CREATE TABLE `test` (
`id` varchar(32) NOT NULL,
`no` varchar(50) DEFAULT NULL,
`mode` varchar(50) NOT NULL,
`type` varchar(50) NOT NULL,
`createTime` datetime NOT NULL,
`updateTime` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`,`createTime`),
KEY `idx_createTime` (`createTime`),
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
类似这样的表,还有一些列,大概单表200亿,每天的数据量大概能在1~4亿浮动。
类似的 sql:
SELECT count(1) FROM test WHERE createTime BETWEEN '2024-3-24 00:00:00' AND '2024-3-24 23:59:59' and no= '132943828293'
查询速度在分钟级别,以前是用分库分表,查询速度能5秒内,打算换tidb,这个情况不用tiflash是不是就是查不快?怎么优化能让tidb的速度快到10秒内?
分库分表能均匀的把请求发到所有机器上,tidb因为都是region,自由调度,一天的数据可能就集中在一两台机器上。如果说查询的qps比较低的话,不太可能把所有tikv都压起来,结果就是只有两三台tikv参与这次查询,速度就比较慢。这个有什么优化的方法吗?
分区表性能比不分区快吗?分区表相当于把一张大表分成很多小表,有时间索引的情况下,大表扫描的数据量会很多吗?
托马斯滑板鞋
(托马斯滑板鞋)
4
v6.5以后有动态分区裁剪,tiflash机器性能好,也可以扫的动
托马斯滑板鞋
(托马斯滑板鞋)
6
如果TiDB以后也像Oracle支持本地分区索引,还会更快 
假设共200亿,一天的数据就1亿,不分区的话,带索引查询,扫描1亿的索引+回表1亿是吗?
分区表不也是扫描1亿的索引+1亿的回表?
还是说不分区的时候扫描的范围大于一亿?
mono
(Hacker 3 Lu Tkd Re)
8
说实话,你这表,可能对整个系统稳定性有影响。这个表需求方数仓库里查吧!
托马斯滑板鞋
(托马斯滑板鞋)
9
如果是分区表,应该是没有1亿的回表(因为直接选择分区读数据,没有索引)
有猫万事足
10
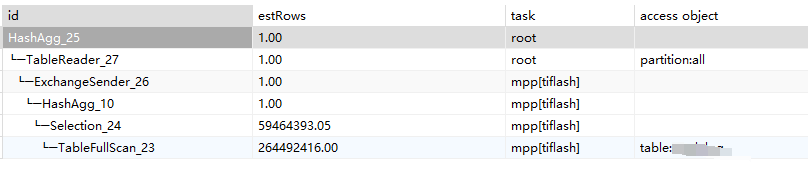
是典型的聚合计算,tiflash+mpp确实是最好的办法。
我给你一个参考。这是在一个2.9亿的分区表上,执行类似的count(1)的执行计划。

硬件配置是2台 4c8g的机器,2 tiflash实例+mpp。
io比较次,是腾讯云,最便宜的存储。cpu你可以看到,波动还不如10分钟一次的gc。
行存上针对性的建立索引也是个解决方案。问题在于where的条件真的是比较确定的嘛?如果不是,那索引一旦没命中的效率就很差了。
[quote=“TiDBer_jYQINSnf, post:1, topic:1023642”]
SELECT count(1) FROM test WHERE createTime BETWEEN '2024-3-24 00:00:00' AND '2024-3-24 23:59:59' and no= '132943828293'
看这个sql,当天的数据要全都查一遍,no没有索引。这种情况下回表就是一亿吧。不分区和分区的区别在于扫描索引的时候的条数,不分区扫描的索引条数比分区扫描的索引条数多吗?会多余1亿吗?
托马斯滑板鞋
(托马斯滑板鞋)
12
理论上是这样的
先通过createtime索引扫1亿,然后回表1亿
分区表的话,直接落在partition上扫1亿
用tiflash应该会比较快,我是想了解下不用tiflash还有办法吗。
有猫万事足
14
where条件确定,那就是索引。
不过我的经验是大部分都不会确定的。哪怕研发现在信誓旦旦。最后索引没命中,tikv cpu狂飙,全表扫描,依然需要你来收拾。
用分区表,也有扫描索引,这个IndexRangeScan比不分区的时候读取的行数会多吗?
mysql> explain SELECT count(1) FROM test WHERE createTime BETWEEN '2024-3-27 00:00:00' AND '2024-3-27 23:59:59' and no = '12314321231';
+----------------------------------+---------+-----------+---------------------------------------------------------------+---------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+----------------------------------+---------+-----------+---------------------------------------------------------------+---------------------------------------------------------------------------------+
| StreamAgg_12 | 1.00 | root | | funcs:count(1)->Column#31 |
| └─IndexLookUp_28 | 0.25 | root | | |
| ├─IndexRangeScan_25(Build) | 250.00 | cop[tikv] | table:test, partition:p202403, index:idx_createTime(createTime) | range:[2024-03-27 00:00:00,2023-03-27 23:59:59], keep order:false, stats:pseudo |
| └─Selection_27(Probe) | 0.25 | cop[tikv] | | eq(test.test.no, "12314321231") |
| └─TableRowIDScan_26 | 250.00 | cop[tikv] | table:test, partition:p202403| keep order:false, stats:pseudo |
+----------------------------------+---------+-----------+---------------------------------------------------------------+---------------------------------------------------------------------------------+
5 rows in set (0.00 sec)
感觉这个表不加tiflash搞不定,但是加上tiflash又得>1副本,那就5副本了。成本没优势 
1 个赞
有猫万事足
17
你说的是一个非常现实的问题。
好比我这2个如此低配的tiflash节点都是和别的系统挤一台的,原因无非也是成本。
我感觉,你可以找个配置很差的机器先尝试用起来,也许用起来就有人愿意为它的稳定付费了。
如果没人在乎,占的成本也不多。
我觉得4c8g这种配置部署一个,应该还是可以接受的。只能说尽力尝试一下,万一提升能出些报告,成本问题也就有希望解决了。
托马斯滑板鞋
(托马斯滑板鞋)
18
 那就是tidb在分区键上会自动加个索引,那和直接建索引没区别了
那就是tidb在分区键上会自动加个索引,那和直接建索引没区别了
SELECT count(1) FROM test WHERE createTime BETWEEN '2024-3-24 00:00:00' AND '2024-3-24 23:59:59' and no= '132943828293'
你这个sql难道不是建一个no和createTime的联合索引就行吗?
1 个赞
no这一个列没啥区分度,就几个值。这个sql也是举个例子,实际上是针对这张表做了一个表单,每一列一个单元格,能控制的是强制输入日期,其他列任意组合,超时时间30秒。
用分库分表查询还是凑合能用,用tidb替代的话,好像有点难度。