grafana里面看下overview里面的systeminfo,各个机器的资源负载情况,看下刚才的时间段的
看着就是内存不足导致的,两台机器跑tidb集群,个人感觉有点不够用,还是混布
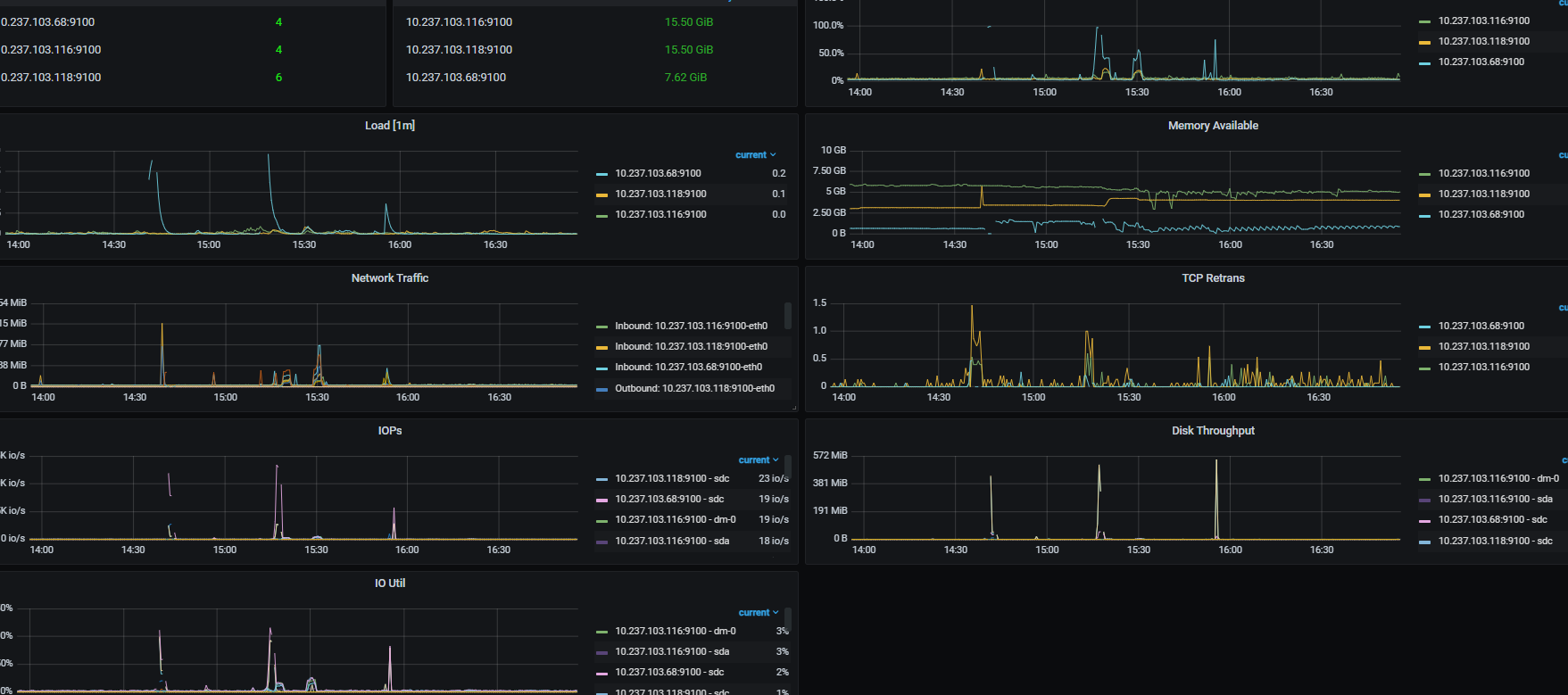
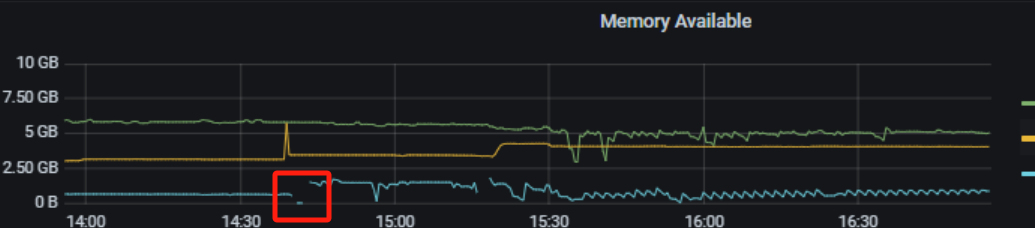
不是,就那个机子是8G,还有一个15G,只不过这个8G的上面的tidb,是程序连接的入口,不知能能不能换到15G的那个机子上连接,我怕连接以后,那个表的自增会变
解析时间太长,独立部署个tidb吧
这个是测试环境 ![]() ,就几个机子
,就几个机子
堆硬件吧。堆上去再试试。
8G的内存实在太小了,按部署文档还需要关了交换分区。
表的自增会变的问题,需要你建表加参数 AUTO_ID_CACHE=1,改成集中自增模式,这样所有tidb共享一组自增,性能还行
大概率是资源存在争用问题,可通过硬件升级解决的问题,就硬件来搞定。
别混合部署
鉴于楼主的问题在于用两台机器部署整个集群,在这里建议:
如果想要测试tidb的功能特性,不做性能测试的话,建议使用tidb serverless 服务,官方免费提供的云服务版本,每个人可以白嫖5个小集群。
如果想本地部署,可以考虑用tiup playground 部署,或者你就搞少一点节点(比如1tidb+1pd+3tikv)。如果考虑性能,那么至少准备3台机器来部署。
混布,且机器资源太低。 tidb社区活跃度太高了。对于初学者有利处多,
我这个是3台机子啊
嗯嗯,是的,帮助很大!
随便加点内存再试试
https://docs.pingcap.com/zh/tidb/v5.4/hardware-and-software-requirements
还是资源不足的问题。
具体可以参考下官方的建议部署值,或者调整部署架构。
分配自增ID的组件是由PD统一生成和分配的,如果你切换了tidb-sever,最多是可能会有一段空洞,不会影响已写入表的数据的增长性和唯一性。比如表里写入了 1到100,你切换的tidb里暂时缓存了 101到150,切换后这段ID没了,新的tidb-server会重新从pd申请id段,这个时候可以获得151以上的id,这样你的表里写入的id是 1到100,再从151继续往上。
嗯嗯,是的是的