【 TiDB 使用环境】生产环境
【 TiDB 版本】从5.4.3 升级到6.5.8
【复现路径】使用tiup 执行在线升级操作
tiup cluster upgrade tidb-xxx v6.5.8
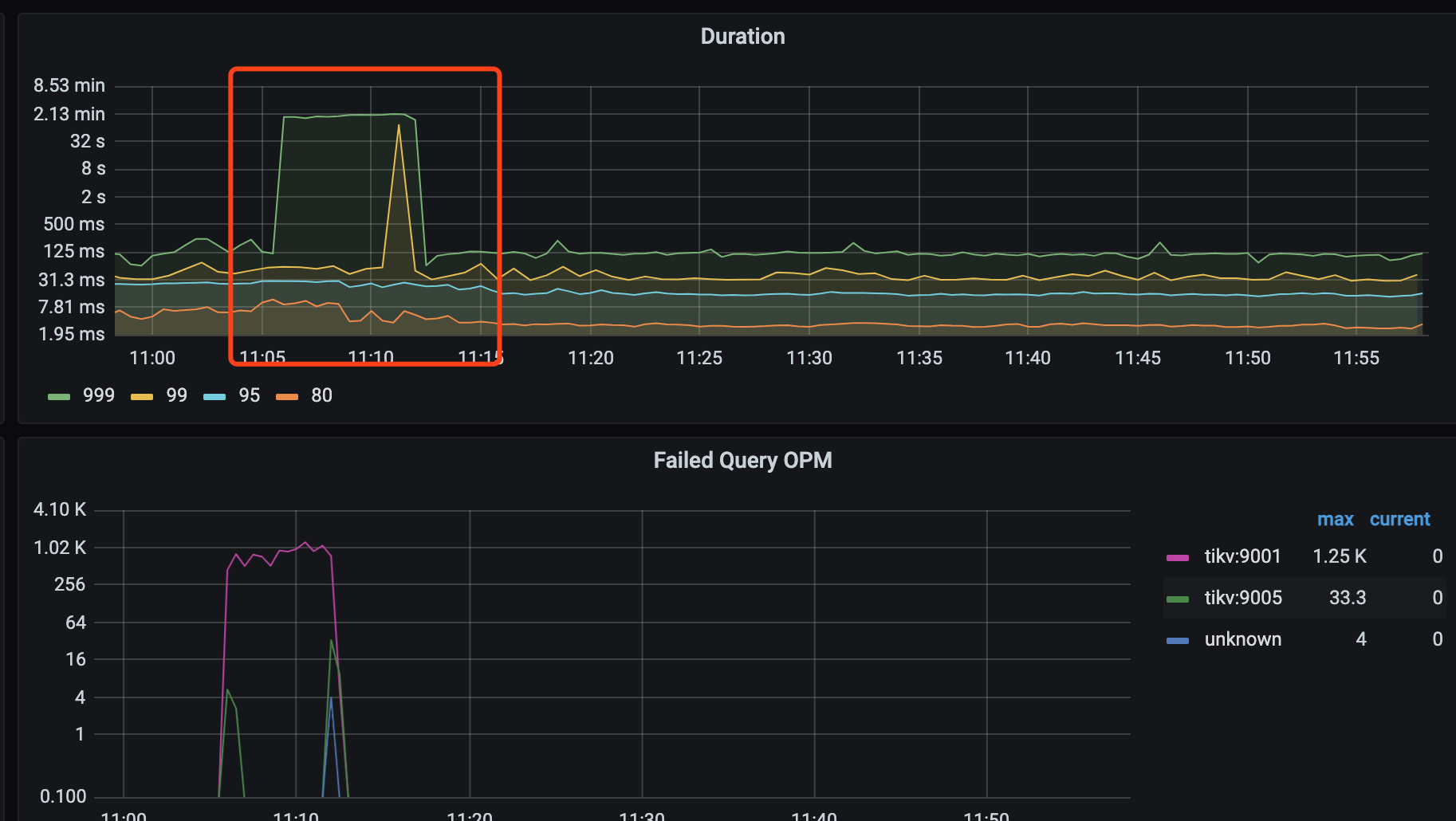
问题现象:在滚动到第三个pd 节点时卡顿超过了8分钟,集群处于不可用状态
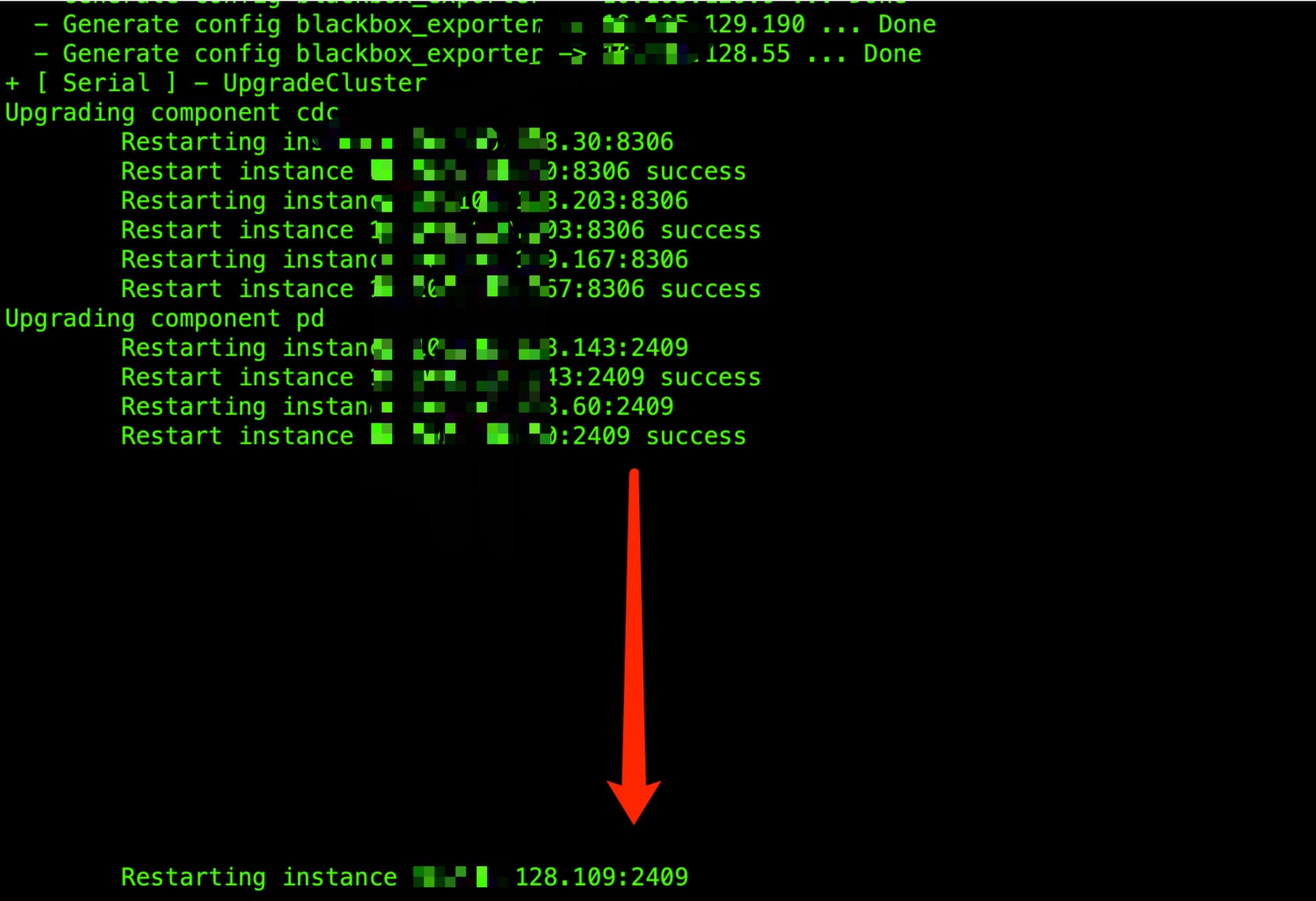
卡顿节点中部分日志
11.04 分左右开始出现报错
11.11 分左右重启成功
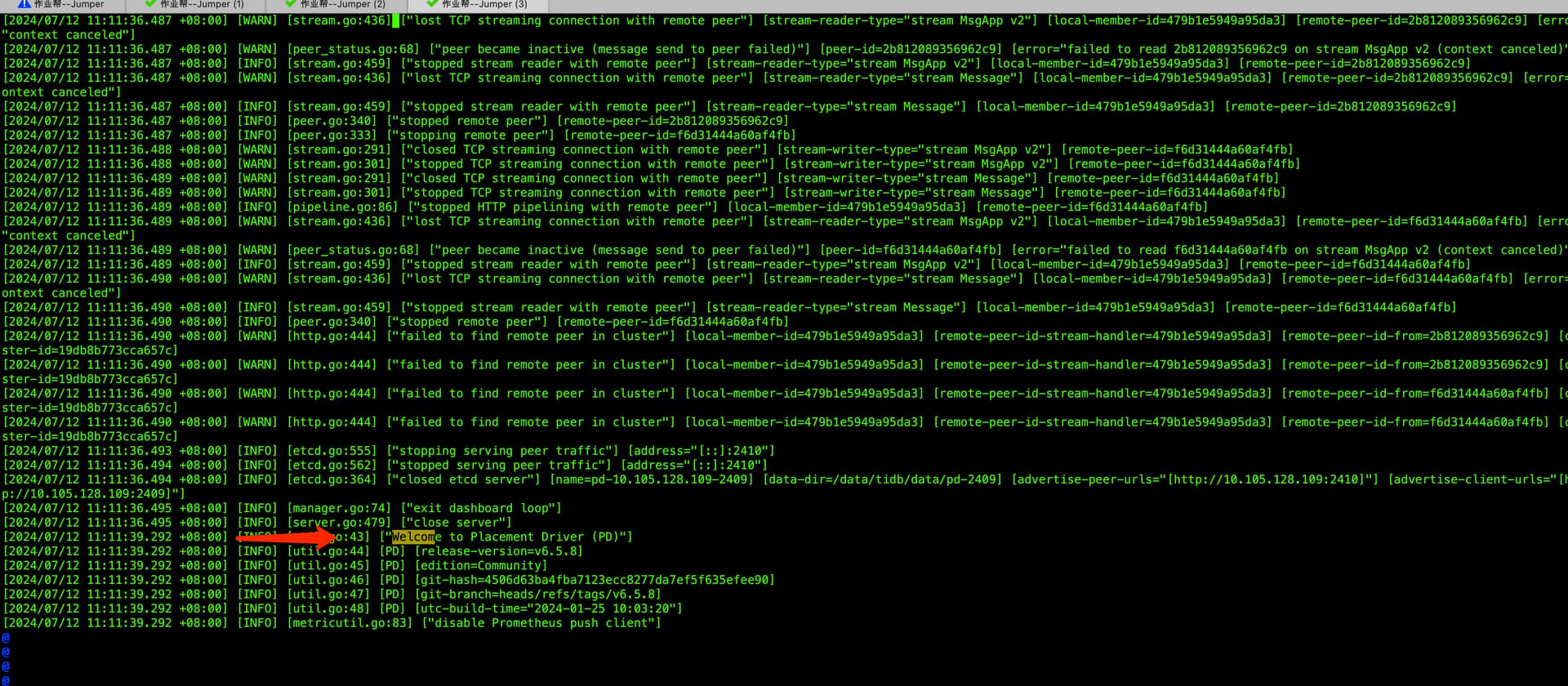
具体日志见附件
pd.log.tar.gz (20.9 MB)
pd 在重启过程中卡顿这么久的具体原因是什么?
【 TiDB 使用环境】生产环境
【 TiDB 版本】从5.4.3 升级到6.5.8
【复现路径】使用tiup 执行在线升级操作
tiup cluster upgrade tidb-xxx v6.5.8
问题现象:在滚动到第三个pd 节点时卡顿超过了8分钟,集群处于不可用状态
卡顿节点中部分日志
11.04 分左右开始出现报错
11.11 分左右重启成功
pd 在重启过程中卡顿这么久的具体原因是什么?
pd重启也是挨个重启的啊,就算有一个卡顿了几分钟,其他pd不是还能正常提供服务吗?
reload 升级过程中:
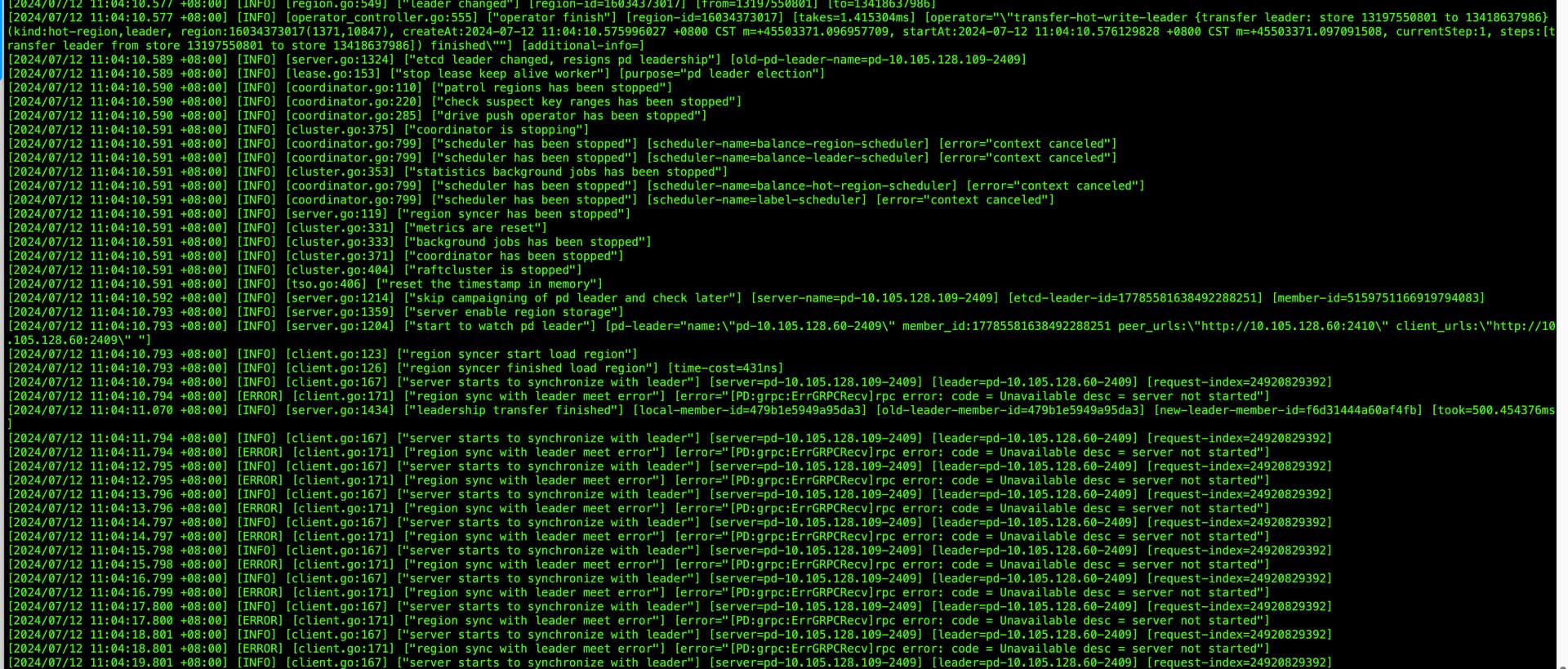
现在看起来你是 " 对 a 发起 member transfer 指令 " 的阶段发生问题,无法选举出 pd leader 导致升级卡主和集群大部分服务不可用。
关于选举卡主:
[2024/07/12 11:04:10.569 +08:00] [INFO] [member.go:275] ["try to resign etcd leader to next pd-server"] [from=pd-10.105.128.109-2409] [to=]
[2024/07/12 11:04:10.570 +08:00] [INFO] [server.go:1413] ["leadership transfer starting"] [local-member-id=479b1e5949a95da3] [current-leader-member-id=479b1e5949a95da3] [transferee-member-id=f6d31444a60af4fb]
[2024/07/12 11:04:10.589 +08:00] [INFO] [server.go:1324] ["etcd leader changed, resigns pd leadership"] [old-pd-leader-name=pd-10.105.128.109-2409]
[2024/07/12 11:04:10.794 +08:00] [ERROR] [client.go:171] ["region sync with leader meet error"] [error="[PD:grpc:ErrGRPCRecv]rpc error: code = Unavailable desc = server not started"]
[2024/07/12 11:04:11.070 +08:00] [INFO] [server.go:1434] ["leadership transfer finished"] [local-member-id=479b1e5949a95da3] [old-leader-member-id=479b1e5949a95da3] [new-leader-member-id=f6d31444a60af4fb] [took=500.454376ms]
[2024/07/12 11:04:11.794 +08:00] [ERROR] [client.go:171] ["region sync with leader meet error"] [error="[PD:grpc:ErrGRPCRecv]rpc error: code = Unavailable desc = server not started"
看日志,感觉可以看下新 leader (f6d31444a60af4fb ) 的日志 ,感觉这个节点当时有问题 ![]()
升成功了没
升级成功了
可以说下怎么解决的?重复执行升级?
就是等待pd 滚动重启成功,只是这个过程比预期的时间更久一些。升级过上百次第一次遇到过这个情况
理解,生产坏境升级过程中,如果时间比较久,心里比较焦虑。
是不是这个时间段,刚好PD业务比较繁忙。
关注该问题
leader切换占用时间了吧
应该是设计上的事,就应该是这个速度的。pd会依次重启,不会一下子重启全部节点。