如图,连接总数是338,但是通过/metrics接口,得到的值为1,感觉很像活跃连接数的值
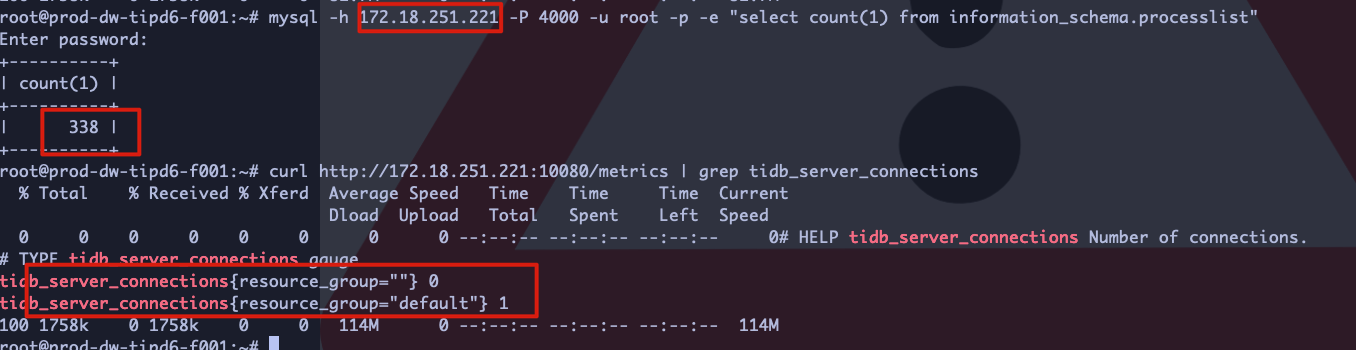
换个tidb-server节点curl一下试试?
或者netstat 过滤一下 看看真正建立的连接有哪些,感觉直接查应该是整个集群的连接数,
下面的curl拿到的应该只是单个对应的连接数。
再或者看下监控里面连接数的取值是哪个
看下其他指标是正常的吗? 比如 tidb_server_tokens,这个是看活动会话数的。
告警日志内或许有能够提示的信息。
升级过程中有配置过这个不
不过奇怪,同一个集群里有多个tidb-server,其中有一台机器上的指标是正常的,只有一个default的指标
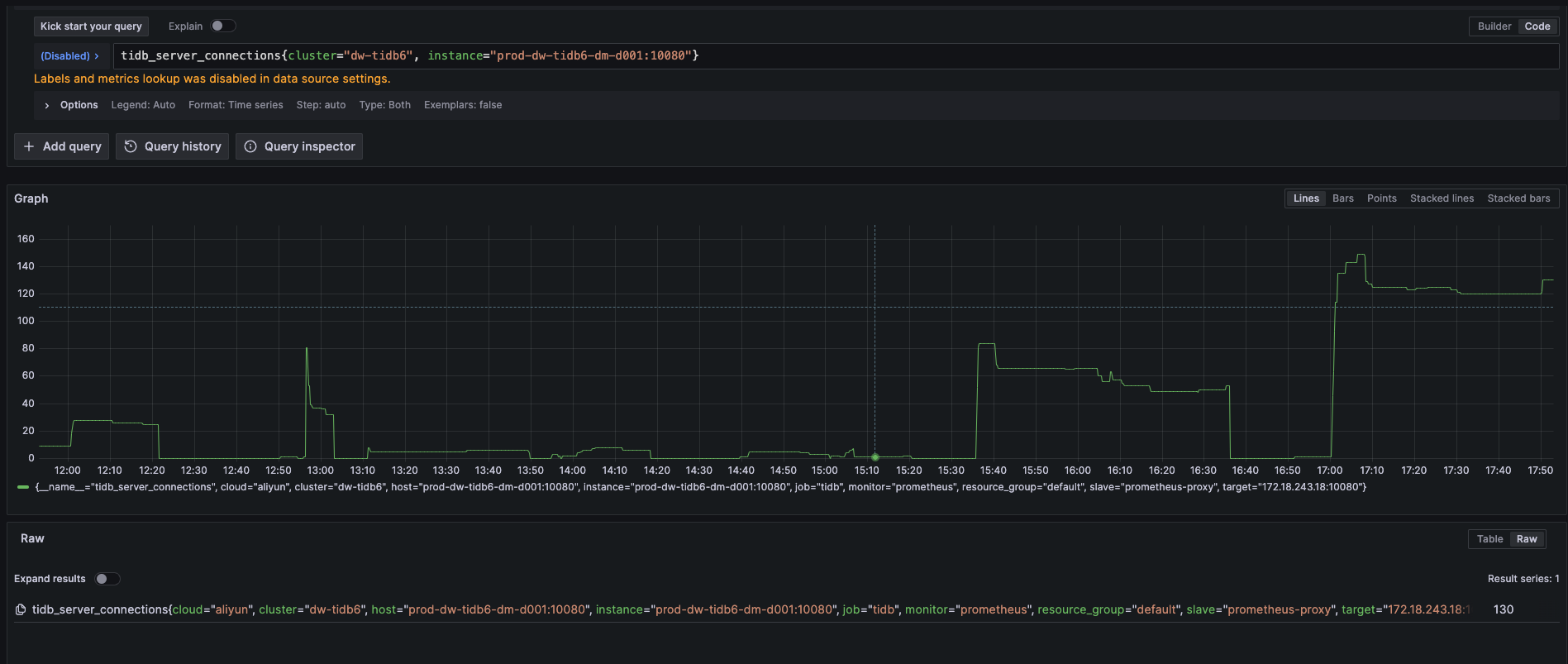
其他异常的节点,还会上报一个不带resource_group label的metrics。

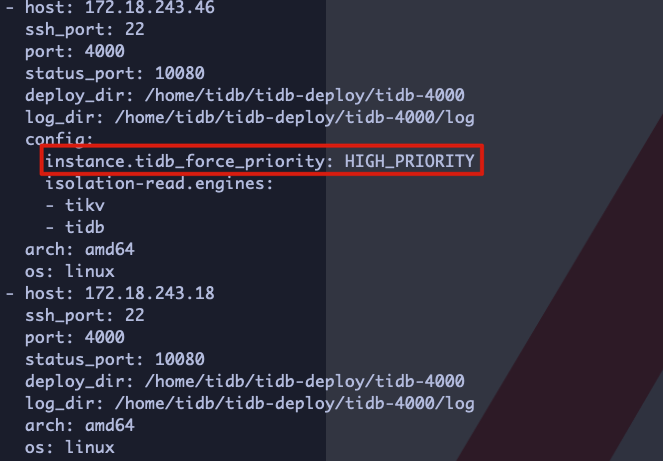
对比了下配置,发现其他几个tidb-server都配了instance.tidb_force_priority这个参数,而指标正常的tidb-server没有配置。我周末去掉一下,再来观察下。
这是个 bug, 后面这个 issue 跟踪: https://github.com/pingcap/tidb/issues/51889
在 graceful shutdown 增强引入的问题(https://github.com/pingcap/tidb/pull/32111)。 给 resource group 加相关的 metric https://github.com/pingcap/tidb/pull/49424 加了监控后,暴露出来了这个问题
1 个赞
大佬很细心,捉虫小能手 ![]()
一样的问题
Connection Count ip重复
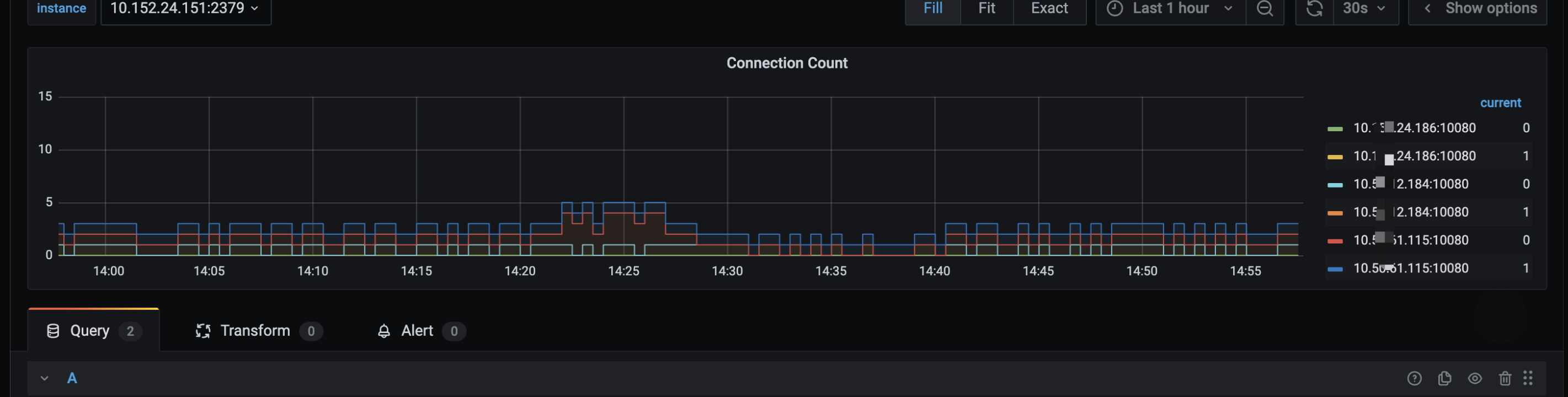
临时解决办法 :tidb_server_connections{k8s_cluster=“$k8s_cluster”, tidb_cluster=“$tidb_cluster”, resource_group=“default”}
我是直接group by sum了一下,数据量还是不对,只不过每个instance只会有一条线了
sum(tidb_server_connections{cluster="$tidb_cluster"}) by (instance)
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。