反馈一个现象:
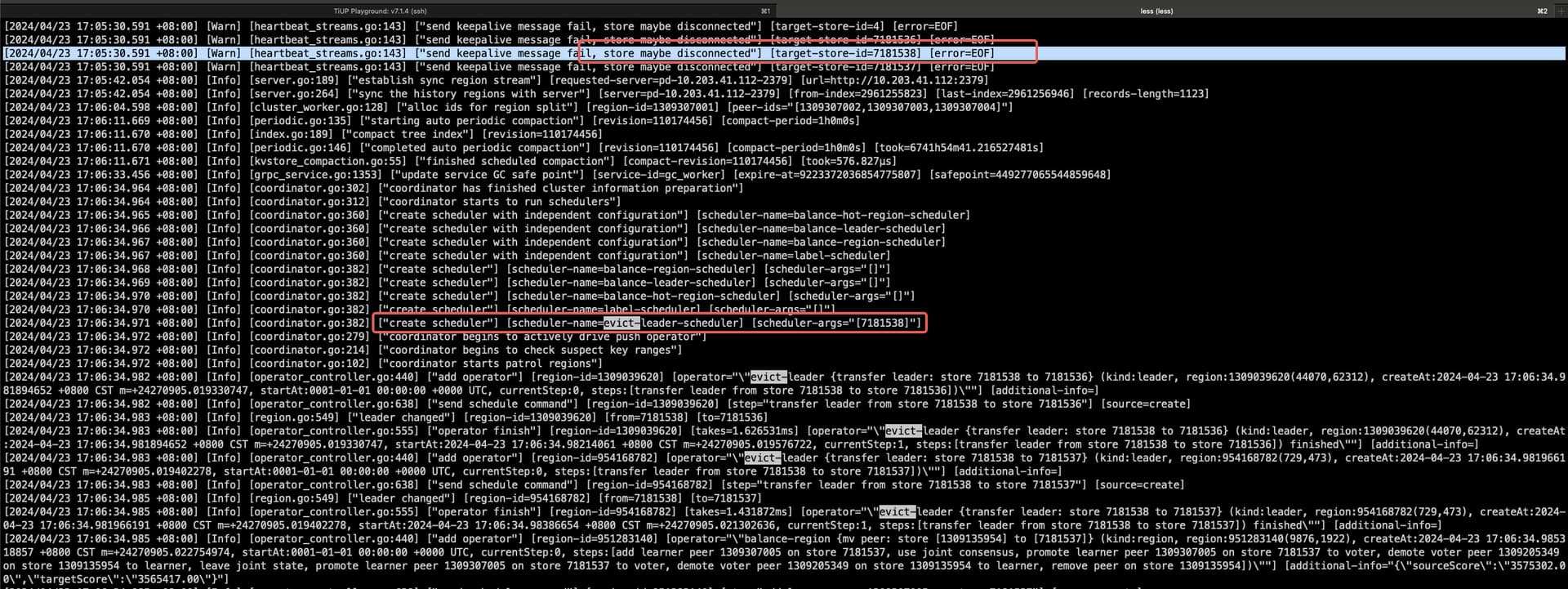
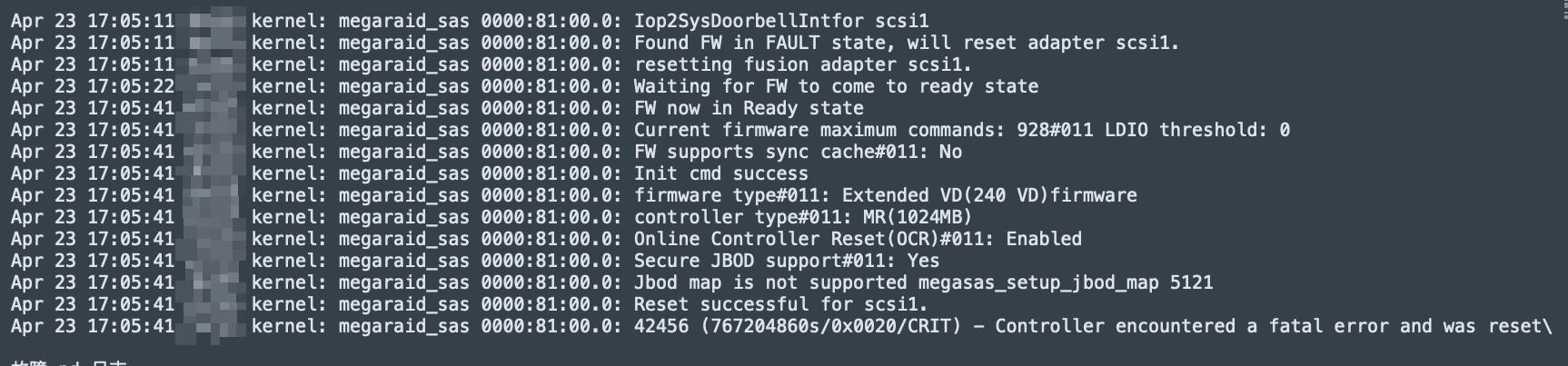
tidb 和 pd 节点混布,tidb 节点的磁盘遇到了一个 kernel 级别的故障(此时也会影响 pd),使用率直接到了 100%,然后 pd 节点开始切换,但此时 pd 节点并未意识到是自己慢,而且在下面随机(不确定啥规则)驱逐了一个 tikv 节点的所有 leader

这个问题的根因是磁盘的 kernel 问题,不过 pd 这个感觉是误切,因为 tikv 不慢,而是 tidb 和 pd 混布的磁盘问题
kernel 报错
故障 pd 日志
另外一个 pd

咨询官方人员得知 5.2.0 后有个自动检测慢 tikv 的机制
https://docs.pingcap.com/zh/tidb/stable/pd-scheduling-best-practices?_gl=1*mve8gf*_ga*MTM5NDYzMjc5Mi4xNzEwNDk0NTY5*_ga_3JVXJ41175*MTcxMzg2NzYwMi4xNDEuMC4xNzEzODY3NjA0LjU4LjAuMA…#tikv-%E8%8A%82%E7%82%B9%E6%95%85%E9%9A%9C%E5%A4%84%E7%90%86%E7%AD%96%E7%95%A5