辛苦大家帮忙看看吧,如果是mysql,这种情况理论上是只会扫描100条数据,不清楚tidb为什么会扫描10+w的key
走主键可能会只扫描100行,如果不是主键limit还会扫描很多行,只是返回的时候少传输数据了吧。
不知我理解的对不对
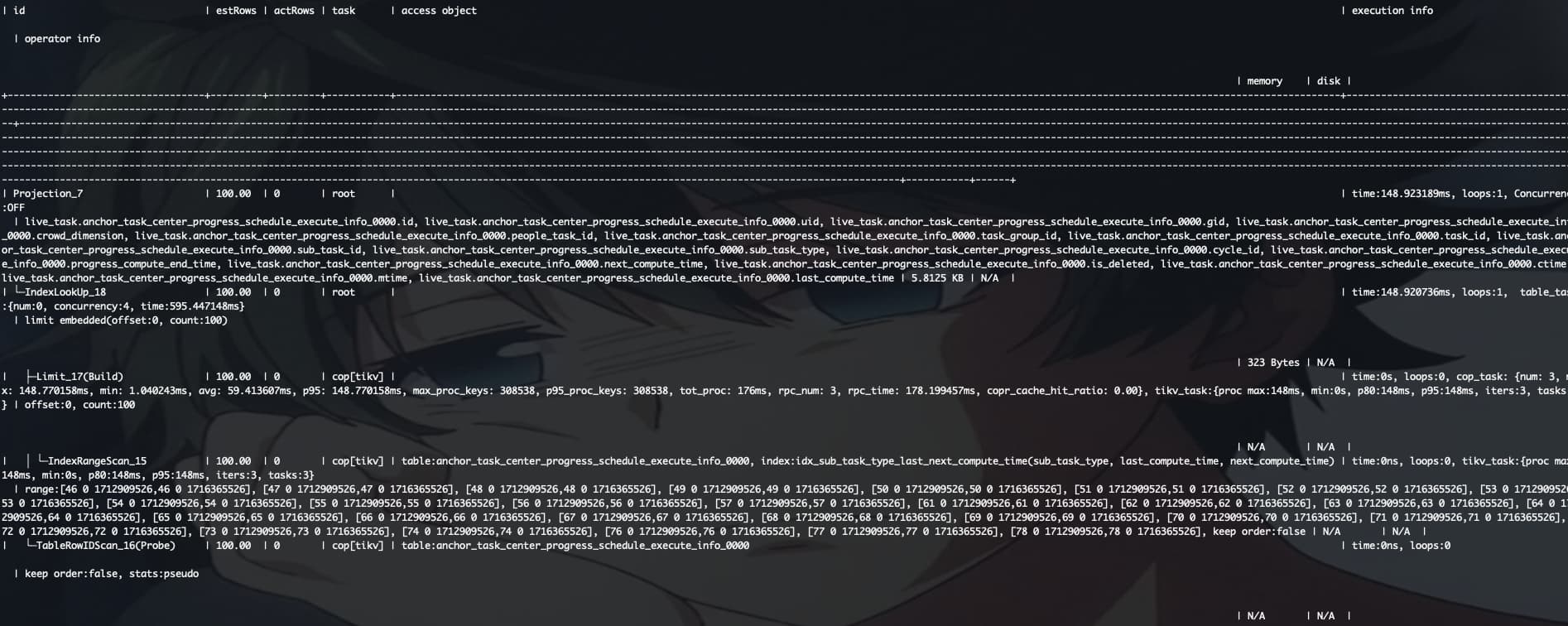
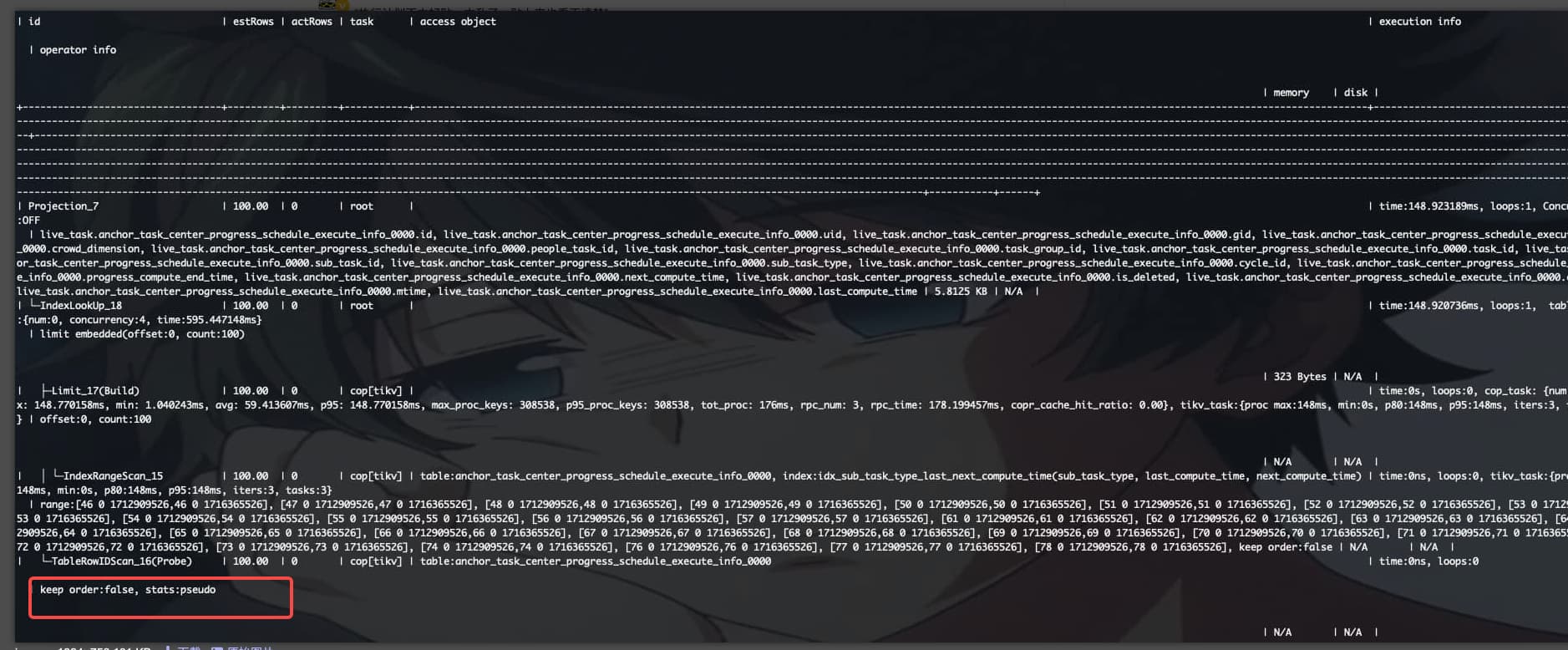
但是执行计划确实是在cop[tikv]有limit算子,并且是build,TableRowIDScan算子确实是只执行了100个key,主要是不理解idx_sub_task_type_last_next_compute_time索引扫描了那么多key
执行计划不太好贴,太乱了,贴上来也看不清楚
IndexLookUp_18
----Limit_17
---------IndexRangeScan_15
----TableRowIDScan_16
大概是这样的
“执行计划不太好贴,太乱了,贴上来也看不清楚”
可以直接上传截图或者TXT 文件
1 个赞
是limit算子
我analyze之后,对查询也没有优化
看你发的这个执行计划 ,感觉没啥问题。。。就是索引扫 >> 回表 >> limit 优化,结束了。。。
我也感觉执行计划没问题,就是扫描的key太多了,慢日志里记录的key ![]()
意思是会把索引数据全部扫描出来,再limit?这就是我想问的问题
这个sql很简单,检查下是不是索引没加完整啊, where条件的都加上索引。 如果都加了索引,按道理只会扫码存在记录的行
慢查询里面也是这个执行计划吗?
我看你执行这个sql100+ms。这个速度应该可以接受吧?
我现在怀疑你慢日志里面的执行计划不是这个,导致执行时间很长。
1 个赞
慢查询阈值是150ms,是可以接受,只是想搞清楚原因 ![]()
eplain analyze 能贴个文本全的吗
找到时间长的那个执行计划才好找到原因。
因为
1,不确定这两个执行计划是一致的。
2,那个执行时间长的执行计划里面有很多信息可以定位是那个环节慢了。
仅看没问题的这个执行计划,是看不出问题的。
时间没有很长(只是比较纠结扫描的key数量,就是慢在了kv环节),就是100多ms,只是按理解来说,不应该会扫描那么多key,提供的analyze截图里应该能看到扫描的key呀
看看是不是走的IndexFullScan算子,这个算子本质上是索引的“全表扫描”;
一般都是先扫描得到中间结果,然后再limit,除非你的limit本身可以下推到某一个表,然后再关联。