![]()
不知道啥原因这个文件会丢失,可以把这个表的tiflash先去掉,另外要检查其他的表是不是也有这个问题,可以对比下metadata这个目录下的这些表 的文件数量和设置的tiflash表或分区数量是否一致
pd 预留8g内存 4核心
tidb 混布的时候看内存大小给8g内存
tikv 混布的时候预留多点内存
资源限制
pd 预留8g内存 4核心
tidb 混布的时候看内存大小给8g内存
tikv 混布的时候预留多点内存
- 修改配置文件:
tiup cluster edit-config erptidb
在tikv 下面增加配置主要为:
server_configs:
tidb:
enforce-mpp: true
mem-quota-query: 64294967296
tikv:
storage.block-cache.capacity: 32G
os系统留20%
步骤1.
1.修改配置文件:tiupclusteredit-configerptidb
步骤2.
在tikv 下面增加配置主要为: tidb用64g内存 tikv用32g 操作系统8g内存 pd用8g内存
server_configs:
tidb:
enforce-mpp: true
mem-quota-query: 64294967296
tikv:
storage.block-cache.capacity: 32G
步骤3.
tiup cluster reload erptidb
等研发大佬看看吧
7.5.1
对,这个也是我想弄明白呢 。第一个tiflash宕机也是同样的提示 。不是个例。
等研发看看吧,隐约感觉有bug
从两个帖子的日志看起来,应该是个 bug,但是目前看到的日志错误信息还不够定位是怎么触发的。
目前看比较奇怪的信息是下面两条日志中,table_id=146367 在第一条日志中属于 database_id=80271,但是在第二条日志中属于 database_id=161619。
[2024/06/01 17:05:29.292 +08:00] [WARN] [SchemaSyncService.cpp:309] ["Physically drop table is skip, regions are not totally removed from TiFlash, remain_region_ids=[7596681, 7596676, 7596696, 7596671, 7596691] table_tombstone=0 safepoint=450162004151762944 db_80271.t_146367 database_id=80271 table_id=146367"] [source="keyspace=4294967295"] [thread_id=531]
...
[2024/06/01 17:16:00.023 +08:00] [ERROR] [RaftCommands.cpp:472] ["[region_id=7596696 applied_term=472 applied_index=1218] catch exception: Cannot open file /flash/tidb-data/tiflash-9000/metadata/db_161619/t_146367.sql, errno: 2, strerror: No such file or directory ...
- 6月1日 16点 到 17点左右的 tiflash.log 日志还有保留吗?方便贴上来我查看下当时 tiflash 在处理什么 DDL 操作?
- 或者可以检查下你们业务上有没有有把一个表跨 database 迁移的操作吗?比如
ALTER TABLE db1.tbl RENAME db2.tbl或者ALTER TABLE db1.partitioned_table EXCHANGE PARTITION p1 WITH TABLE db2.non_partitioned_table - 或者在 6.1 日 16点~17点期间,执行过怎么样的 DDL 操作呢?
感觉这种请款多数和资源的关系比较大先观摩大佬
在5月31日做过这种跨库的操作。我找下当天该时段日志,随后上传
我把文件按每10分钟分割了一下。
16_0.log (4.3 MB)
16_1.log (4.1 MB)
16_2.log (23.9 MB)
16_3.log (4.8 MB)
16_4.log (14.5 MB)
16_5.log (9.5 MB)
17_0.log (8.7 MB)
17_1.log (96.9 MB)

[2024/06/01 17:13:32.357 +08:00] [INFO] [SchemaSyncService.cpp:262] ["Detect stale table, database_name=db_80271 table_name=t_146367 database_tombstone=449937201848385538 table_tombstone=0 safepoint=450162177127481344"] [source="keyspace=4294967295"] [thread_id=930]
database_tombstone=449937201848385538 从这个日志看,database_id=80271 的 db 在 2024-05-22 18:36 +0800 CST 这个时间点就被 drop 了。但是 tiflash 还认为 table_id=146367 的表属于这个 db,后续表 table_id=146367 发生变更的时候从磁盘找文件路径不正确。
可以具体描述下 5月31号、 5月22号具体执行过怎么样的跨库 DDL 语句么?
1 个赞
5月22日的已经想不起来了,5月31日的是
alter table YWY_YFK.ZB_XXFPFXZB_004 rename to YWY_YFK_T.ZB_XXFPFXZB_004;
alter table YWY_YFK.ZB_XXFPFXZB_004_MX rename to YWY_YFK_T.ZB_XXFPFXZB_004_MX;
alter table YWY_YFK.ZB_JXFPFX_002 rename to YWY_YFK_T.ZB_JXFPFX_002;
alter table YWY_YFK.ZB_JXFPFX_002_MX rename to YWY_YFK_T.ZB_JXFPFX_002_MX;
alter table YWY_YFK.ZB_JXFPFX_004_MX rename to YWY_YFK_T.ZB_JXFPFX_004_MX;
类似这种,涉及100多张表
刚才核对了一下,迁移的库不涉及tiflash 。也就是它没有被存入tiflash
而引起tiflash中的表,最多是truncate 操作 。
根据表ID查到如下信息
最后的都表名称 YWY_DW.DW_SB_ZZS_XGM_FJS_INFO,这个表一直存在
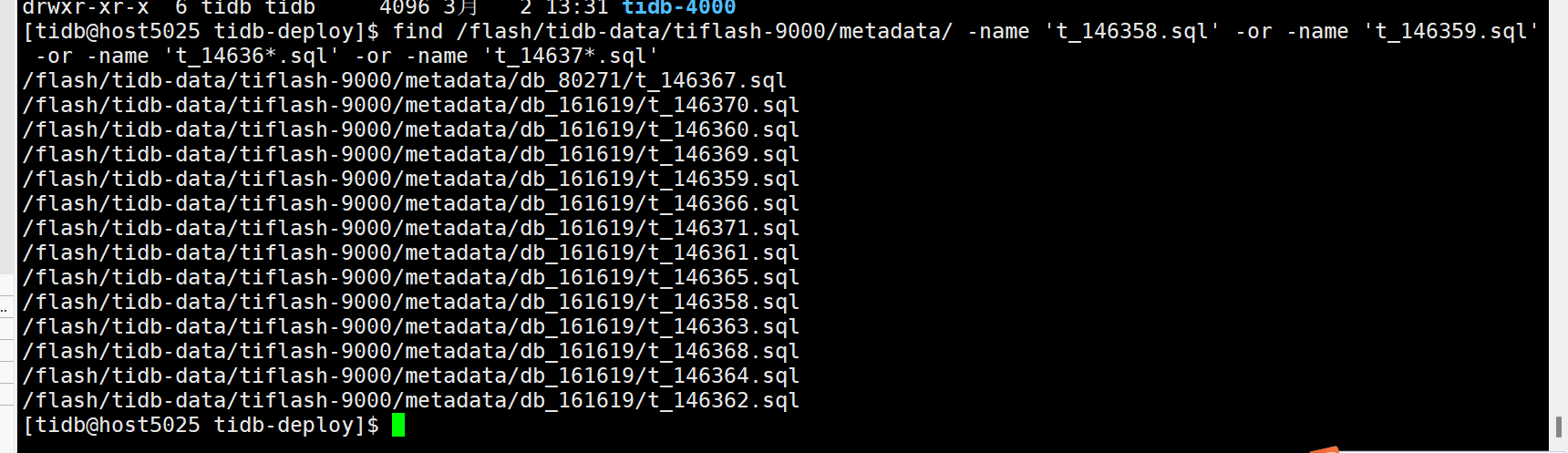
tiflash 节点的数据还保留着么?试下在 6月1日宕机的 tiflash 节点上执行下面的命令,看下文件所在的路径
find /flash/tidb-data/tiflash-9000/metadata/ -name 't_146358.sql' -or -name 't_146359.sql' -or -name 't_14636*.sql' -or -name 't_14637*.sql'
可以试下手动移动一下文件,然后看 tiflash 能不能起来
mv /flash/tidb-data/tiflash-9000/metadata/db_80271/t_146367.sql mv /flash/tidb-data/tiflash-9000/metadata/db_161619/t_146367.sql
2 个赞
复制后,第一次启动失败,然后将所有日志备份后清空,然后第二次启动,启动成功。
感谢大神!
能进一分析这个是如何造成的吗?
大概应该是在分区表中含有空分区的时候,对分区表执行跨 database 的 rename 后,tiflash 的处理逻辑有点问题,导致部分分区没有被移动到正确的 database 目录下。我在尝试造个最小复现 case。
我根据table_id=146367 查到表是 YWY_DW.DW_SB_ZZS_XGM_FJS_INFO
现在不能确认的是是否能够根据database_id 确认数据库就是 YWY_DW ,我查了资料,没有找到根据database_id 确定名称的。
可以通过 tidb 的 http api 拿到所有 database 的 json 信息,里面有每个 database 对应的 database_id
Get schema Information about all db
curl http://{TiDBIP}:10080/schema
现在可以确定 出错的就是 YWY_DW.DW_SB_ZZS_XGM_FJS_INFO 这个库,这个表 ,但是 针对这个库这个表的操作是2024年3月份的事情了,当时是数据库名称为 DW,后来根据命名规范化,将DW,改为了YWY_DW 。
操作方法类似 alter table YWY_YFK.ZB_XXFPFXZB_004 rename to YWY_YFK_T.ZB_XXFPFXZB_004;
1 个赞