【 TiDB 使用环境】生产环境
【 TiDB 版本】6.5.5
【复现路径】做过哪些操作出现的问题
两个集群互为主从,同步方式为ticdc,跑正常业务
【遇到的问题:问题现象及影响】
t1集群tikv性能较好,t2集群tikv性能为t1集群的50%
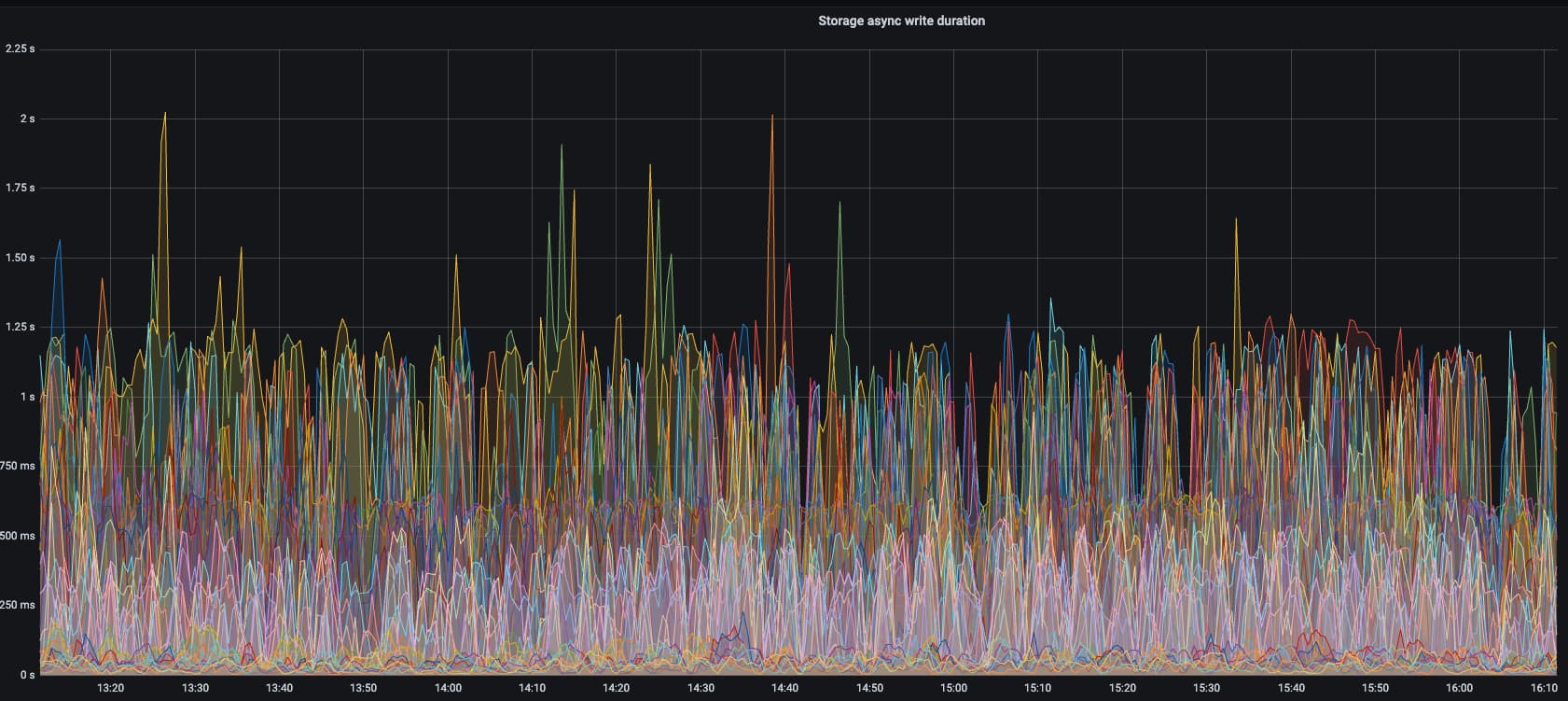
t2集群一直告警,并且写入性能很差,告警如下图:
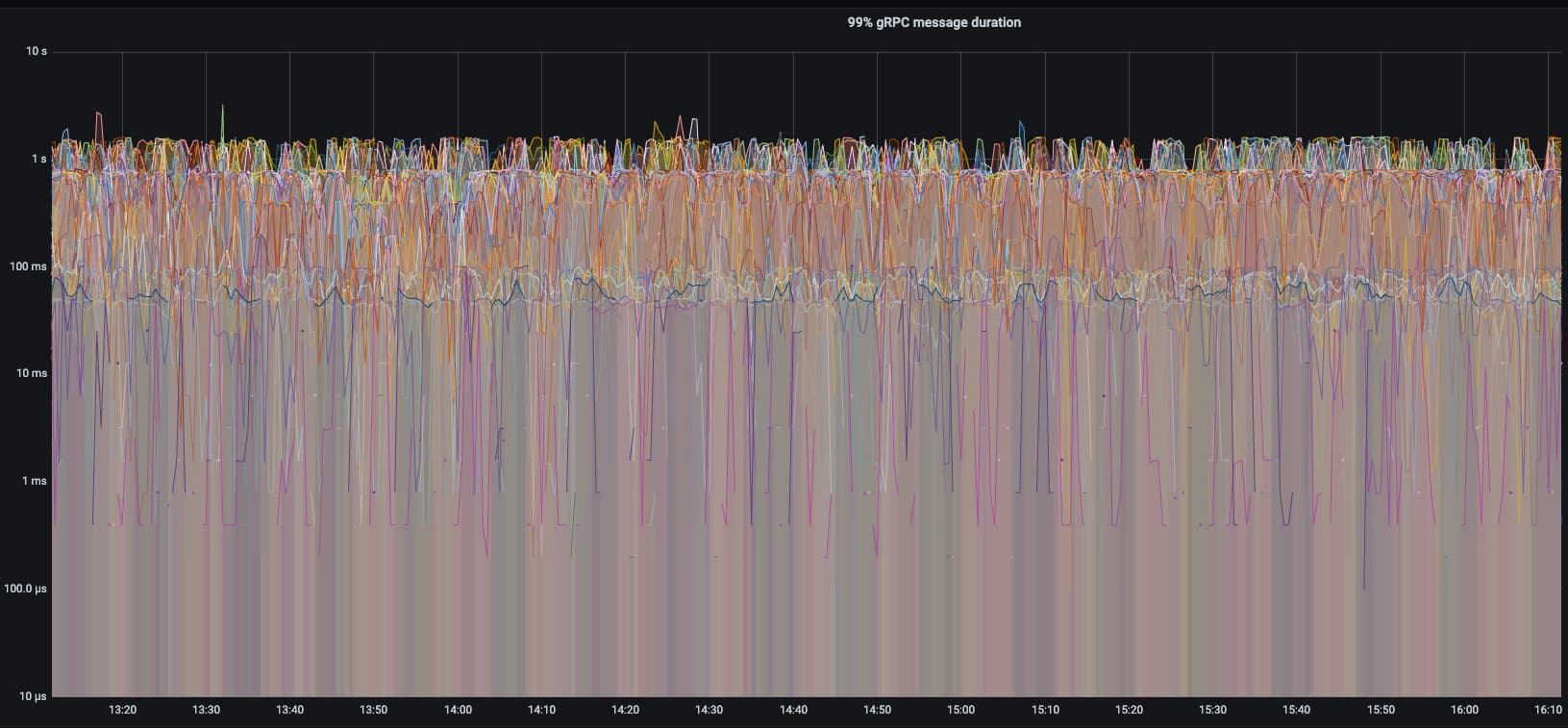
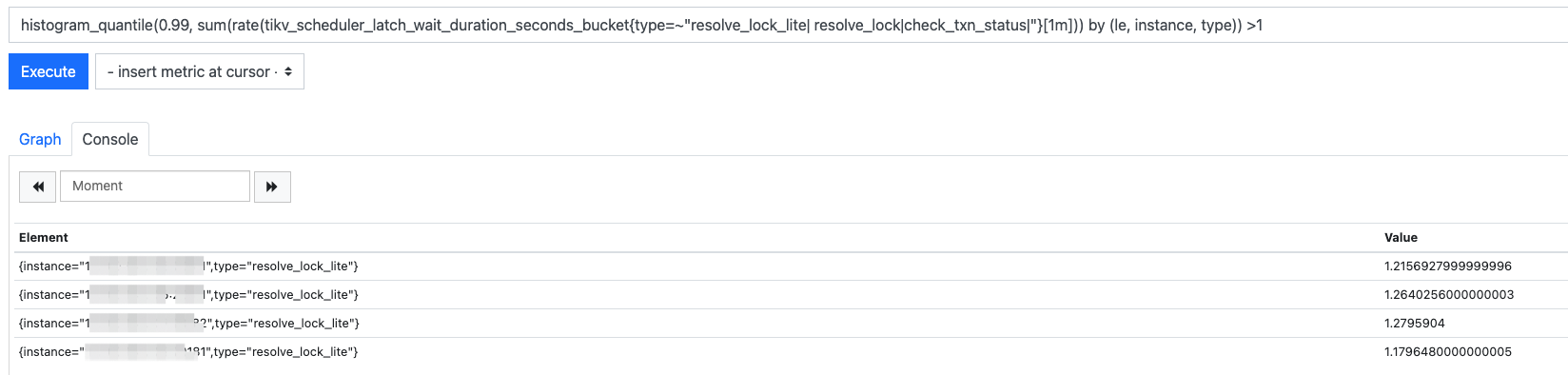
查看监控,kv reslove lock达到1秒多
prometheus查看,大于1的都是resolve_lock_lite
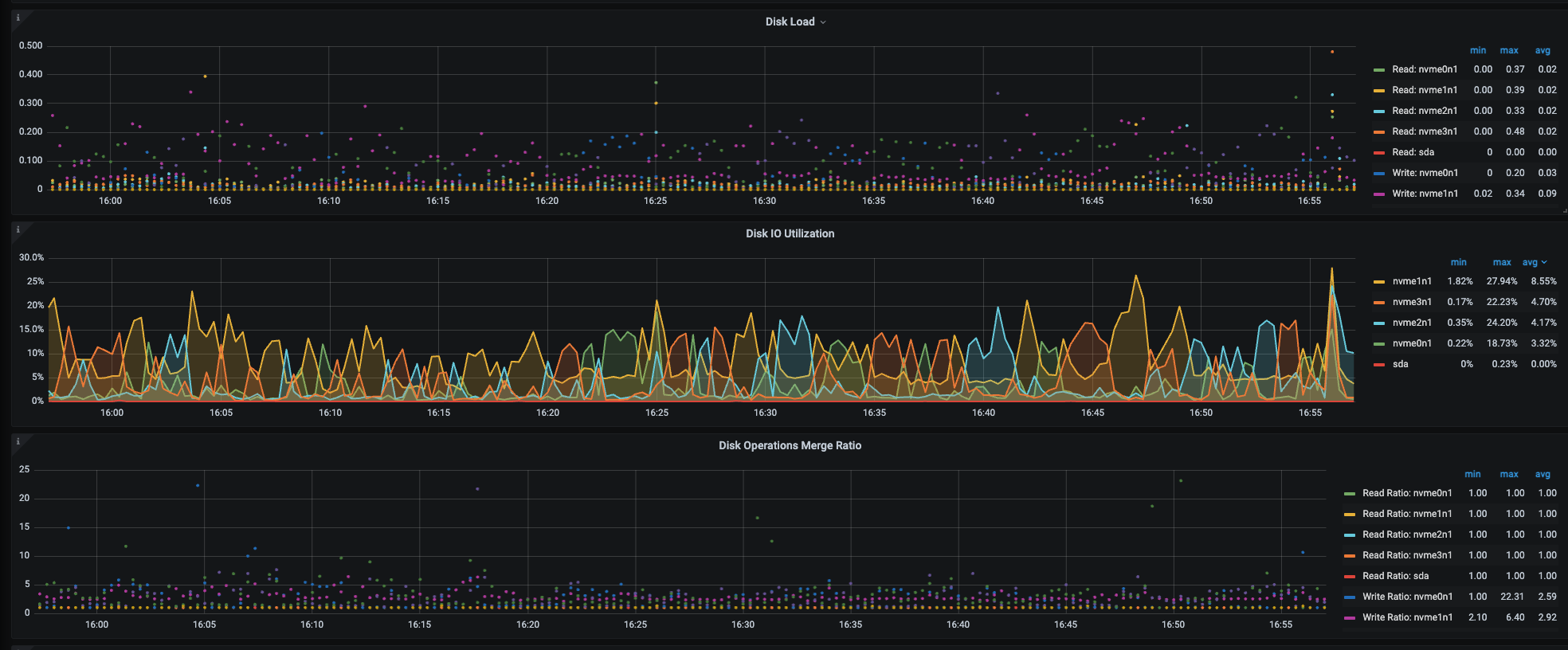
这个集群虽然说性能差一点,但是也是12个tikv实例,部署在9台物理机上,都是nvme盘,写入性能却很差
请问如何解决写入慢的问题,resolve_lock_lite这个是轻量级锁,如何降低呢
【资源配置】进入到 TiDB Dashboard -集群信息 (Cluster Info) -主机(Hosts) 截图此页面
【附件:截图/日志/监控】
h5n1
(H5n1)
2
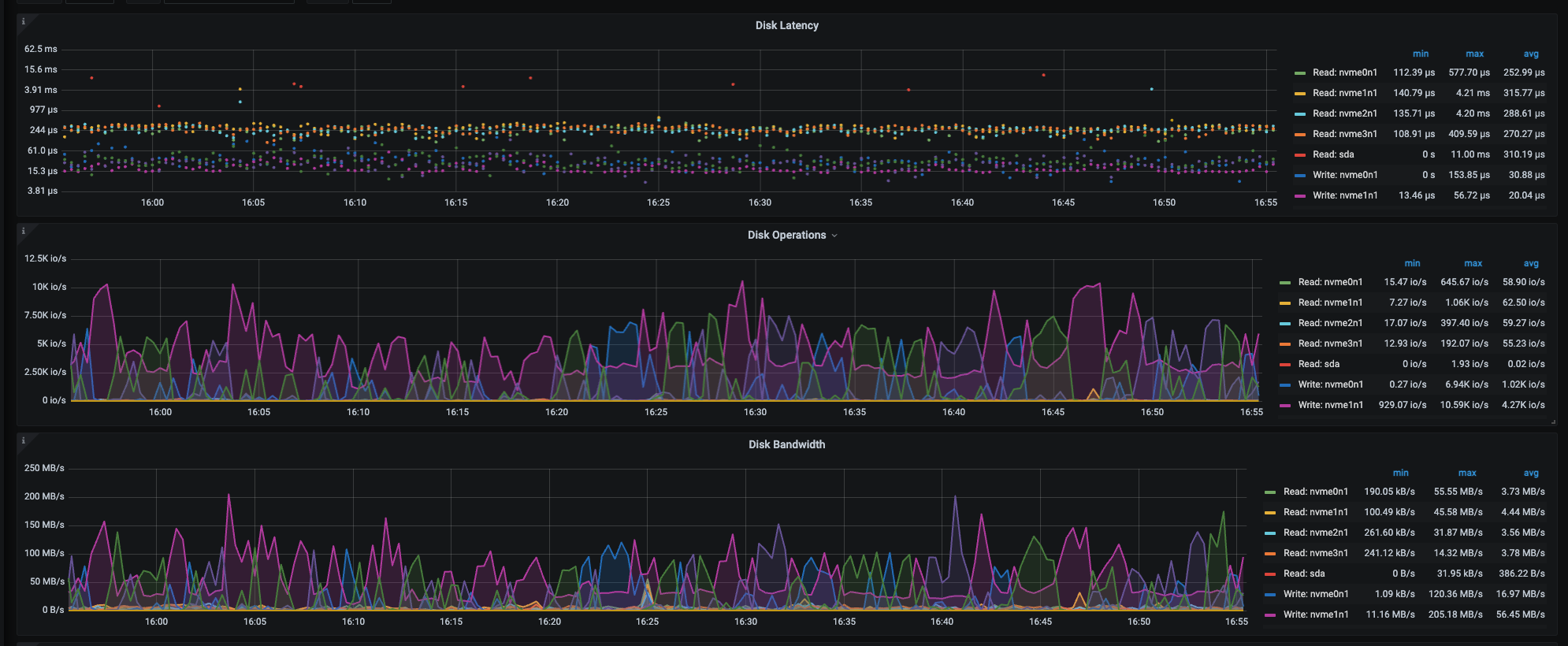
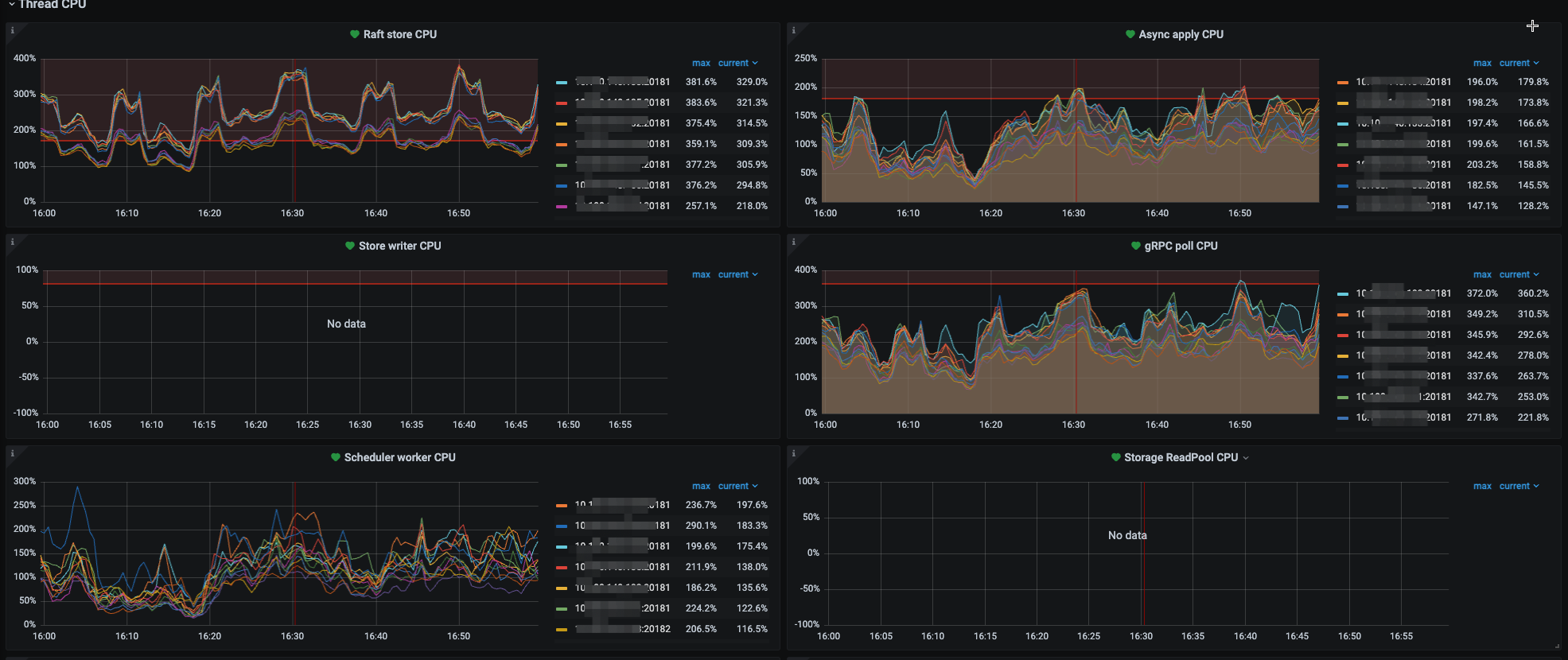
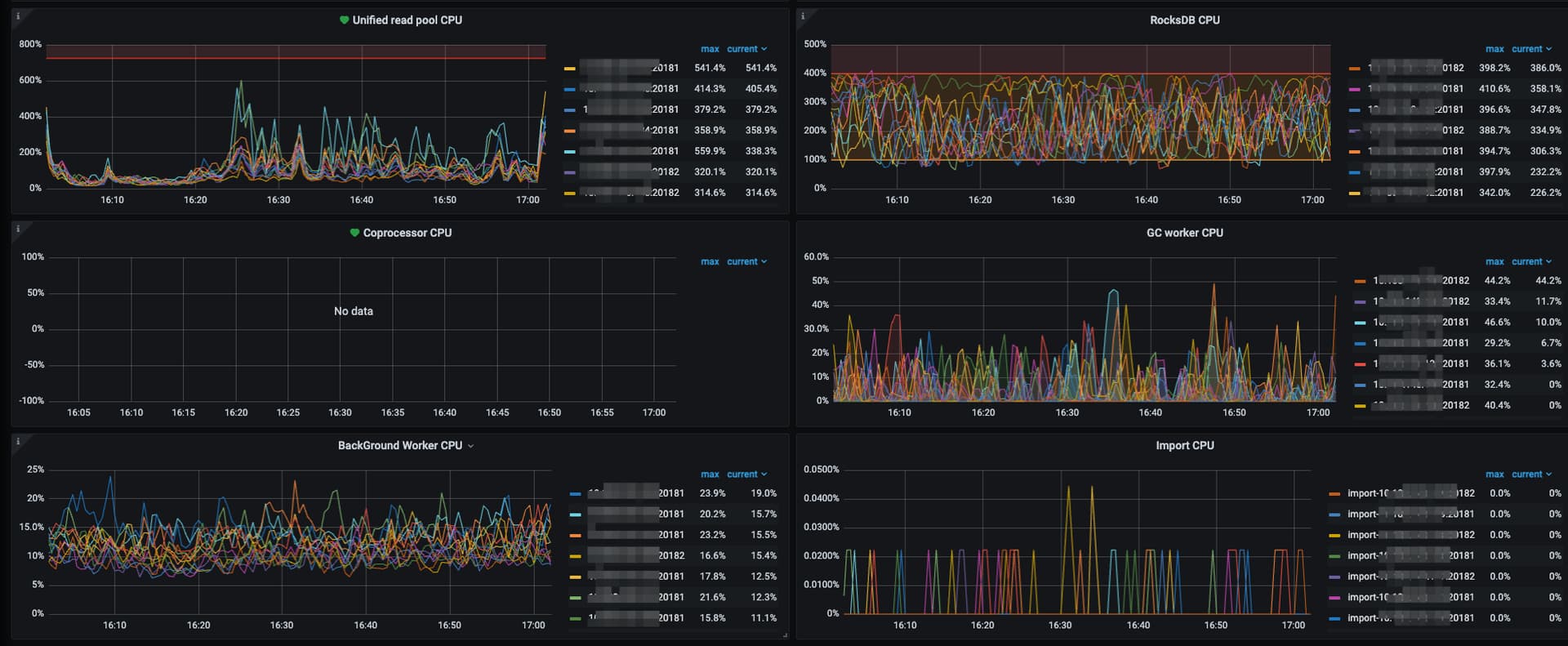
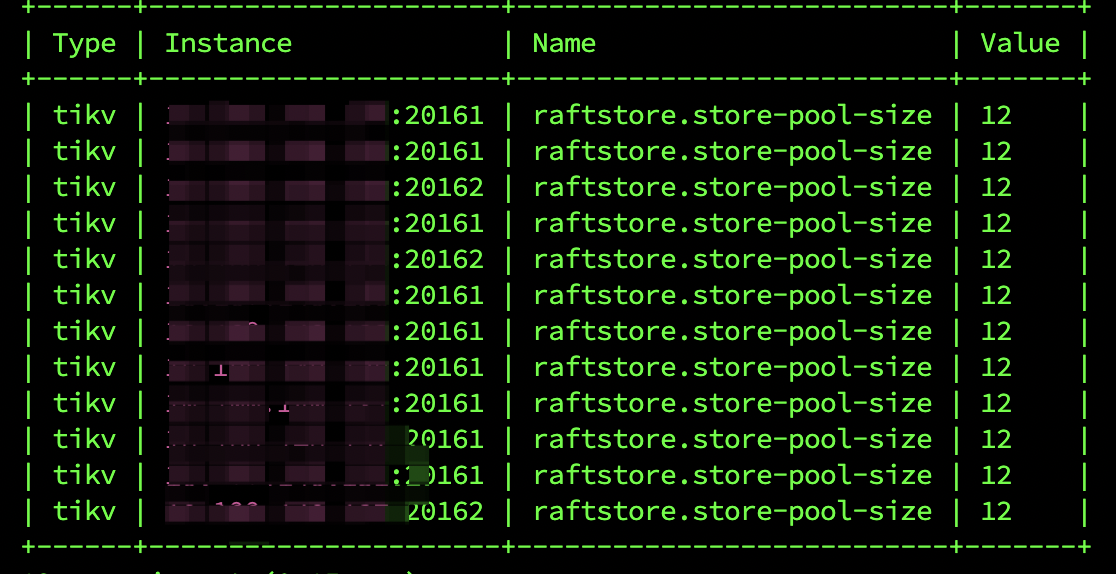
这个集群的 tikv-detail → thread cpu 、scheduler-commit → latch wait duration 、 disk-performance 监控看下, 还有 scheduler-worker-pool-size参数值
scheduler-worker-pool-size参数值都是10
h5n1
(H5n1)
12
raftstore线程很忙 raftstore.store-pool-size 可以先调整到4看看 set config tikv raftstore.store-pool-size=4 ,tikv 整体cpu利用率多高
h5n1
(H5n1)
14
前面那个scheduler latch 怎么跟这个差异这么大,不是一个集群的? 可以试试调大scheduler-concurrency = 4096000
1 个赞
raftstore.store-pool-size设置的是12
江湖故人
16
是一个集群的,下面这个是从Scheduler - acquire_pessimistic_lock界面截的
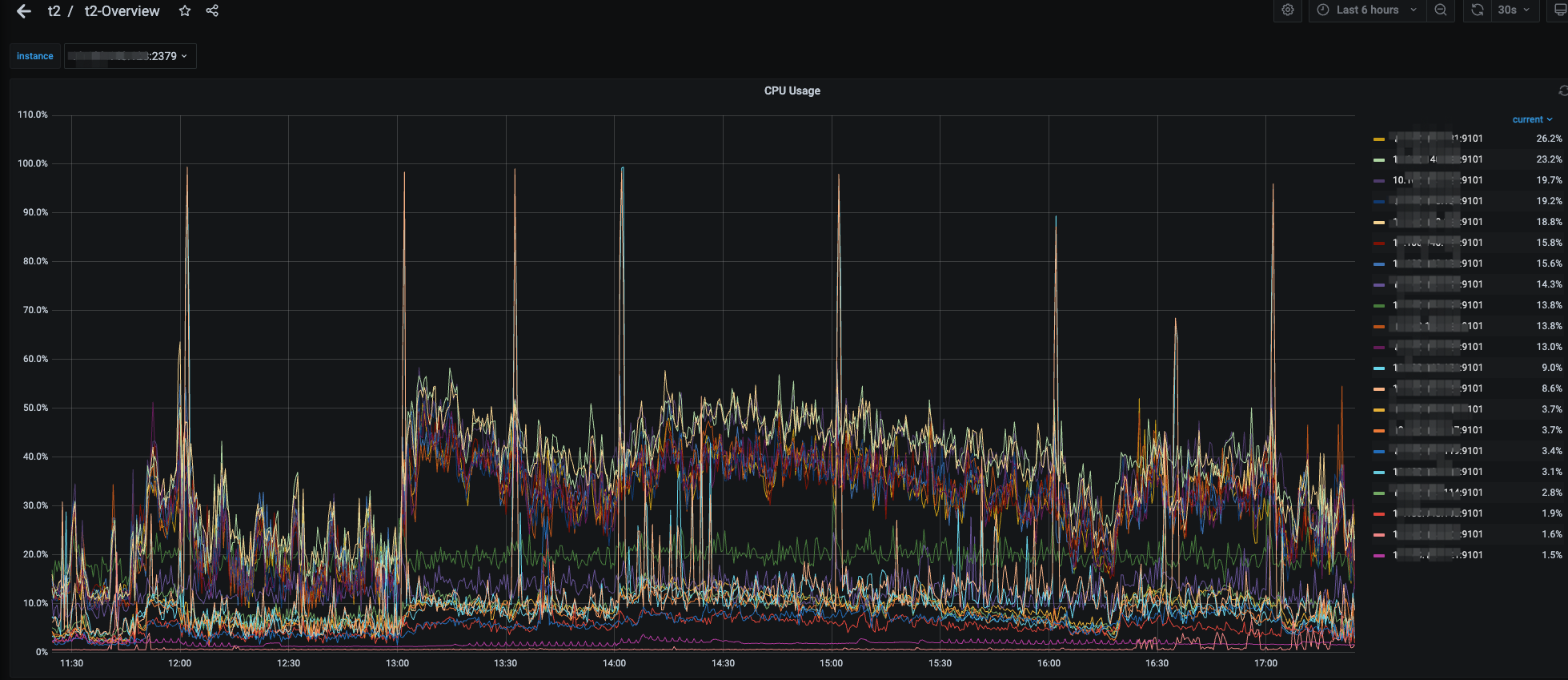
cpu整体利用率没上去,有瞬时高峰的是tiflash服务器,tikv基本50%上下