利用rowid分页删除会比较快,影响也小,事务量小并发高。cdc的机器如果还可以,目前没遇到啥问题。大事务容易延迟
1 个赞
直接干掉分区是最好的
可以考虑使用pt-archiver删除
重建新表,将需要的数据导入即可,后续删除大表。
这种方案并不适用于线上在使用的大表
可以看下这个,慢慢删就行。
2 个赞
写个脚本,小批量多次删除,影响应该还好吧。
没有时间限制的话,每天删除一点,对下游cdc影响也小点

流式处理呀
分批删除影响小
问题1:
普通的delete操作也会释放空间,只不过需要比较长的时间,通常是以天为单位。用户的delete是标记删除,GC阶段确认数据过期,等到RocksDB后台自动compact执行完毕后,会真正释放空间。
问题2:
如果你是整个分区不需要了,那么高效删除数据的方式就是直接 drop 整个分区。
鉴于你说的要删除的数据,是每个分区中的部分数据,就不能采用 drop 分区的做法了 。取而代之的方式是
- 循环微批事务删除
- 非事务式的 Batch on 方式大批量删除
具体的操作方式,可以参考楼上各位大佬提到的,这里不赘述。
问题3:
你9000万行数据不是一瞬间删除就好(如果不是drop或truncate分区或表也很难做到),把删数据的时间拉长、控制频率,问题不大。以前试过半个小时删除1亿行都没什么问题。
问题4:
v6.5版本的TiCDC性能可以轻松同步几万的QPS,所以加上你控制好微批数据删除的量,应该没什么问题。如果你还不放心,那就提前在测试环境做好验证、操作前发公告告知业务相关方,甚至做一些应急计划。
1 个赞
昨天分批处理,每个delete操作涉及到的数据条目控制在50w左右,每执行完一次delete,进行sleep 5秒。大概持续了3小时左右,已经删除完成。ticdc侧偶尔会有延迟告警消息,不过,经过一晚上都已经同步正常。感谢社区各位大佬的宝贵意见!!!
batch加limit就是越删除速度越慢,最好不用
你看看硬盘空间占用有没有下降,或者直接统计表regions的大小合计更方便
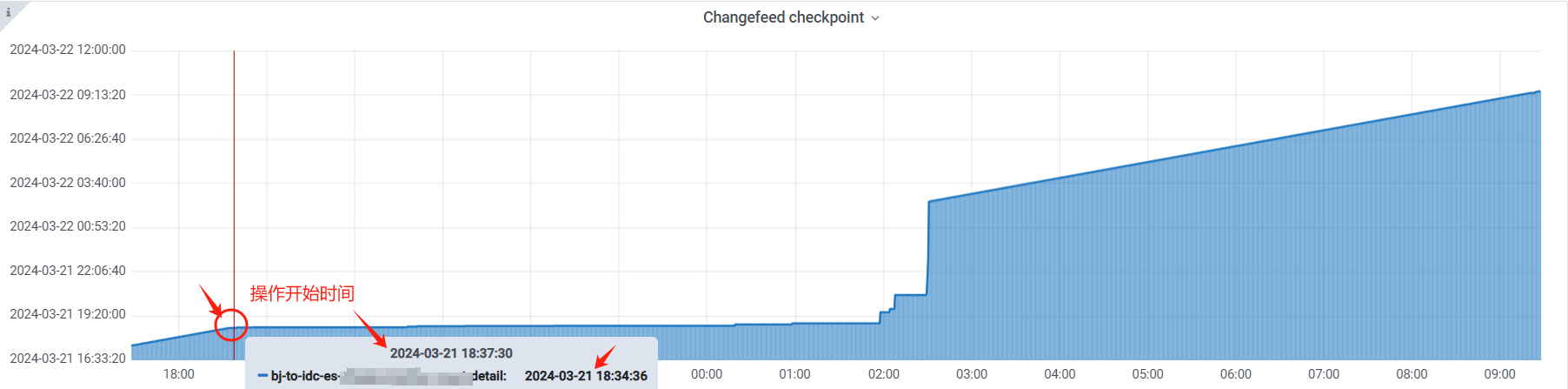
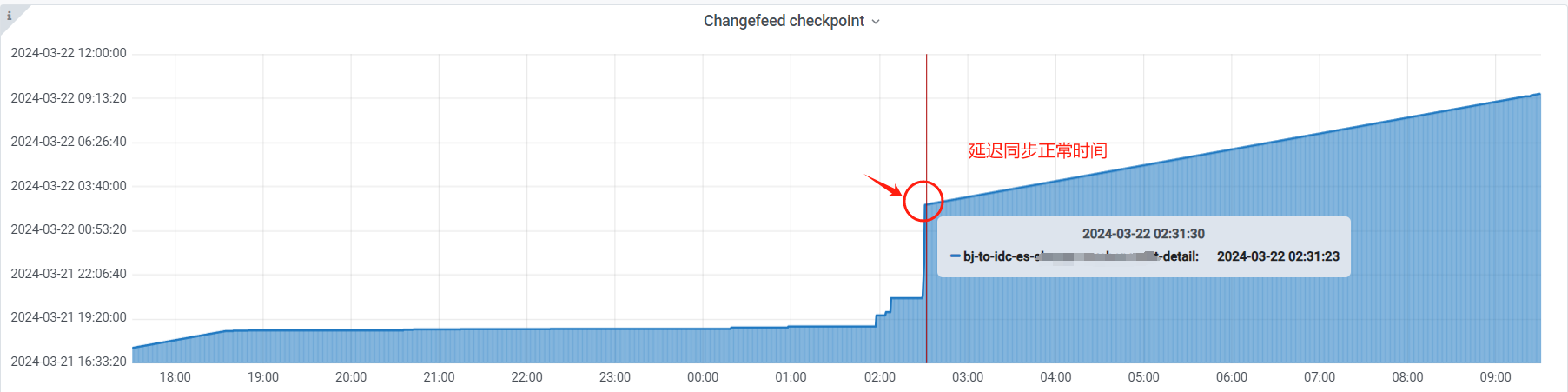
我们的gc设置保留时间为72小时,估计空间需要等三天后,才能看出来减小。
72h是我听过最长的了,金融一般就48
我们的业务场景决定的,下游有tidb和kafka,之前,出现过丢失数据的问题。所以,设定的长一些。
gc太长如果update和delete多还是挺影响查询性能的