我在这里抛砖引玉一下。我们当前使用 Vector 特性在一个具体的 RAG 场景上。
RAG stands for retrieval-augmented generation. 也就是我们说的 检索-增强-生成 的这一类的 Apps,这也是当前 AI 领域最常见的一种 App 的构造方法,而被广泛的应用了。
举个例子,如果大家用过 ChatGPT,就会被它一本正经地胡说八道的能力所折服。这被称为 LLM 的 “幻觉”,是它的注意力丧失的一个情形。
那我们可以如何简单的解决这个问题呢?答案就是 RAG。我们可以先对这个问题进行一些可靠材料的 检索 ,事先给到 LLM 一些可靠的上下文作为 增强,随后再让它 生成 新的内容。这可以显著提高回答的准确率。
我们这里有一个更具体的例子,我们正在做一个 tidb.ai,希望使用大模型,和我们自己的文档去回答关于 TiDB 的问题。那就可以得到以下步骤:
- 用户提出一个关于 TiDB 问题
- 根据问题搜索相关 TiDB 文档
- 使用文档填充 LLM 的 Prompt
- 让 LLM 生成我们需要格式的输出
这里就有一个问题了,如何根据问题搜索相关 TiDB 的文档?这就要提到另一个 AI 的功能了,叫作 Embedding。它会生成一段文字的特征向量,我们可以比对两段文字的 Embedding Vector 距离,距离越近,我们就可以认为这两段文字越相关。因此我们可以将以上流程优化如下:
- 将 TiDB 文档事先进行 Embedding,将文字和其对应 Vector 存储在 TiDB 中
- 用户提出一个关于 TiDB 问题,进行 Embedding,使用 TiDB 中向量的距离计算,搜索 TiDB 中最相关的几个文档
- 使用文档填充 LLM 的 Prompt
- 让 LLM 生成我们需要格式的输出
这也是我们为什么要做 Vector 的其中一个原因。另外,如何生成 Embedding,怎么去 Retrieve 都是一个优化的点。这也是我们正在努力的部分。不过这里不可或缺的就是 TiDB 的 Vector 功能了。给大家放一张如果我们使用外部的 Vector 数据库,对比 TiDB 内嵌 Vector 之间的对比图。
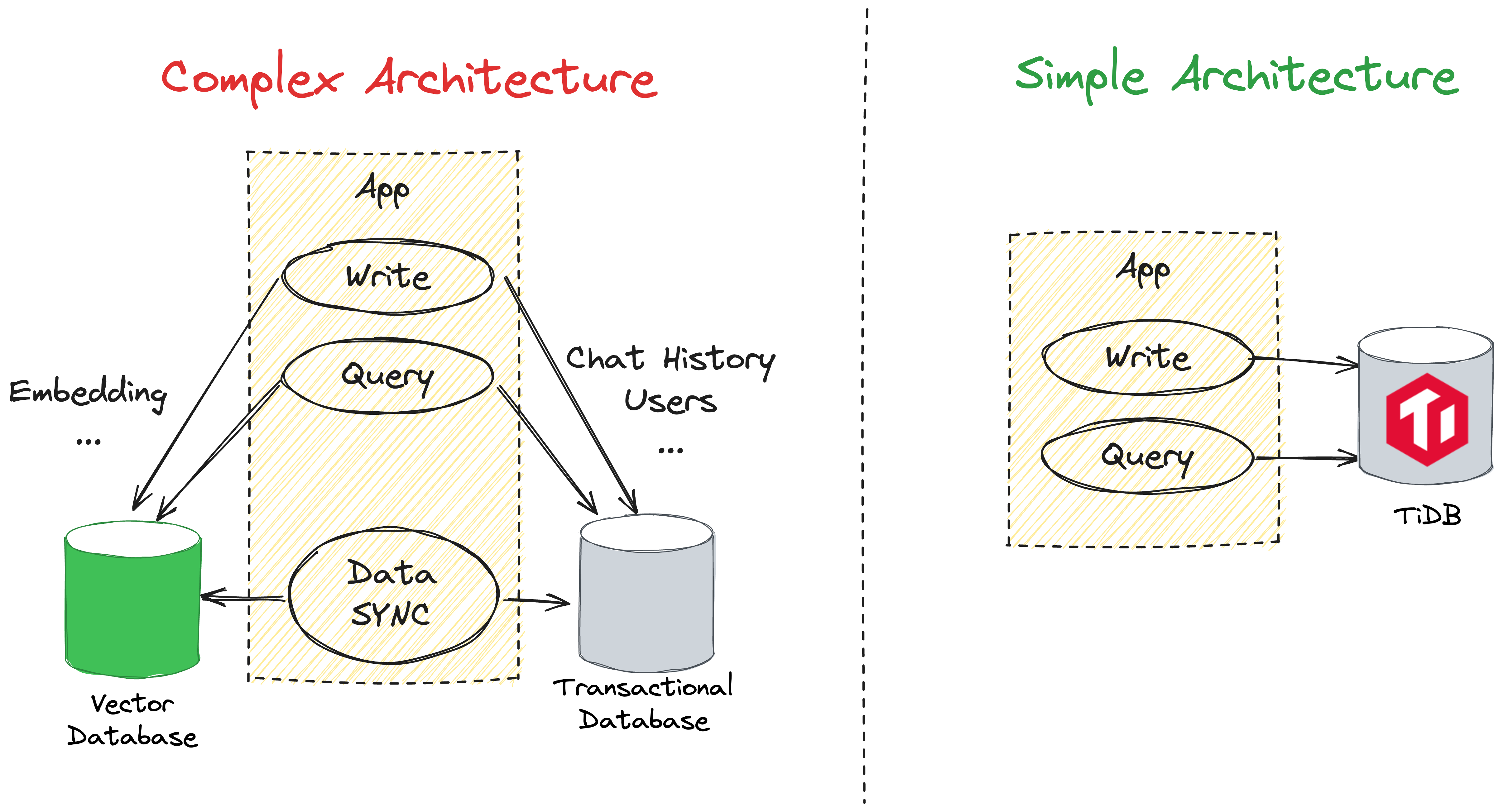
当然,这只是 Vector 的其中一个用法,期待大家更多的使用方法。