【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
v5.4.0
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
1.由于历史原因和业务需要,部署的是v5.4.0新集群,集群尚未接入业务,但是出现TiKV_raft_log_lag延迟告警。
该告警含义 TiKV_raft_log_lag:
- 报警规则:
histogram_quantile(0.99, sum(rate(tikv_raftstore_log_lag_bucket[1m])) by (le, instance)) > 5000 - 规则描述:这个值偏大,表明 Follower 已经远远落后于 Leader,Raft 没法正常同步了。可能的原因是 Follower 所在的 TiKV 卡住或者挂掉了。
2.集群没有写入流量,tpd/tidb/tikv等各个节点都是正常的状态,没有挂掉的节点,集群无异常节点。
看PD面板集群是有30个region,这30个region都是空region。
3.TiKV_raft_log_lag 有一个tikv节点较高,可能的原因是 Follower 所在的这个 TiKV 卡住了。

4.排查节点日志
1)查看该节点日志,无ERRO异常信息,但是一直在刷“try to transfer leader”。
[2023/12/19 10:23:31.445 +08:00] [INFO] [pd.rs:1273] [“try to transfer leader”] [to_peer=“id: 633 store_id: 1 role: IncomingVoter”] [from_peer=“id: 558 store_id: 397 role: DemotingVoter”] [region_id=557]
这里推测可能是因为 raft 进程可能有问题,导致无法正常切换Leader。
store_id: 397 就是出现告警的tikv节点。
2)排查region 577、633 、558的情况,无异常信息。
3)对集群进行pd-ctl region check 没有异常或损坏的region,只有出现的30个空region。
4)查看问题时段,pd确实有生成打散region的operator调度策略,tikv执行add 3个新learner,然后把三个新learner转到voter,3个老voter转成learner,然后把leader从397转到633卡住了。pd和tikv的GRPC交互对接是正常的,只是tikv的调度执行一直无法推进,在重复try。
5)选主,卡在中间状态

5.尝试恢复
1)由于集群的30个region全部都是空region,尝试调大merge-schedule-limit、max-merge-region-keys、max-merge-region-size处理,效果是没有优化,问题仍然在。
2)重启节点,问题恢复。
重启后,这个故障点store_id 397上的peer_ID 558已经去掉了。
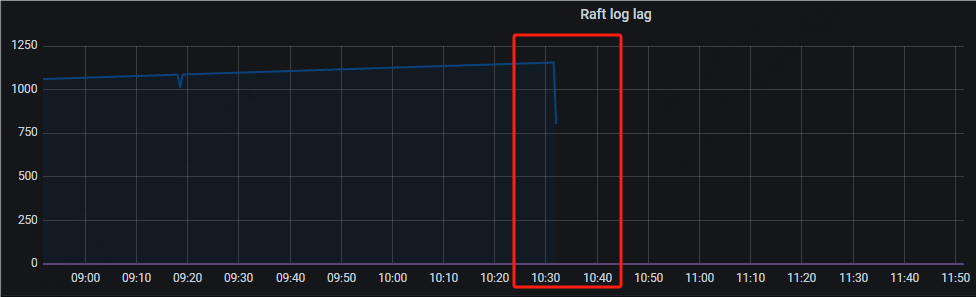
6.重启后告警也随之消失,监控曲线恢复正常。
7.社区里之前有过一个类似的问题,但是没有提出解决办法:TiKV节点出现大量的TiKV_raft_log_lag的问题
这个问题和官方的一个bugfix现象很像:
- https://github.com/tikv/tikv/issues/14740
-
https://github.com/tikv/tikv/pull/14957
但是这里描述的是网络分区隔离后出现的问题“ raft log lag increased after network partition”,我们的这个场景排查这个节点的网络情况,问题期间是正常的,现象是tikv的某个线程卡住了一样。
8.结论:这个是 raft log 从 leader 同步到 follow 出现 raft client线程卡主的的问题,导致阻塞了PD的调度任务he raft GC,可以暂时通过重启节点解决了问题。
但伴随着运行风险点,仍需要解决,各位大佬有没有遇到过类似的问题,有无其他处理思路?