如果不绑定主键,走辅助索引,会更慢
这是不绑定的执行计划,全部走的辅助索引过滤

你们说那有没有可能跟缓存有关系?超过缓存了就走不了绑定了?
tidb_mem_quota_binding_cache
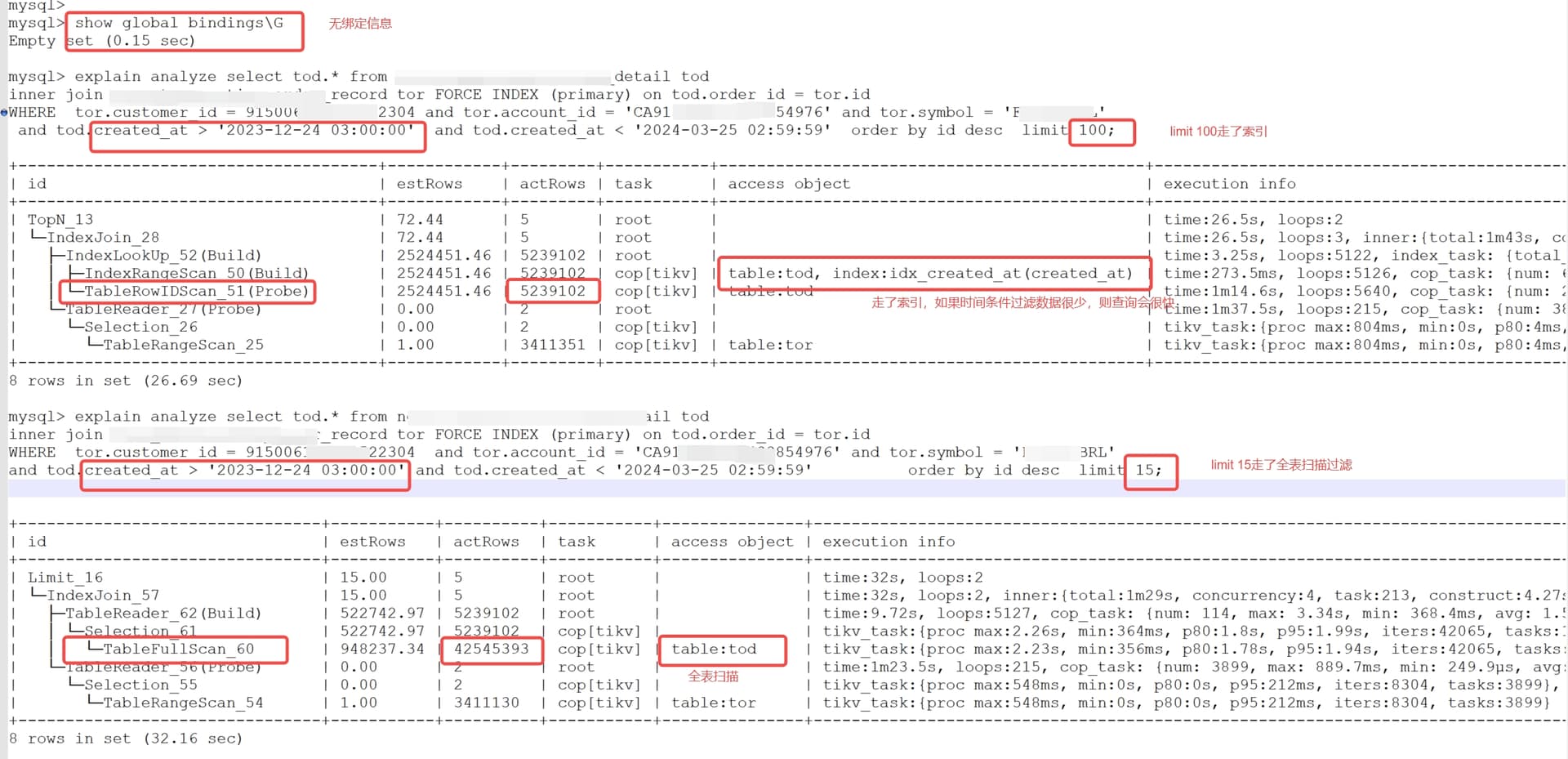
这是绑定的直接走idx_created_at(created_at)过滤出order_id,然后tor的id列去做内连接,就是主键等值查询,这个肯定很快,不绑定就是两个表都用辅助索引去过率两个表的连接列,超级慢

1 个赞
我的意思是,绑定计划里的sql不要limit 100试过了没,去掉limit,然后再分别用limit 10 和 limit 100去查看看是否走绑定计划;
limit仅仅控制返回行,放在最外面不参与sql逻辑优化
limit 10 和limit 100的需要固定2次执行计划,你固定了limit 100,其实没有固定limit 10的执行计划
如果绑定limit 10 会把limi他100的覆盖掉
这两个只能绑定一个
手动清空下缓存呢admin flush session plan_cache;
可以在从库根据对的执行计划绑定,然后你看下有没有SELECT @@LAST_PLAN_FROM_BINDING;
FORCE INDEX (primary) 这用法对吗?
FORCE_INDEX(t1_name, idx1_name [, idx2_name ...])提示优化器对指定表仅使用给出的索引。
看你两个执行计划也没有走主键索引呀。
limit 100 ,走了idx_created_at 索引的更快。
FORCE_INDEX是为了让tod表做Build,也就是驱动表。这样通过idx_created_at 索引先过滤很少的行,然后再去和tor表做连接
但是这样做的缺点也很明显,如果通过idx_created_at 过滤的行太多,那么这种效率就不高了
我执行的是explain analyze 执行的,这个应该和绑定没有关系了。因为sql也不一样了
学习了 没理解这个问题。
两个表的表结构能发下吗 ??
- 仅仅从SQL上看 ,应该 tor 做驱动表 才对 , 看下 tor 表加上该SQL的条件后 ,返回多少行数据
- 也发下 tod表加上该表的 created条件 返回多少行数据?
= 值条件 按道理说 返回的数据应该很少, 并且作为驱动表
》= <= 范围条件过滤性应该没那么好才对
tidb其实也没啥必须驱动表,create 过滤大概500多万数据mysql> select count(*) from detail d left join record r on d.order_id = r.id where d.created_at >= ‘2023-12-25 00:00:00’ and d.created_at < ‘2024-03-25 00:00:00’ ;
±---------+
| count(*) |
±---------+
| 5191902 |
±---------+
1 row in set (15.93 sec)

感觉像是版本问题,limit 15和limit 10这种就全表扫描