【 TiDB 使用环境】生产环境
【 TiDB 版本】
v5.4.3 → v7.1.5
【遇到的问题:问题现象及影响】
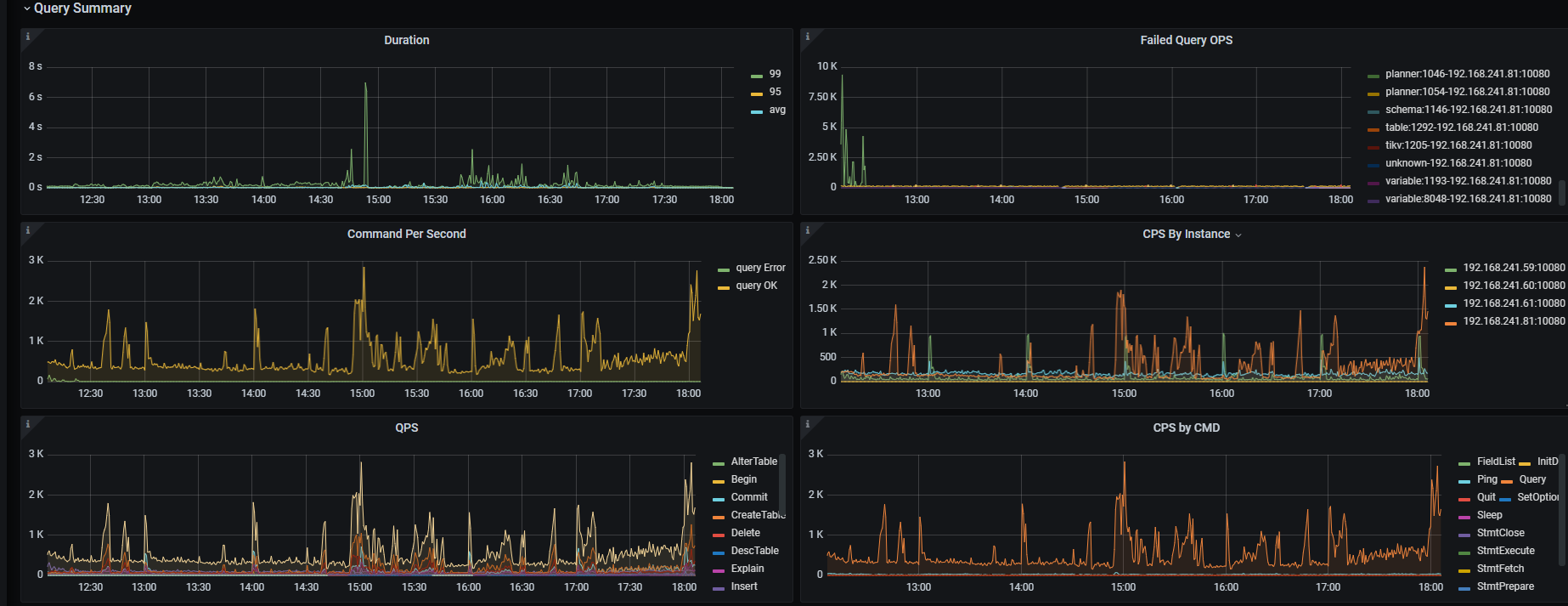
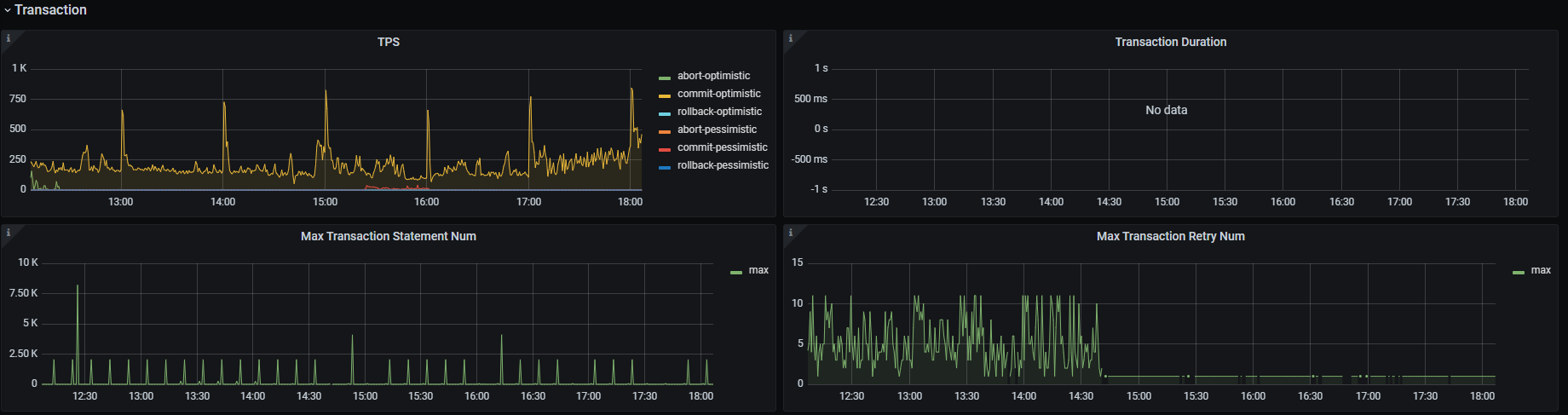
集群升级后数据写入出现大量1205报错 OperationalError: (1205, u’Lock wait timeout exceeded; try restarting transaction’),相较之前总体数据写入速度下降很多
业务场景是:python消费kafka数据写入到tidb,目前有24个消费进程。
现在看着好像:启动少数几个消费进程就不会报错,启多了就会,不确定是不是这样
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
---- 20240528 更新 ----
代码本身确实是有问题,开发优化了代码(kafka分区机制)后,不再有1205冲突的报错了。算是从根本上解决了问题。
但还不理解的是:为啥一样的代码一样的数据库配置,老版本规避了这问题,而升级后出现了,并且没法通过修改配置规避问题。
WalterWj
(王军 - PingCAP)
2
讲不好和 tidb 升级无关,数据库重启 代码上可能没有处理类似这种场景,异常的时候就集中写入 冲突明显也不是不可能。。。
数据库重启,对代码上来说不就相当于重启下服务吗,我们也经常重启tidb,还是TIDB版本间的问题,跟代码没关
是的,啥机制不一样啊
老板本没问题,同样的代码同样的数据库配置,升级后就有了问题 
WalterWj
(王军 - PingCAP)
7
心里话,这玩意要看得好好看监控 先看一波了,可不是一会能看完的 麻了。 
问一下 现在问题解决了么?比如消费是否能消费过来。。。
恩已经解决了, 代码优化后没有报错了已经。
其实昨天2个消费者也能消费过来。
只是出现这问题有点不解~
WalterWj
(王军 - PingCAP)
9
先这样吧,后面我弄个文章写个类似升级前后的性能分析吧。
1 个赞
system
(system)
关闭
10
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。