这不是region size也是相同的吗,store use不同可能是统计了整块盘的使用情况吧,你去对应节点看看,是不是老的那俩节点上tikv日志很多
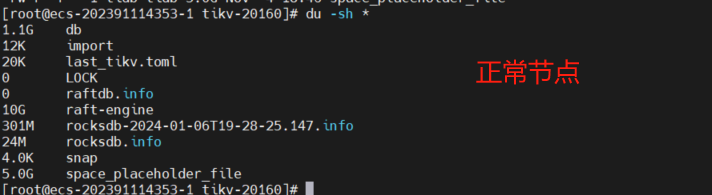
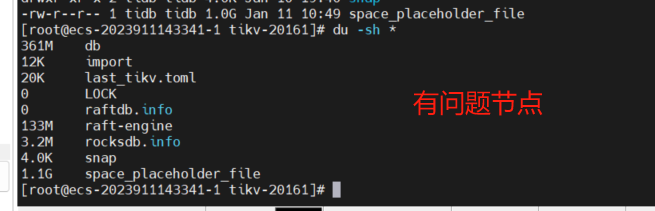
比较正常,差一些是正常的,底层是LSM tree,主要你之前不是显示store-4 11g、store-7 11g吗,你去看看这个磁盘使用率,是不是能对上
store-4和store-7在监控上看都是11G,查看tikv的data_dir占用空间都是17G,这个问题节点上监控是672MB,data_dir占用空间是3.5G。基本是对的上的
leader-schedule-limit是4,placement policy是默认策略,store weigh都是1这些都没变
有没有对坏的节点调查坏的原因再扩容回去的。
1 个赞
你自己再研究下对下吧,至少现在数据库是没问题的,region size也是正常的
排查了,是因为磁盘的问题,修复后扩容上去的
好的,感谢
解决了就好
肯定会的,需要pd去调度
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。