【 TiDB 版本】v5.2.3 ARM
早上发下集群pd\tidb 宕了,检查151 pd节点日志4月15日晚22:16左右开始出现问题,类似报错: [etcdutil.go:122] [“load from etcd meet error”] [key=/pd/7024798609142208243/leader] [error=“[PD:etcd:ErrEtcdKVGet]context deadline exceeded”] 重新启动集群 151 pd节点无法启动
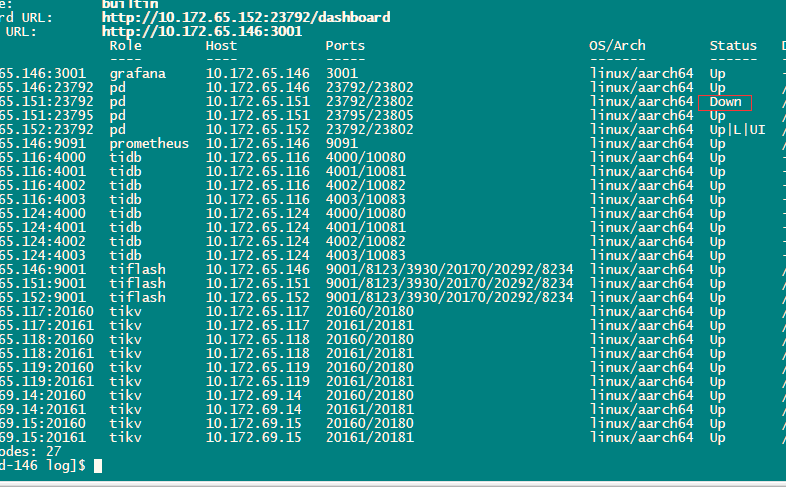
扩缩容处理 或者提供完整的 pd.log 我瞅瞅有没有有用信息。

重新拉起来后 临时扩了一个,原来的等着排查完再缩容
pd-ctl 进去,敲下 member 里面信息文本方式发出来我瞅瞅呢。
{
“header”: {
“cluster_id”: 7024798609142208243
},
“members”: [
{
“name”: “pd-10.172.65.152-23792”,
“member_id”: 9357444448847789453,
“peer_urls”: [
“http://10.172.65.152:23802”
],
“client_urls”: [
“http://10.172.65.152:23792”
],
“deploy_path”: “/tidb/pd2/bin”,
“binary_version”: “v5.2.3”,
“git_hash”: “02139dc2a160e24215f634a82b943b2157a2e8ed”
},
{
“name”: “pd-10.172.65.151-23795”,
“member_id”: 11468259817903508096,
“peer_urls”: [
“http://10.172.65.151:23805”
],
“client_urls”: [
“http://10.172.65.151:23795”
],
“deploy_path”: “/tidb/pd2_a/bin”,
“binary_version”: “v5.2.3”,
“git_hash”: “02139dc2a160e24215f634a82b943b2157a2e8ed”
},
{
“name”: “pd-10.172.65.151-23792”,
“member_id”: 12415486320424082229,
“peer_urls”: [
“http://10.172.65.151:23802”
],
“client_urls”: [
“http://10.172.65.151:23792”
],
“deploy_path”: “/tidb/pd2/bin”,
“binary_version”: “v5.2.3”,
“git_hash”: “02139dc2a160e24215f634a82b943b2157a2e8ed”
},
{
“name”: “pd-10.172.65.146-23792”,
“member_id”: 14508203407204661733,
“peer_urls”: [
“http://10.172.65.146:23802”
],
“client_urls”: [
“http://10.172.65.146:23792”
],
“deploy_path”: “/tidb/pd2/bin”,
“binary_version”: “v5.2.3”,
“git_hash”: “02139dc2a160e24215f634a82b943b2157a2e8ed”
}
],
“leader”: {
“name”: “pd-10.172.65.152-23792”,
“member_id”: 9357444448847789453,
“peer_urls”: [
“http://10.172.65.152:23802”
],
“client_urls”: [
“http://10.172.65.152:23792”
],
“deploy_path”: “/tidb/pd2/bin”,
“binary_version”: “v5.2.3”,
“git_hash”: “02139dc2a160e24215f634a82b943b2157a2e8ed”
},
“etcd_leader”: {
“name”: “pd-10.172.65.152-23792”,
“member_id”: 9357444448847789453,
“peer_urls”: [
“http://10.172.65.152:23802”
],
“client_urls”: [
“http://10.172.65.152:23792”
],
“deploy_path”: “/tidb/pd2/bin”,
“binary_version”: “v5.2.3”,
“git_hash”: “02139dc2a160e24215f634a82b943b2157a2e8ed”
}
}
坐等大佬解答
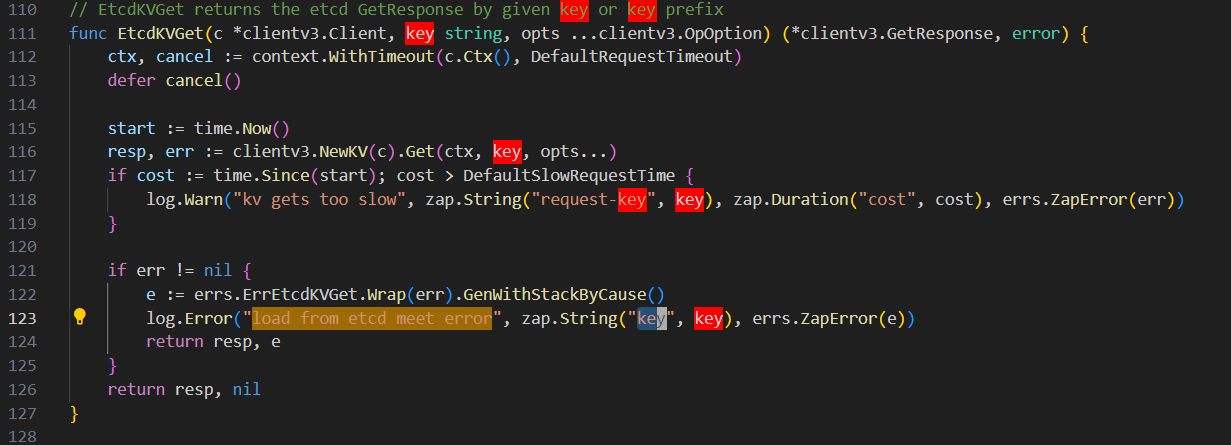
就是etcd的client访问leader失败。超时了。
[2024/04/16 05:17:04.317 +08:00] [WARN] [etcdutil.go:117] ["kv gets too slow"] [request-key=/pd/7024798609142208243/leader] [cost=10.000469751s] [error="context deadline exceeded"]
[2024/04/16 05:17:04.317 +08:00] [ERROR] [etcdutil.go:122] ["load from etcd meet error"] [key=/pd/7024798609142208243/leader] [error="[PD:etcd:ErrEtcdKVGet]context deadline exceeded"]
[2024/04/16 05:17:04.317 +08:00] [ERROR] [member.go:166] ["getting pd leader meets error"] [error="[PD:etcd:ErrEtcdKVGet]context deadline exceeded"]
网络你应该也检查过了,要么就抓包看看。
我也遇到这这个问题,我比你惨,3个PD挂掉了俩个,最后通过备份回复pd数据。主要报错的表现形式是etcd数据不一致了。
网络当时没看 ,如果是网络问题当时导致down了后,为啥后面151这个节点的拉不起来了
那不应该啊 ![]() ,我看日志是获取 member list 不行,但是手动又可以。你试试手动掉这个 API 有内容么:
,我看日志是获取 member list 不行,但是手动又可以。你试试手动掉这个 API 有内容么:
2024/04/16 10:04:56.799 log.go:85: [warning] etcdserver: [could not get cluster response from http://10.172.65.146:23802: Get "http://10.172.65.146:23802/members": dial tcp 10.172.65.146:2380
2: connect: connection refused]
[2024/04/16 10:04:56.799 +08:00] [ERROR] [etcdutil.go:70] ["failed to get cluster from remote"] [error="[PD:etcd:ErrEtcdGetCluster]could not retrieve cluster information from the given URLs"]
[2024/04/16 10:04:58.823 +08:00] [INFO] [stream.go:250] ["set message encoder"] [from=ac4cab0742995b35] [to=ac4cab0742995b35] [stream-type="stream Message"]
curl http://10.172.65.146:23802/members
[{“id”:9357444448847789453,“peerURLs”:[“http://10.172.65.152:23802”],“name”:“pd-10.172.65.152-23792”,“clientURLs”:[“http://10.172.65.152:23792”]},{“id”:11468259817903508096,“peerURLs”:[“http://10.172.65.151:23805”],“name”:“pd-10.172.65.151-23795”,“clientURLs”:[“http://10.172.65.151:23795”]},{“id”:12415486320424082229,“peerURLs”:[“http://10.172.65.151:23802”],“name”:“pd-10.172.65.151-23792”,“clientURLs”:[“http://10.172.65.151:23792”]},{“id”:14508203407204661733,“peerURLs”:[“http://10.172.65.146:23802”],“name”:“pd-10.172.65.146-23792”,“clientURLs”:[“http://10.172.65.146:23792”]}]
![]() 那就有点懵圈了,讲道理 pd 这部分逻辑和你手动 curl 没有区别的。
那就有点懵圈了,讲道理 pd 这部分逻辑和你手动 curl 没有区别的。
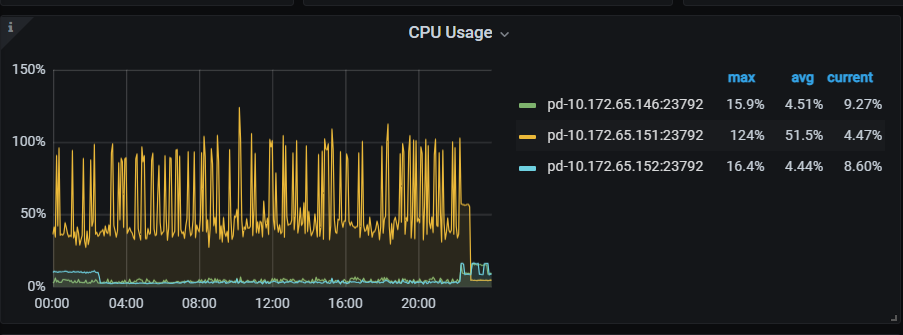
这个时间应该是我手工拉起集群的前后,开始的时候先start的一直不行,看了pd的进程还在(151节点的没看),就stop cluster后又start才起来的,之后扩容了一个pd。 151:28792这个原来的pd就一直起不来,昨晚22:16的时候pd日志开始有报错,之前是151节点是leader
有解决了嘛?
看来tidb还得买原厂服务
坐等 H5N1 用户最新回复
等着大佬献计献策。。。。。。。。