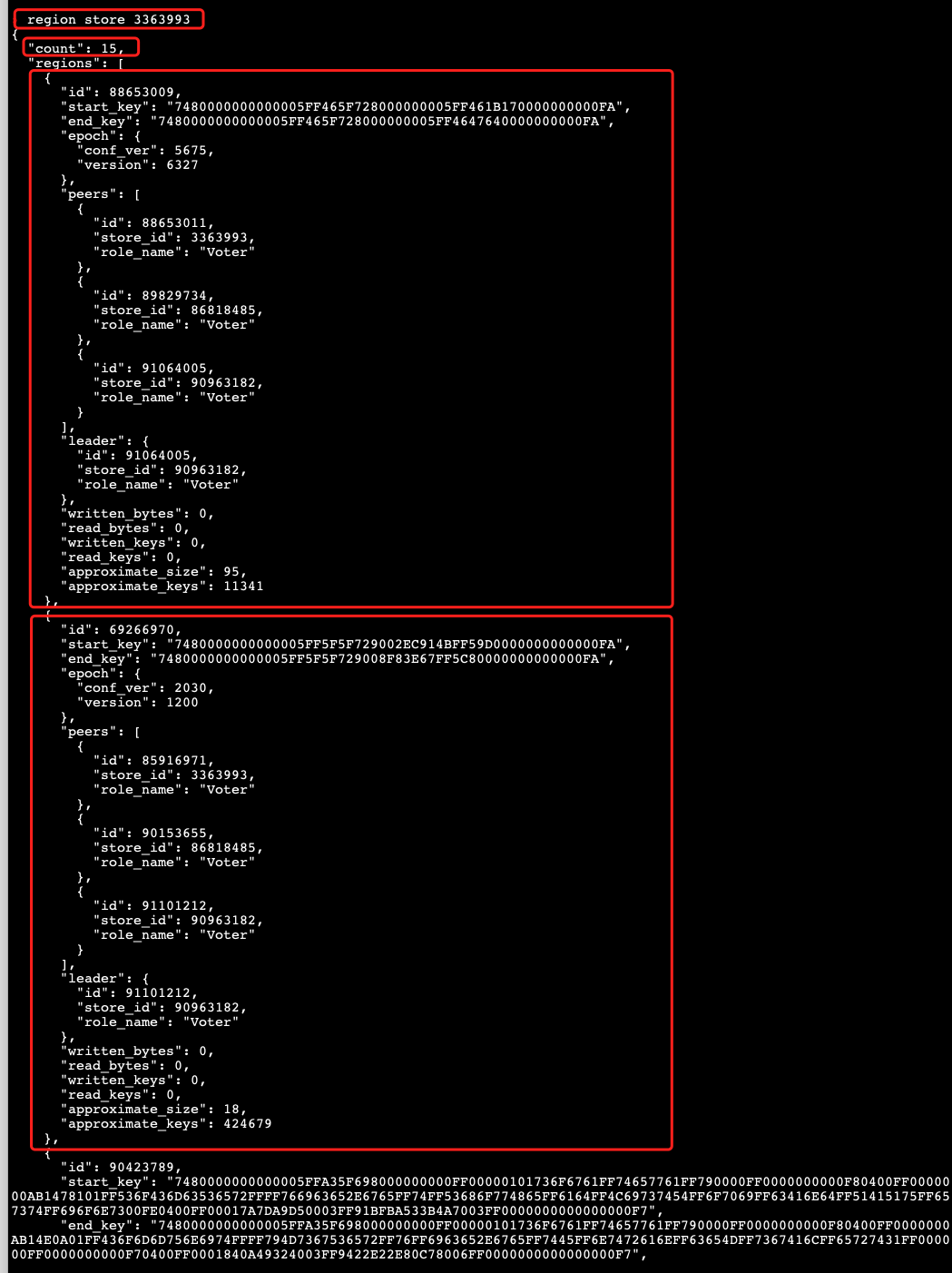
【附件:截图/日志/监控】
pd leader节点,每10分钟会输出这样的日志:
[2023/12/14 09:54:07.883 +08:00] [WARN] [cluster.go:1232] [“store may not turn into Tombstone, there are no extra up store has enough space to accommodate the extra replica”] [store="id:3363993 address:"10.10.10.10:29120" state:Offline labels:<key:"host" value:"tikv8" > version:"5.1.1" status_address:"10.10.10.10:29130" git_hash:"4705d7c6e9c42d129d3309e05911ec6b08a25a38" start_timestamp:1702458741 deploy_path:"/work/tidb29100/deploy/tikv-29120/bin" last_heartbeat:1702518842815183571 "]
是的,没到这个阈值的节点(1个是新扩容tikv,一个是75%使用率的tikv)region数量都在增加的,只不过scale-in节点的region没有迁移,猜测可能这2个没到阈值的tikv再均衡的话,scale-in节点的region会再次迁移的。不过已经通过config set low-space-ratio 0.85将scale-in节点的region迁移完了,不能复现了