是我的海
2024 年7 月 18 日 11:49
1
【 TiDB 使用环境】生产环境
Create Table: CREATE TABLE `data_630001t` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`flowid` bigint(20) DEFAULT NULL,
`dataid` bigint(20) DEFAULT NULL,
`thirdId` varchar(32) NOT NULL DEFAULT '',
`title` varchar(100) DEFAULT NULL,
`content` mediumtext DEFAULT NULL,
`source` int(11) DEFAULT NULL,
`url` varchar(128) DEFAULT NULL,
`deleted` int(11) DEFAULT NULL,
`ha3Data` mediumtext DEFAULT NULL,
`ctime` int(11) NOT NULL DEFAULT '0',
`utime` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`) /*T![clustered_index] NONCLUSTERED */,
KEY `thirdId` (`thirdId`),
KEY `idx_deleted` (`deleted`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
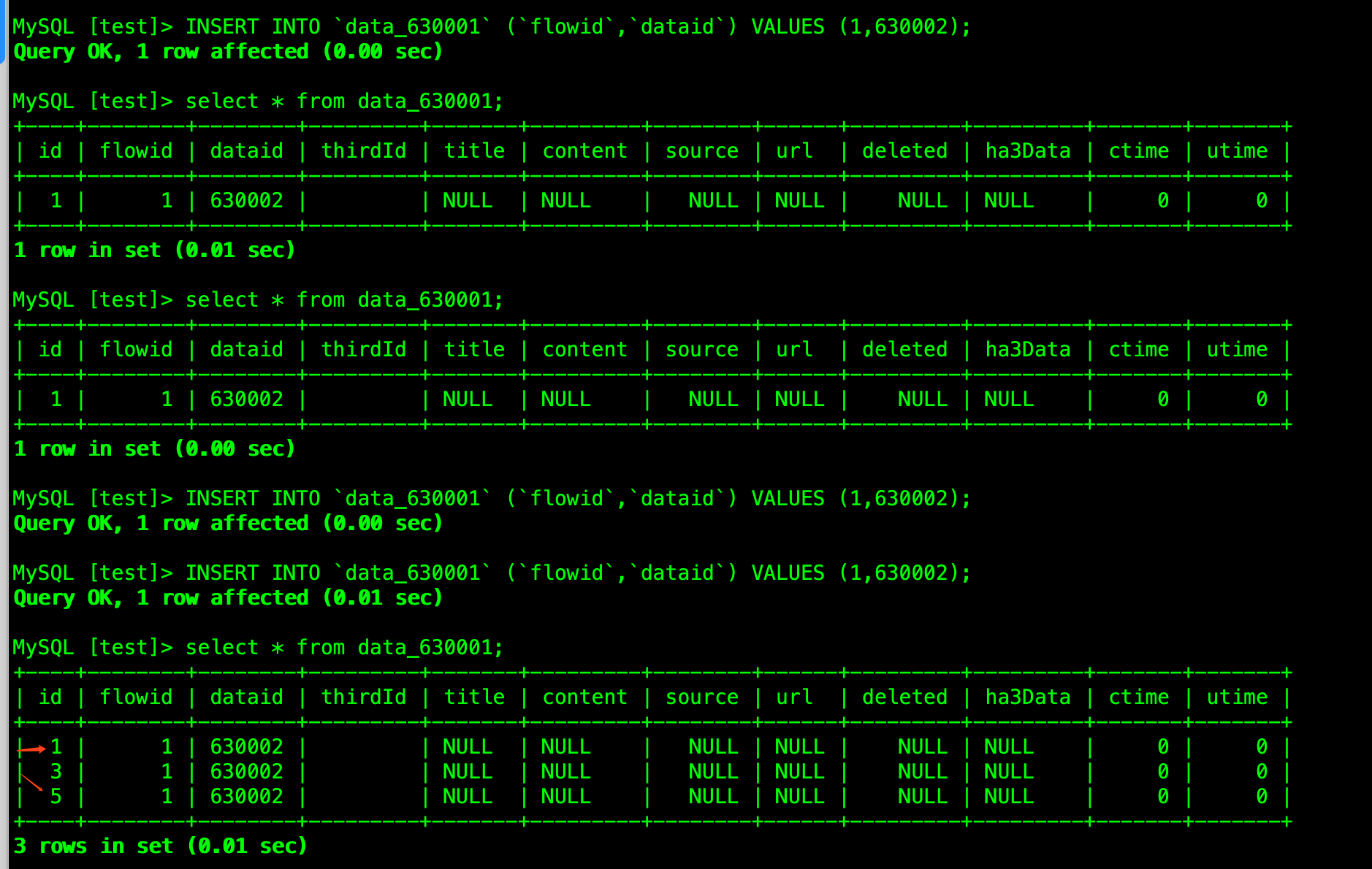
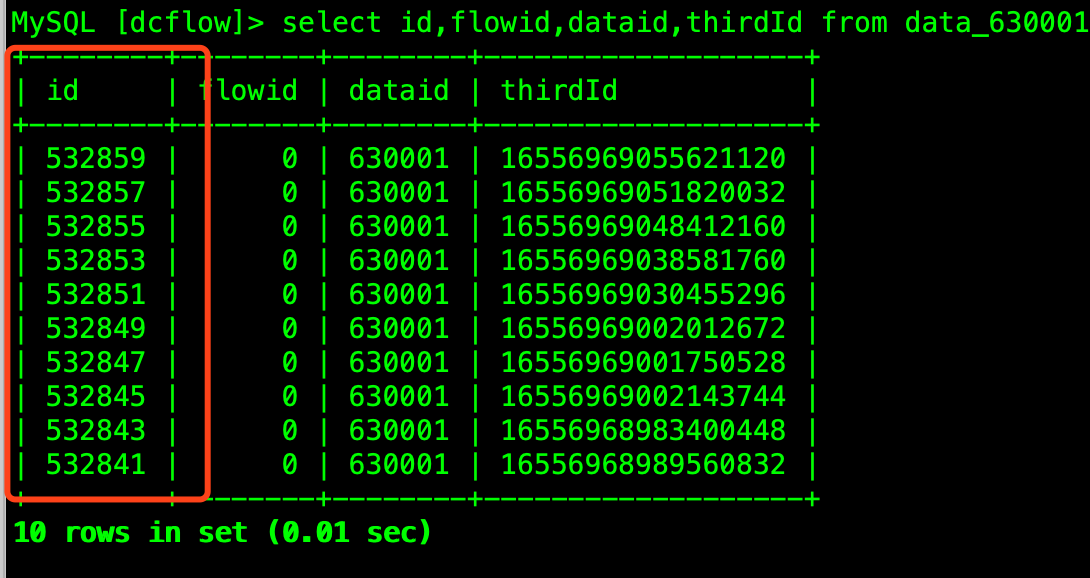
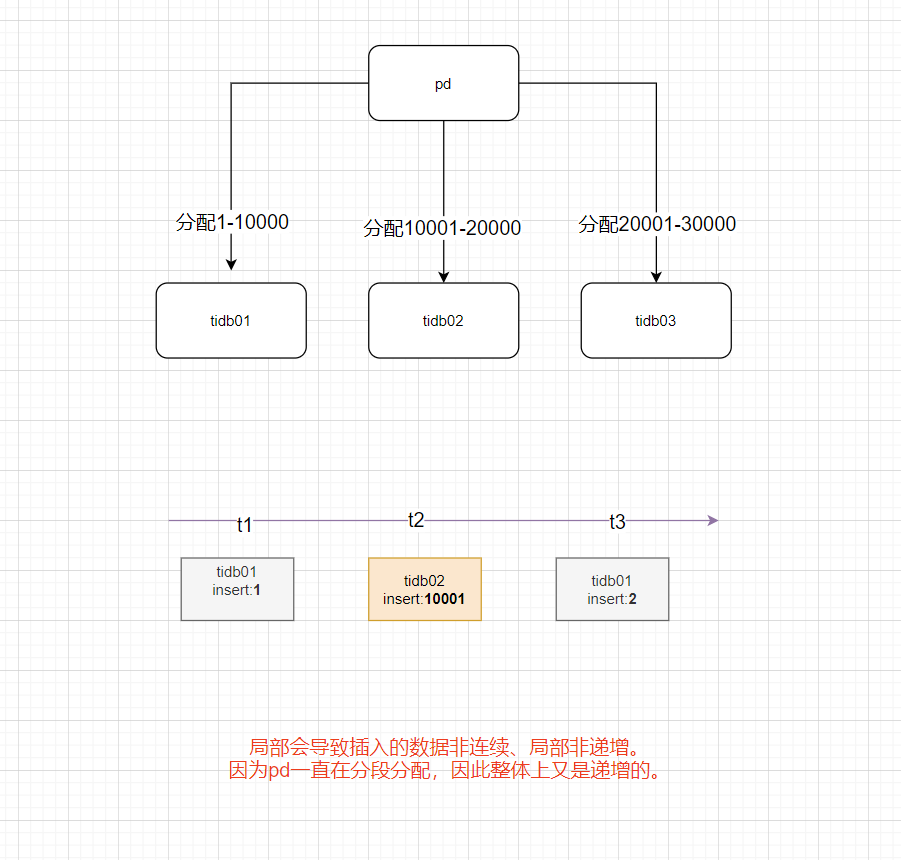
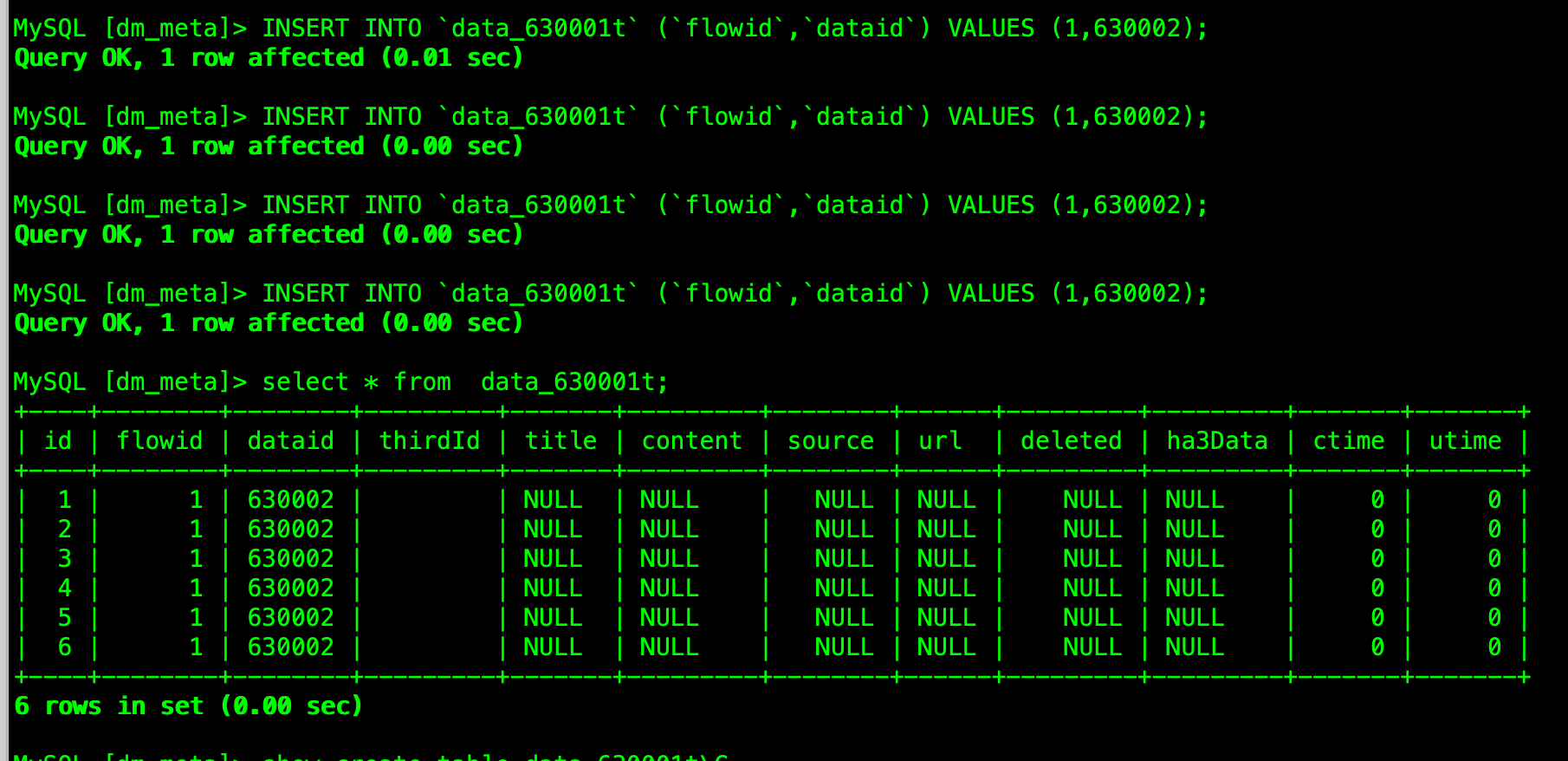
id 不是预期中的1,2,3 而是1,3,5。实际业务中也是规律的步长为2 的id,偶尔会出现一个连续的
但是当把表改成CLUSTERED, 写入的id 就是连续的了,请问以上情况是否符合tidb 自身设计的预期?
濱崎悟空
2024 年7 月 18 日 11:54
2
是的,分布式特性无法保证 AUTO_INCREMENT 连续自增
是我的海
2024 年7 月 18 日 11:55
3
它应该是每个tidb-server 预分配一段id, 但是同一个tidb-server 写入的应该是连续的才对吧?
是我的海
2024 年7 月 18 日 12:24
6
我图中的情况跟你说的不是一个场景,我那个是连接到tidb01 节点上,然后一直insert ,但是id 是呈现了1,3,5 这种,并不是预期中的1,2,3。 但是当我把表改成了 聚簇索引表,插入的id 就是连续了
是我的海
2024 年7 月 18 日 12:39
7
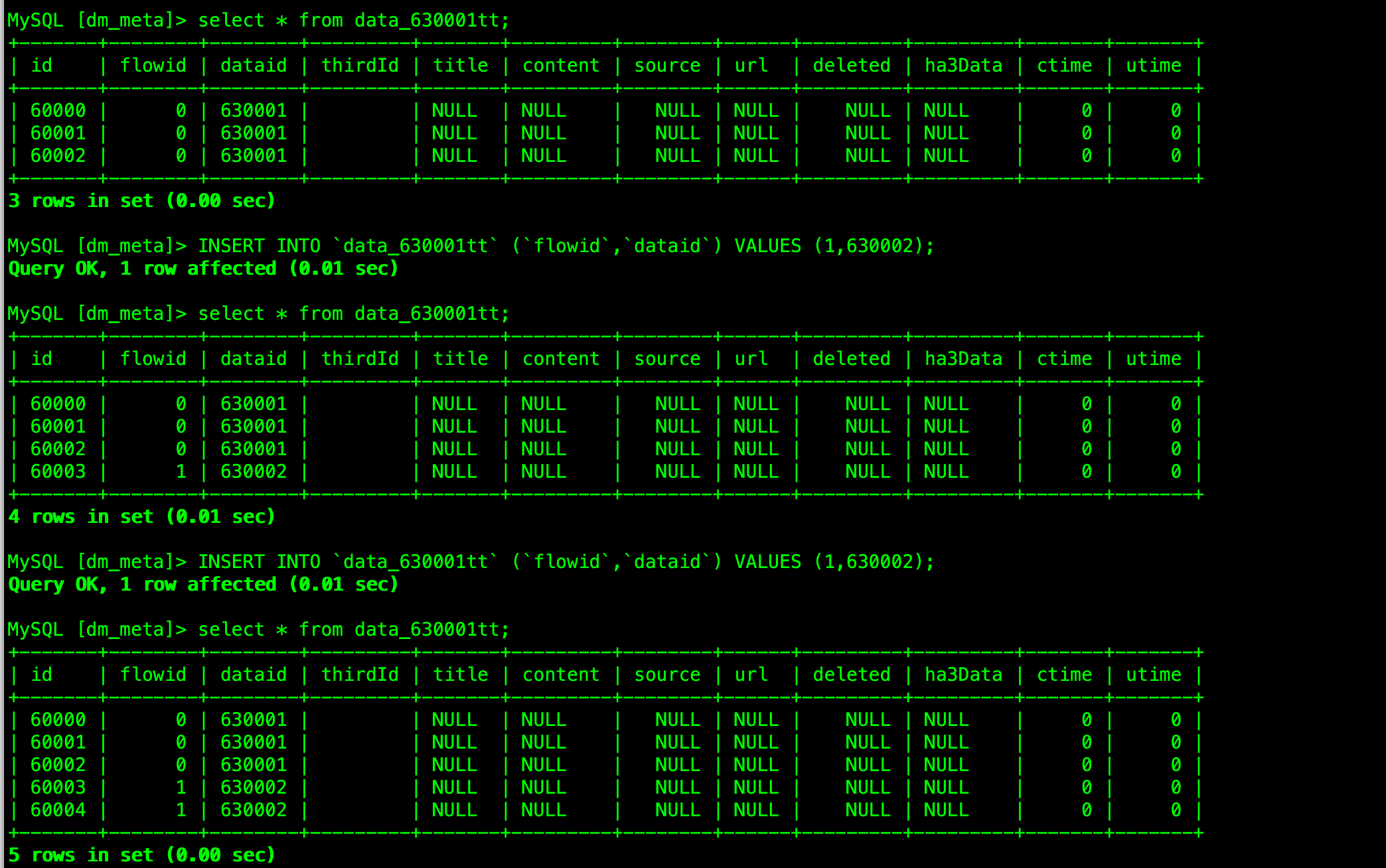
通过配置AUTO_ID_CACHE = 1 实现了 非聚簇索引的自增id 的连续
Create Table: CREATE TABLE `data_630001t` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`flowid` bigint(20) DEFAULT NULL,
`dataid` bigint(20) DEFAULT NULL,
`thirdId` varchar(32) NOT NULL DEFAULT '',
`title` varchar(100) DEFAULT NULL,
`content` mediumtext DEFAULT NULL,
`source` int(11) DEFAULT NULL,
`url` varchar(128) DEFAULT NULL,
`deleted` int(11) DEFAULT NULL,
`ha3Data` mediumtext DEFAULT NULL,
`ctime` int(11) NOT NULL DEFAULT '0',
`utime` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`) /*T![clustered_index] NONCLUSTERED */,
KEY `thirdId` (`thirdId`),
KEY `idx_deleted` (`deleted`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T![auto_id_cache] AUTO_ID_CACHE=1 */
这个在101课程中有阐述的,由于分布式架构,只能保证在一个tikv节点是连续的。
TiDB 的自增 ID (AUTO_INCREMENT ) 只保证自增且唯一,并不保证连续分配。TiDB 目前采用批量分配的方式,所以如果在多台 TiDB server 上同时插入数据,分配的自增 ID 会不连续。当多个线程并发往不同的 TiDB server 插入数据的时候,有可能会出现后插入的数据自增 ID 小的情况。此外,TiDB 允许给整型类型的字段指定 AUTO_INCREMENT,且一个表只允许一个属性为 AUTO_INCREMENT 的字段。
你这个id,没必要一定连续吧。就是个主键而已。没什么含义