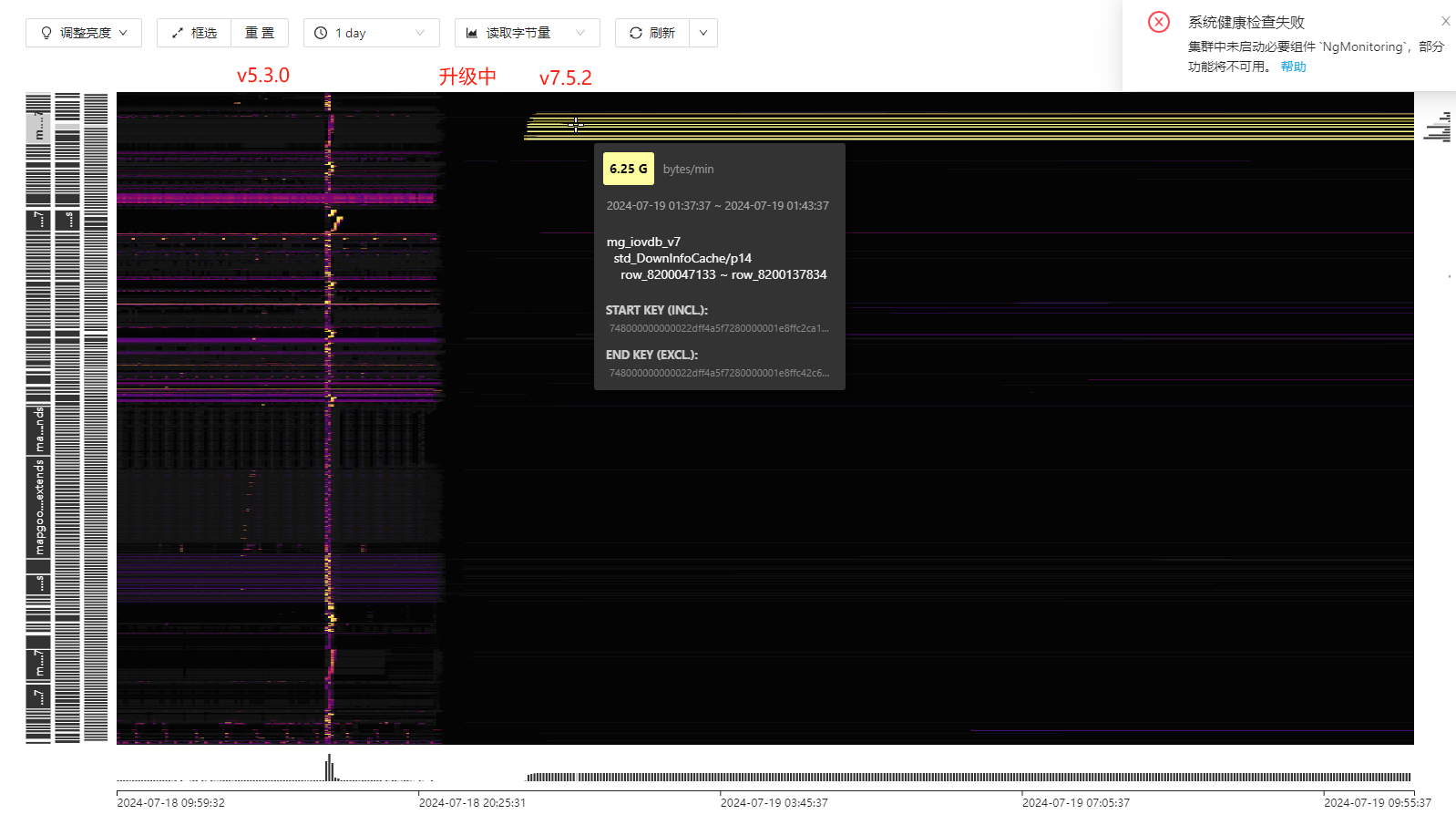
下图为升级前后的流量图对比,可以看出 std_DownInfoCache 这张表的读流量明显增大很多,升级前后业务并没发生什么变化,也做做过应该代码更新,暂时生产没什么影响。
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】升级前是v5.3.0,升级后是v7.5.2
【复现路径】升级集群
【遇到的问题:问题现象及影响】
下图为升级前后的流量图对比,可以看出 std_DownInfoCache 这张表的读流量明显增大很多,升级前后业务并没发生什么变化,也做做过应该代码更新,暂时生产没什么影响。
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
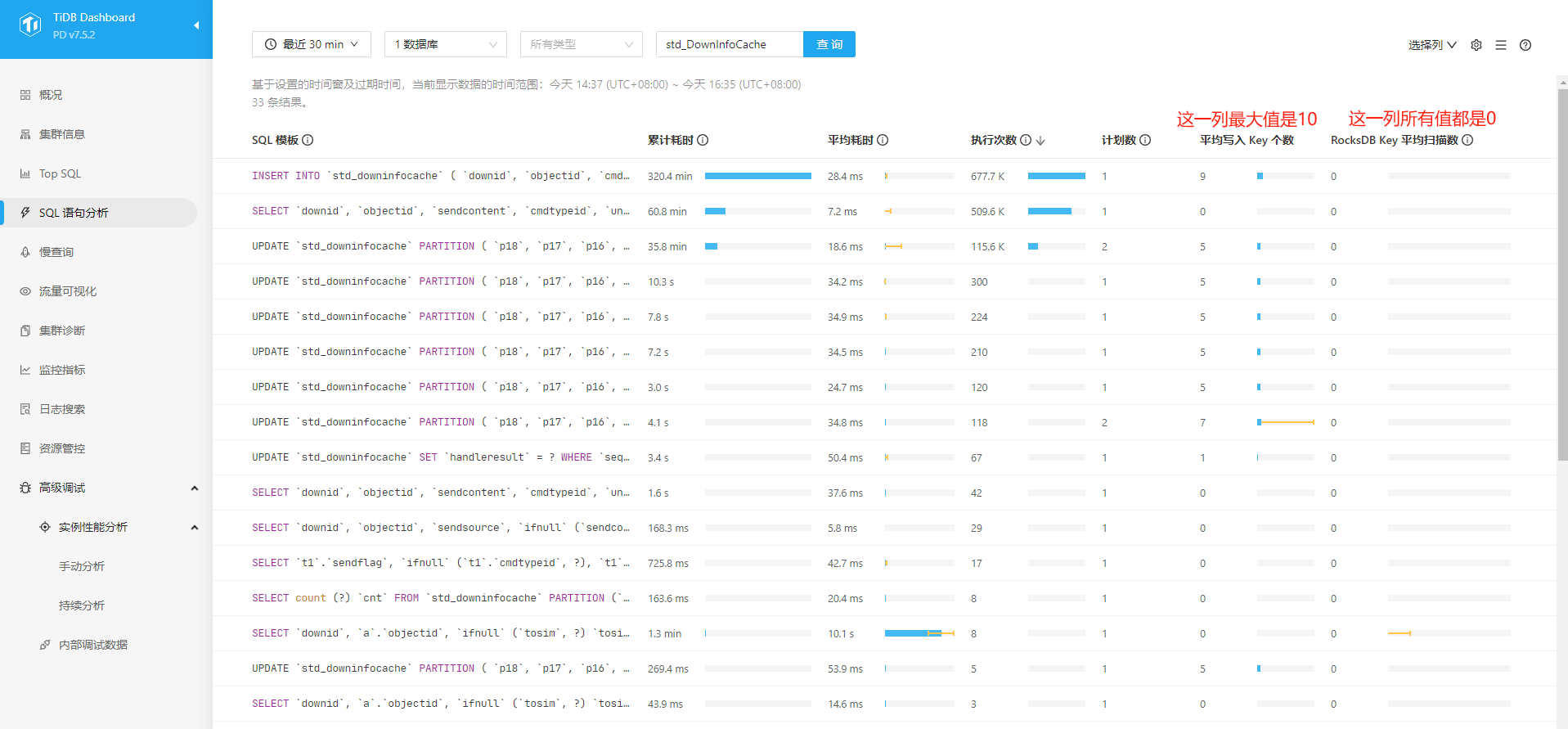
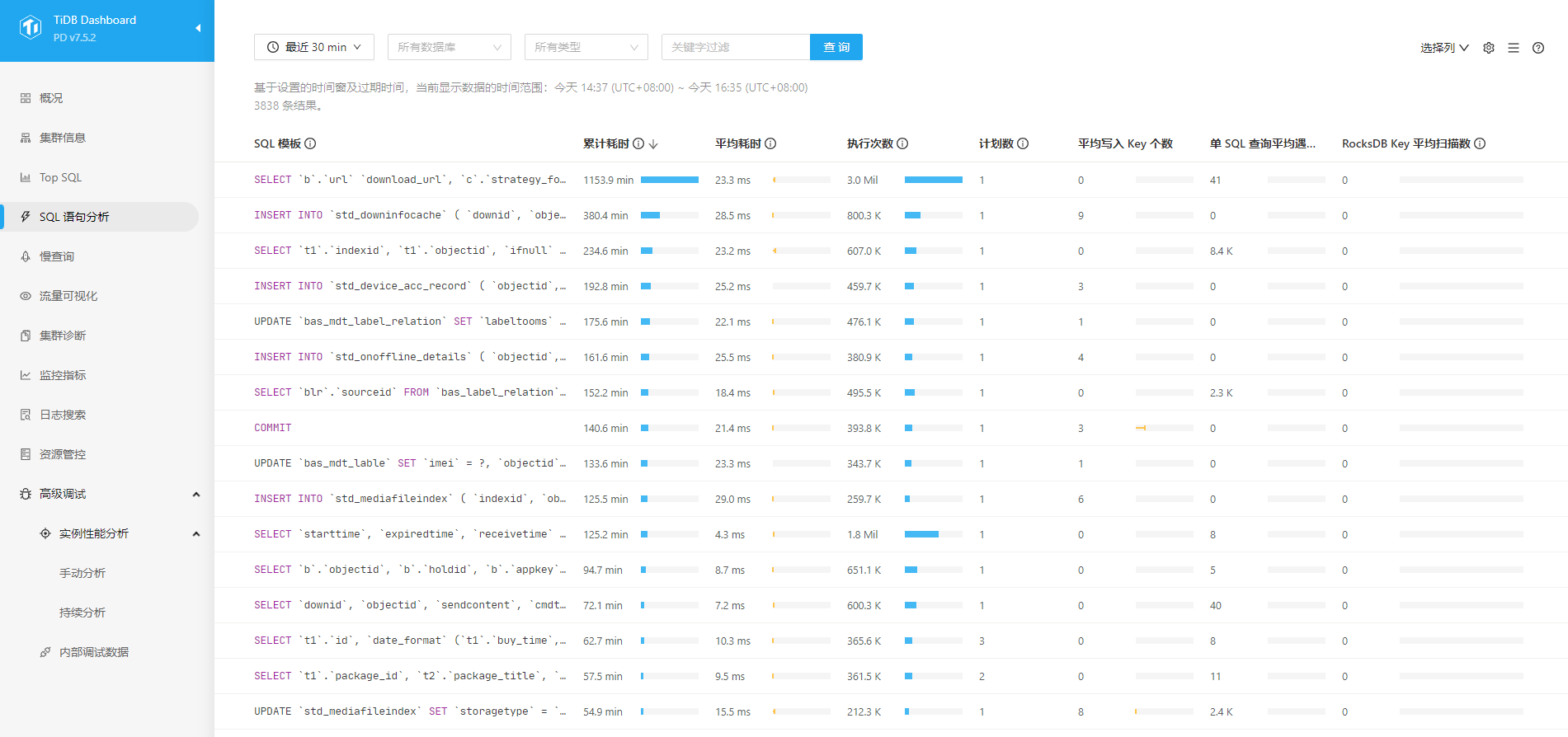
光一张图,分析不了,建议你从 dashboard 的 SQL 语句分析界面,看下这个表相关的 SQL,有什么变化
PS:这图这么亮,直接去 dashboard 的 SQL 语句分析,按 TOP 扫描 key 数量排序找这张表就好啦
不用选数据库,按累计耗时排序,把单 SQL 平均遇到版本数显示出来
第三行的那个 SQL 看看
第三行的sql没有涉及到流量很高那个表:
SELECT
t1.IndexID,
t1.ObjectID,
IFNULL(t1.Channel, 0),
t1.LocalFileName,
IFNULL(t1.LocalFilePath, ''),
IFNULL(t1.FileFormat, ''),
t1.FileSize,
IFNULL(t1.Resolution, 0),
IFNULL(t1.Rate, 0),
t1.FileType,
IFNULL(t1.StorageType, 0),
IFNULL(t1.CloudUrl, ''),
IFNULL(t1.ThumbUrl, ''),
t1.BeginTime,
t1.EndTime,
UNIX_TIMESTAMP(t1.FileModifyTime),
IFNULL(t1.Duration, 0),
t1.Version,
IFNULL(t1.InsertTime, ''),
IFNULL(t1.UpdateTime, ''),
IFNULL(t1.AwsBucketName, ''),
IFNULL(t1.AwsFileName, ''),
IFNULL(t1.MetaDataOffset, 0),
IFNULL(t1.MetaDataSize, 0),
t1.CloudType
FROM
std_mediafileindex t1
WHERE
1 = 1
AND t1.ObjectID = ?
AND t1.Version > ?
AND t1.storageType > 0
ORDER BY
updateTime ASC
LIMIT
0, 50 [arguments: (204104401, 1721371012)]
别的看起来不像,你再看监控分析下吧
好的,感谢!
看看前右的业务变化
业务并没更新呢,只做了tidb升级
慢查询和sql语句分析都看不到 热力图上显示的那张表吗?
看下这个是不是有帮助 :专栏 - Dashboard 热力图显示不准? 如何定位热点相关sql ? | TiDB 社区
这个图里的第一条,应该和这个热点表有关吧?
还是要监测下慢sql,具体情况具体分析
业务没变化的话,盲猜是你这个表相关的sql 执行计划变了,比如本来是索引扫描,因为一些情况执行计划变成了全表扫描,所以从热力图上看上去读流量变大了。‘
是不是该表的统计信息不准确了,你手动analyze一下表试试
analyze也没用,现在这个表已经删掉了,但感觉流量图还是不太准确
有没有可能之前的一些业务因为重启而失败了,并且没有重新发起(比如业务端没有设置失败重连机制),导致重启前后的业务量不一致