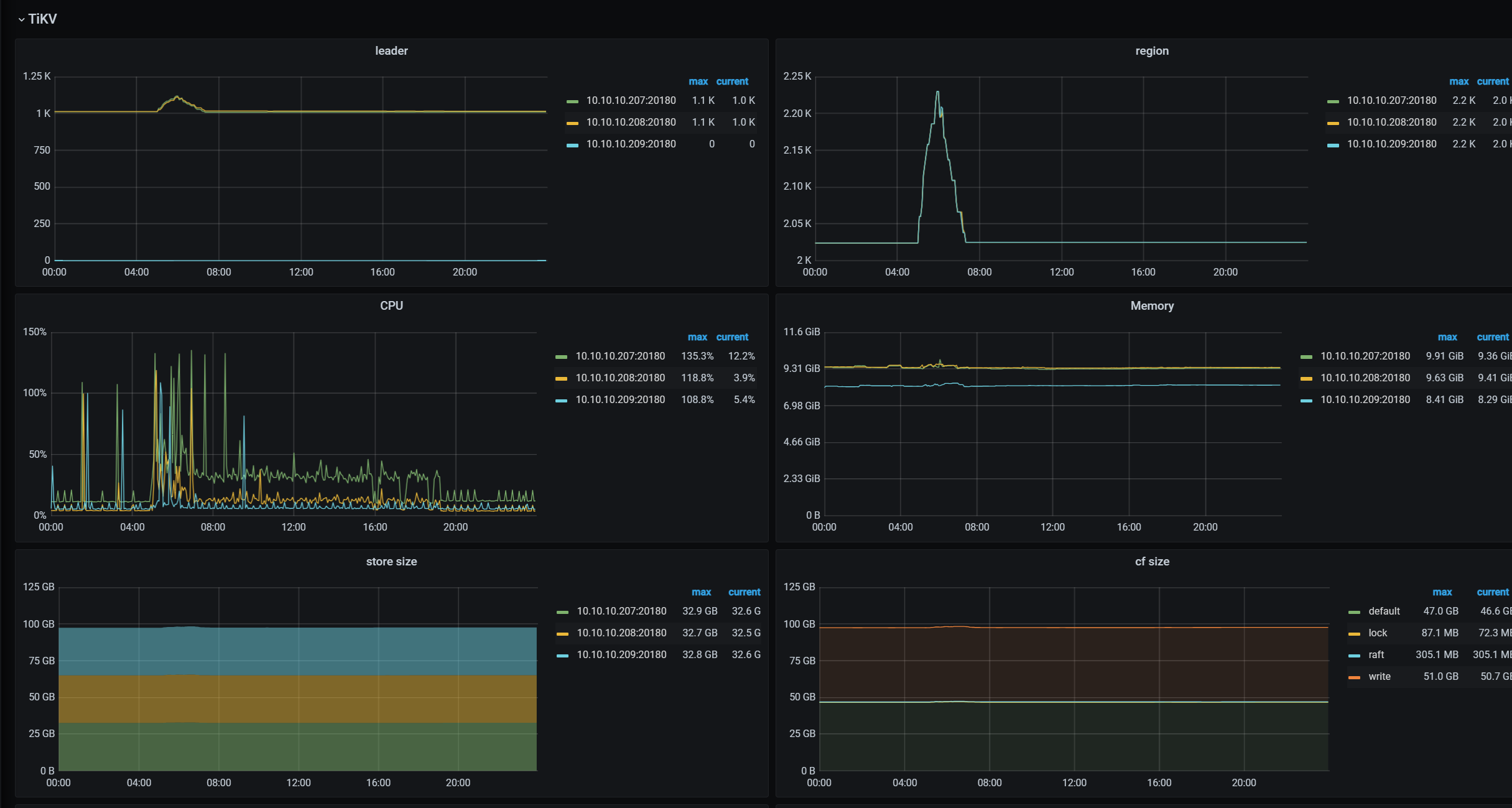
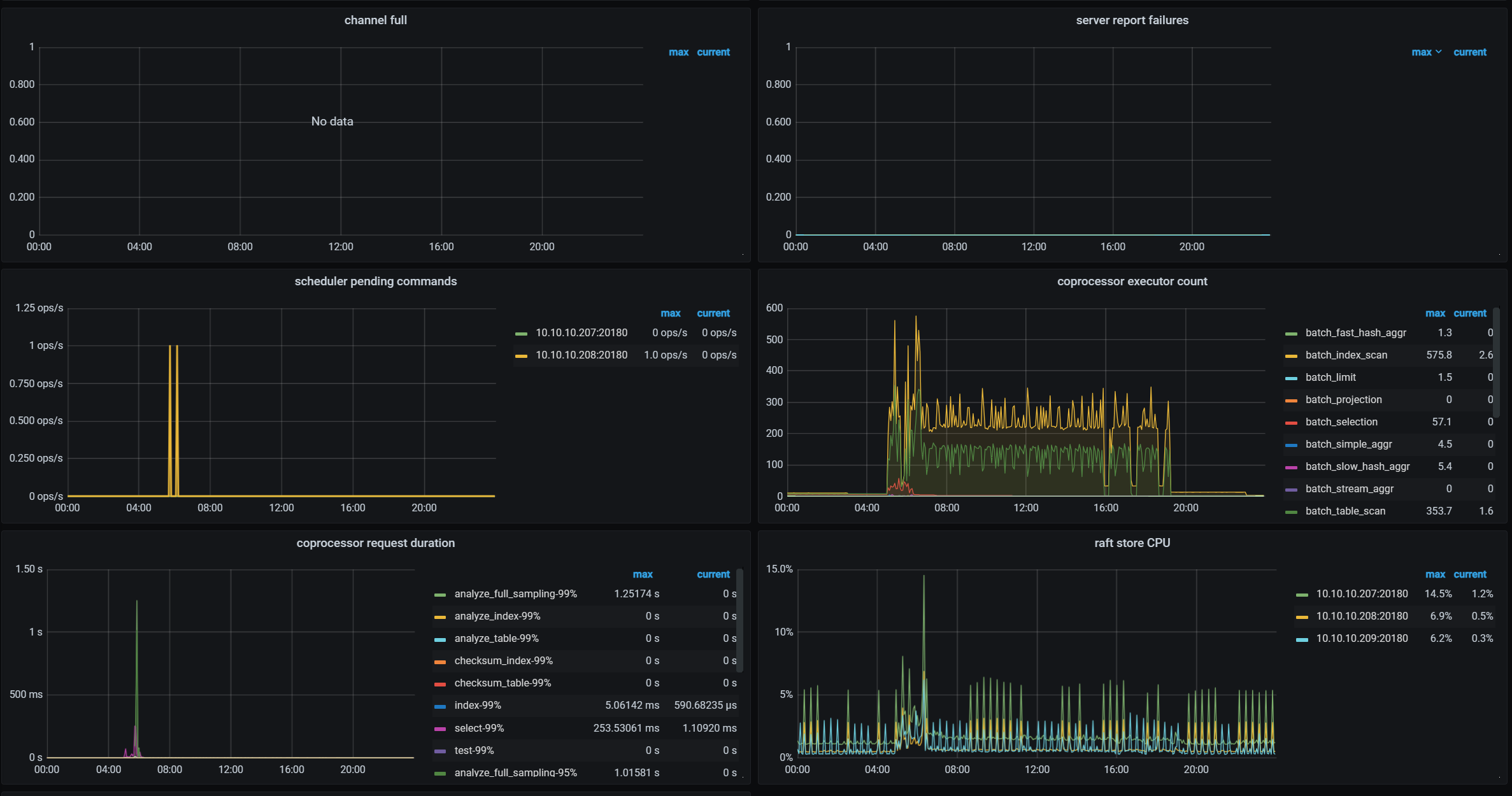
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】7.51
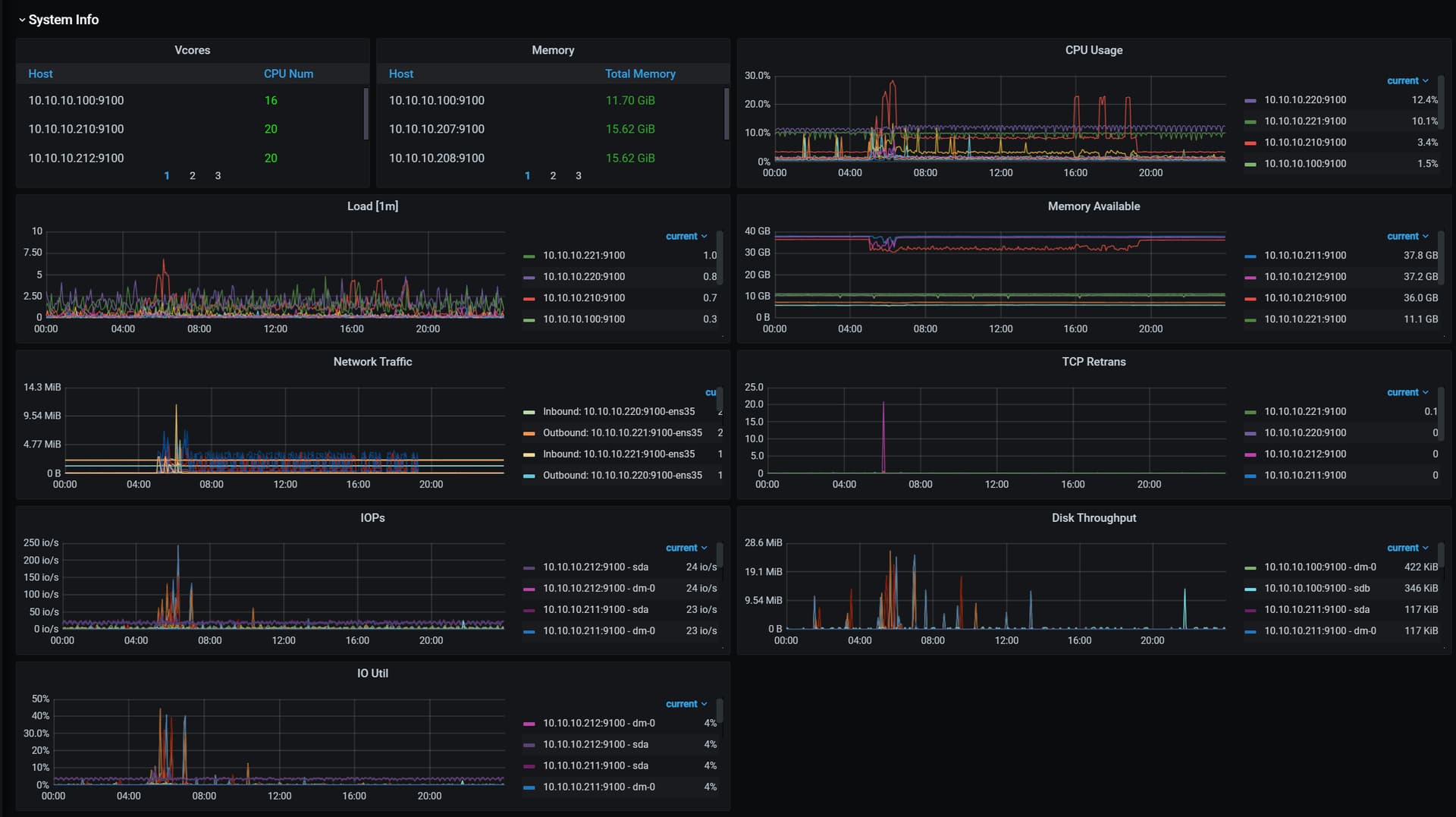
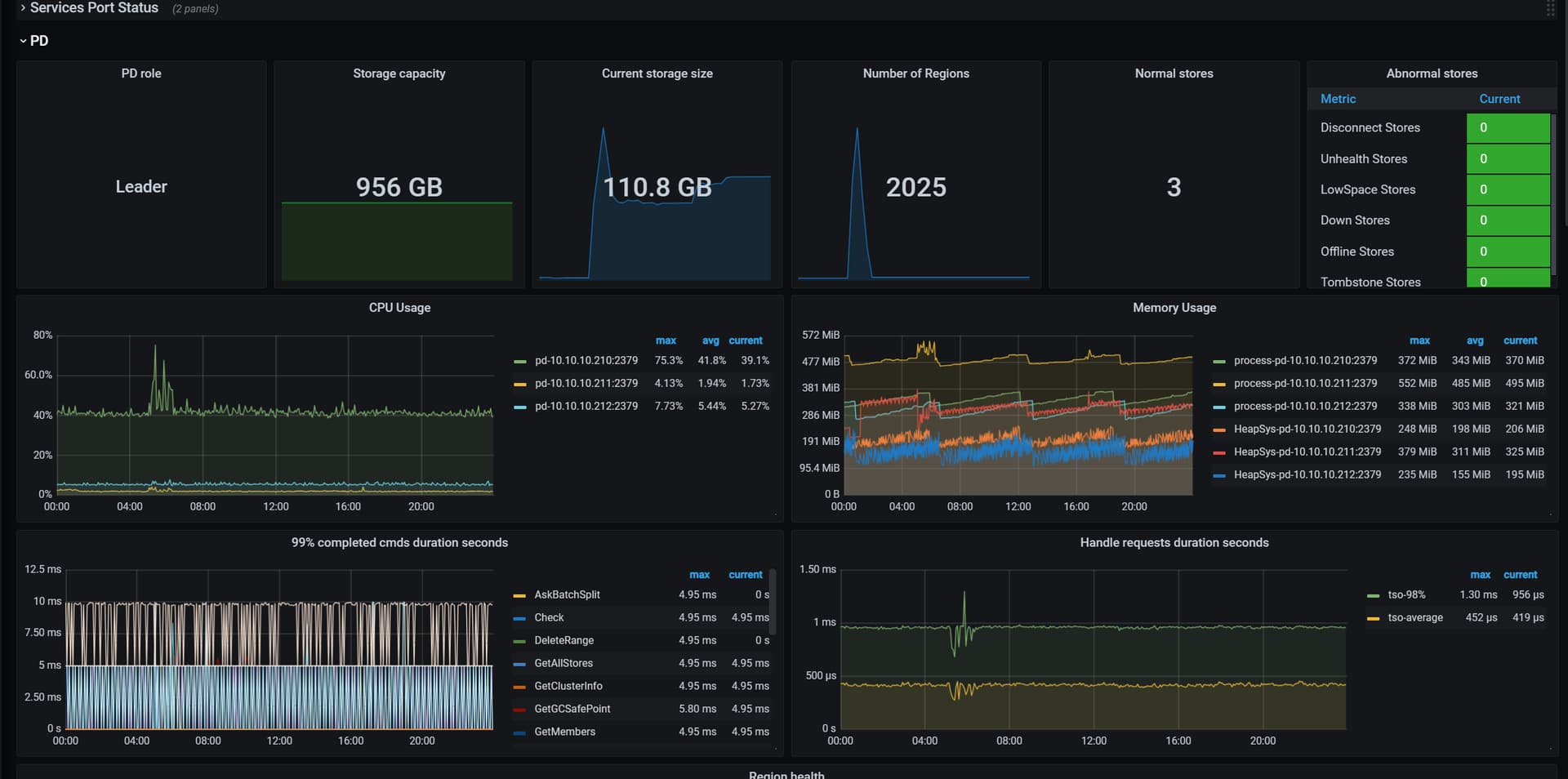
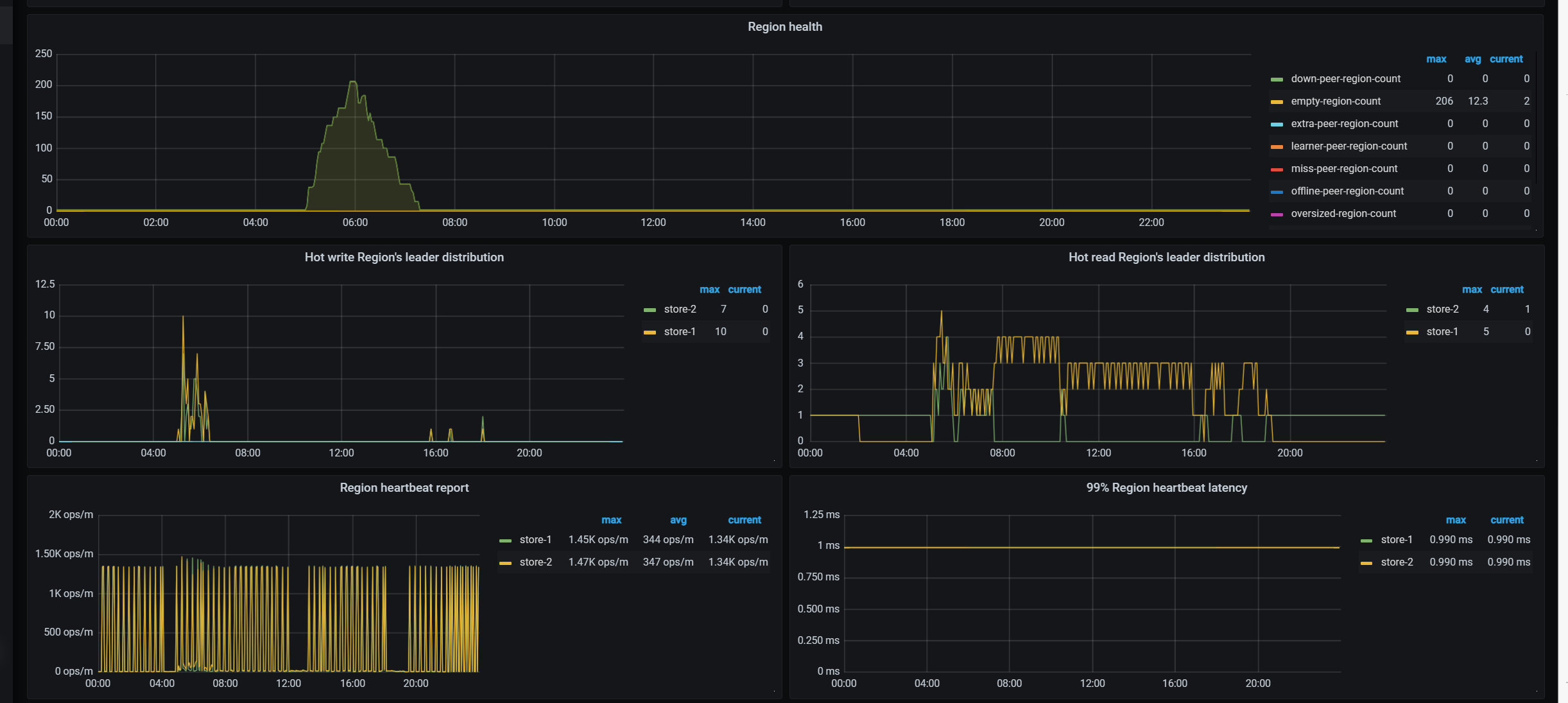
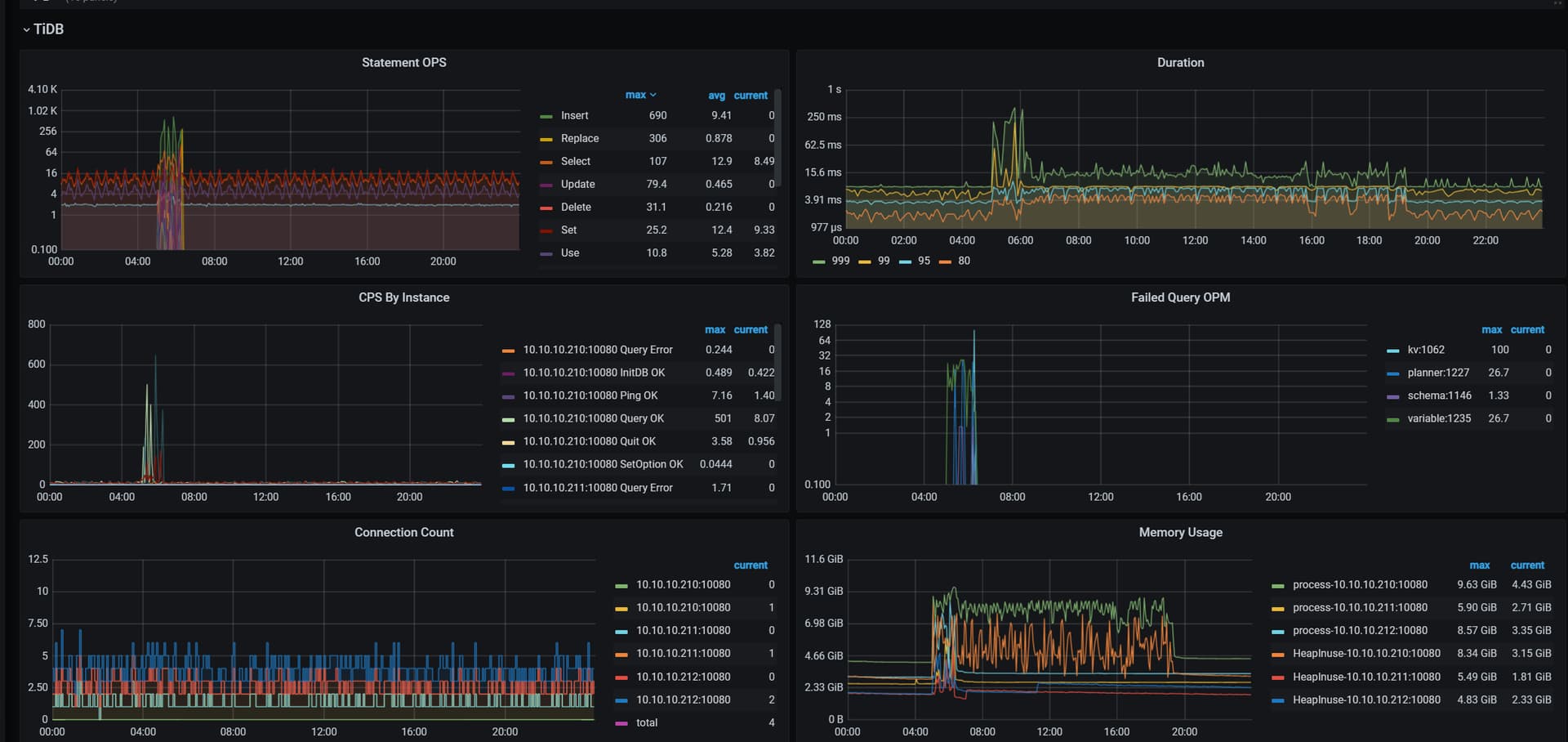
【复现路径】中度压力的长期压力测试
【遇到的问题:问题现象及影响】
4月13日3点多业务那边压测故障中断了,数据库一堆报错
tikv.zip (21.8 KB)
tidb.zip (4.2 KB)
pd.zip (2.4 KB)
一些看不懂的错误:
tidb相关:
[2024/04/13 04:02:57.080 +08:00] [Error] [pd_service_discovery.go:534] ["[pd] failed to update member"] [urls="[http://192.168.19.205:2379,http://192.168.19.206:2379,http://192.168.19.207:2379]"] [error="[PD:client:ErrClientGetMember]get member failed"]
[2024/04/13 04:03:51.257 +08:00] [Error] [domain.go:1894] ["update bindinfo failed"] [error="[tikv:9005]Region is unavailable"]
[2024/04/13 04:03:53.263 +08:00] [Error] [domain.go:901] ["reload schema in loop failed"] [error="[tikv:9005]Region is unavailable"]
[2024/04/13 04:04:10.490 +08:00] [Error] [domain.go:1713] ["load privilege failed"] [error="[tikv:9005]Region is unavailable"]
[2024/04/13 04:04:33.392 +08:00] [Error] [domain.go:901] ["reload schema in loop failed"] [error="[tikv:9005]Region is unavailable"]
[2024/04/13 04:04:40.521 +08:00] [Error] [2pc.go:1544] ["Async commit/1PC result undetermined"] [conn=4020837744] [session_alias=] [error="region unavailable"] [rpcErr="rpc error: code = Unavailable desc = keepalive ping failed to receive ACK within timeout"] [txnStartTS=449040128571081007]
[2024/04/13 04:04:40.522 +08:00] [Error] [conn.go:1132] ["result undetermined, close this connection"] [conn=4020837744] [session_alias=] [error="previous statement: update clerk_term_daily_report set all_clerk_paid_chances=0.000000000000, all_rdc_paid_chances=0.000000000000, clerk_cancel_chances=0, clerk_cancel_ticket_cnt=0, clerk_canceled_chances=0, clerk_canceled_ticket_cnt=0, clerk_paid_amt=0.00, clerk_paid_ticket_cnt=0, rdc_cancel_chances=0, rdc_cancel_ticket_cnt=0, rdc_paid_amt=0.00, rdc_paid_ticket_cnt=0, rdc_withdrawed_amt=0, sale_chances=1476, sale_ticket_cnt=1476, withdraw_amt=0, withdrawed_amt=0 where term_id=2097411 and rpt_date='2024-04-13' and game_id=200 and clerk_id=42004: [global:2]execution result undetermined"]
[2024/04/13 04:05:11.525 +08:00] [Error] [domain.go:1894] ["update bindinfo failed"] [error="[tikv:9005]Region is unavailable"]
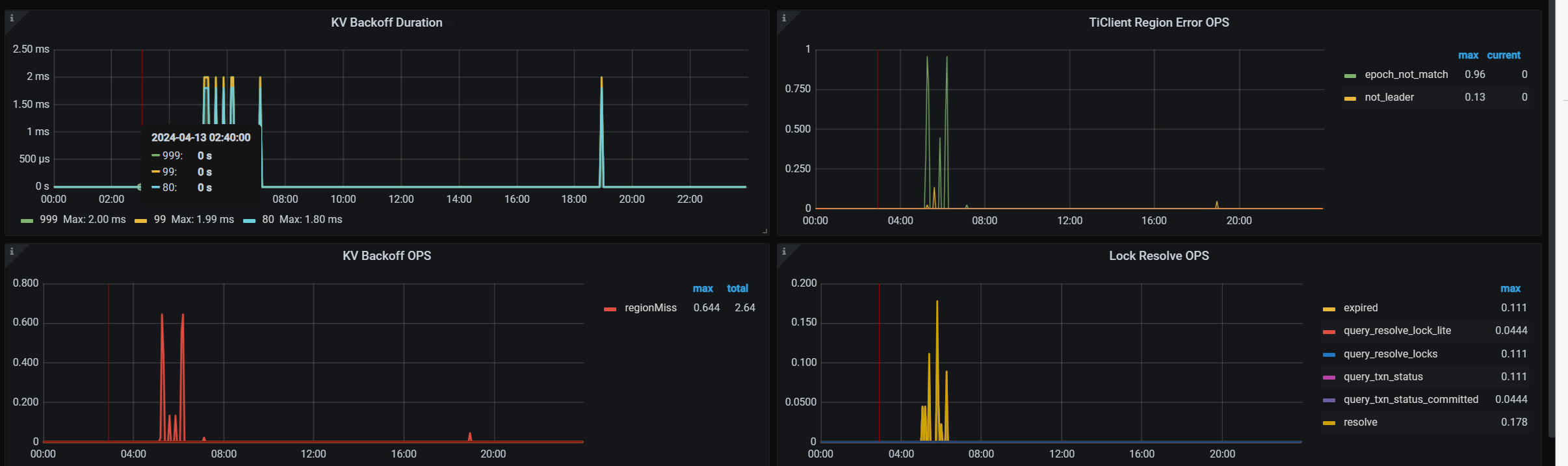
pd组件:
[2024/04/13 04:02:41.920 +08:00] [Error] [etcdutil.go:157] ["load from etcd meet error"] [key=/pd/7330093184493721719/gc/safe_point] [error="[PD:etcd:ErrEtcdKVGet]context deadline exceeded: context deadline exceeded"]
[2024/04/13 04:02:43.218 +08:00] [Error] [etcdutil.go:157] ["load from etcd meet error"] [key=/pd/7330093184493721719/timestamp] [error="[PD:etcd:ErrEtcdKVGet]context deadline exceeded: context deadline exceeded"]
[2024/04/13 04:02:43.224 +08:00] [Error] [middleware.go:217] ["redirect but server is not leader"] [from=pd-192.168.19.205-2379] [server=pd-192.168.19.205-2379] [error="[PD:apiutil:ErrRedirect]redirect failed"]
[2024/04/13 04:03:13.285 +08:00] [Error] [cluster.go:2047] ["get members error"] [error="[PD:etcd:ErrEtcdMemberList]context deadline exceeded: context deadline exceeded"]
tikv组件
[2024/04/13 04:02:48.599 +08:00] [Error] [kv.rs:781] ["KvService::batch_raft send response fail"] [err=RemoteStopped] [thread_id=0x5]
[2024/04/13 04:02:48.599 +08:00] [Error] [kv.rs:781] ["KvService::batch_raft send response fail"] [err=RemoteStopped] [thread_id=0x5]
[2024/04/13 04:02:48.599 +08:00] [Error] [kv.rs:781] ["KvService::batch_raft send response fail"] [err=RemoteStopped] [thread_id=0x5]
[2024/04/13 04:02:48.659 +08:00] [Error] [kv.rs:774] ["dispatch raft msg from gRPC to raftstore fail"] [err=Grpc(RpcFinished(None))] [thread_id=0x5]
[2024/04/13 04:02:48.659 +08:00] [Error] [kv.rs:781] ["KvService::batch_raft send response fail"] [err=RemoteStopped] [thread_id=0x5]
[2024/04/13 04:02:48.672 +08:00] [Error] [kv.rs:956] ["batch_commands error"] [err="RpcFinished(Some(RpcStatus { code: 0-OK, message: \"\", details: [] }))"] [thread_id=0x5]
[2024/04/13 04:02:48.672 +08:00] [Error] [kv.rs:956] ["batch_commands error"] [err="RpcFinished(Some(RpcStatus { code: 0-OK, message: \"\", details: [] }))"] [thread_id=0x5]
[2024/04/13 04:02:48.672 +08:00] [Error] [util.rs:496] ["request failed, retry"] [err_code=KV:Pd:Grpc] [err="Grpc(RpcFailure(RpcStatus { code: 4-DEADLINE_EXCEEDED, message: \"Deadline Exceeded\", details: [] }))"] [thread_id=0x5]
[2024/04/13 04:02:48.731 +08:00] [Error] [raft_client.rs:585] ["connection aborted"] [addr=192.168.19.206:20161] [receiver_err="Some(RpcFailure(RpcStatus { code: 14-UNAVAILABLE, message: \"keepalive watchdog timeout\", details: [] }))"] [sink_error="Some(RpcFinished(Some(RpcStatus { code: 14-UNAVAILABLE, message: \"keepalive watchdog timeout\", details: [] })))"] [store_id=2] [thread_id=0x5]
[2024/04/13 04:02:48.733 +08:00] [Error] [kv.rs:956] ["batch_commands error"] [err="RpcFinished(Some(RpcStatus { code: 0-OK, message: \"\", details: [] }))"] [thread_id=0x5]
[2024/04/13 04:02:48.772 +08:00] [Error] [raft_client.rs:904] ["connection abort"] [addr=192.168.19.206:20161] [store_id=2] [thread_id=0x5]
[2024/04/13 04:02:48.790 +08:00] [Error] [kv.rs:774] ["dispatch raft msg from gRPC to raftstore fail"] [err=Grpc(RpcFinished(None))] [thread_id=0x5]
[2024/04/13 04:02:48.805 +08:00] [Error] [kv.rs:781] ["KvService::batch_raft send response fail"] [err=RemoteStopped] [thread_id=0x5]
[2024/04/13 04:02:48.837 +08:00] [Error] [kv.rs:956] ["batch_commands error"] [err="RpcFinished(Some(RpcStatus { code: 0-OK, message: \"\", details: [] }))"] [thread_id=0x5]