Prest13
(Ti D Ber 5 W4e F6 Oi)
1
【 TiDB 使用环境】生产环境 /测试/ Poc
数据迁移导入
【 TiDB 版本】
v7.1.0、v7.1.1和v7.1.2
【复现路径】做过哪些操作出现的问题
按照标准流程导入csv文件即可复现,CSV和Lightning配置文件如下:
light.toml (429 字节)
lightningtest.NTEST.csv (60 字节)
【遇到的问题:问题现象及影响】
CSV文件中,使用逗号,作为字段分隔符,使用双引号"作为定界符。
测试的表结构如下:
create table NTEST(id bigint primary key, name varchar(32), remark varchar(128));
预期结果为,CSV源自另一个非MYSQL数据库,其中同一列同时存在长度为0的字符串也就是空字符串"“,和NULL值。导入后,”"应在tidb中处理为空字符串,NULL值应处理为NULL。
实际结果如下,空字符串和NULL值均被处理为NULL值存入TiDB数据库,与预期不符。
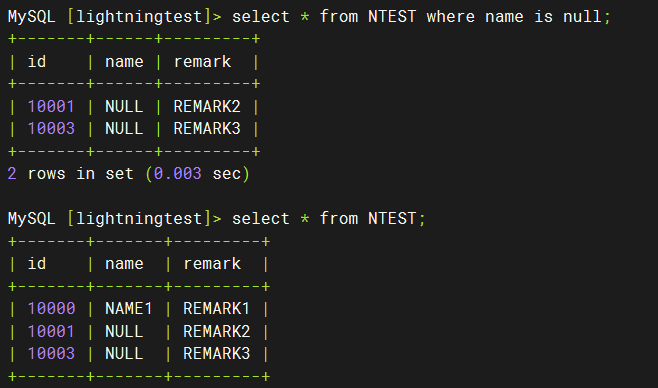
【资源配置】
不涉及
【附件:截图/日志/监控】
小龙虾爱大龙虾
(Minghao Ren)
3
lightning工具是可以区分null值和空串的,你试下这俩参数
CSV 文件是否包含 NULL。
如果 not-null = true,CSV 所有列都不能解析为 NULL。
not-null = false
如果 not-null = false(即 CSV 可以包含 NULL),
为以下值的字段将会被解析为 NULL。
null = ‘\N’
是否对字段内“\“进行转义
2 个赞
Prest13
(Ti D Ber 5 W4e F6 Oi)
4
这样肯定是不合理的,最后我们也是用了替换后update的方式,将’'写入到tidb。
Prest13
(Ti D Ber 5 W4e F6 Oi)
5
在我模拟复现的场景中,lightning的配置文件里
关于not-null参数:
not-null是设置为false的,这是因为csv实际上来源于另一个非MySQL生态数据库,其中的NULL值需要迁移到tidb;
关于null= ‘\N’ 参数:
目前我们测试过程中,由于源端数据库导出到csv时,NULL值处理为两个连续的分隔符,也就是两个逗号,,如果null=‘\N’,则这种NULL值也无法处理导入到tidb,所以需要把null=设置为’'。
综上,这次的导入受限于源库导出的CSV,而导出的csv中是可以明确区分空字符串和NULL值的(,“”,和,),我们希望lightning也可以按照这样的逻辑区分并处理到tidb,但并未找到可行的配置方案。
受限于项目的时间要求,我们是通过sed批量替换-导入tidb后批量update的方式绕过了这个问题
确实是一个功能上的缺失,如果数据量大手动替换就很麻烦
1 个赞
可以到问题专区提一个issue ,如果真的是有功能上的优化点后续应该可以得到优化
小龙虾爱大龙虾
(Minghao Ren)
9
必须按lightning设置的来识别空串和null值
碰到过这种问题,数量量小的话一般是在源头将空值先填充一个特殊字符串,导入后再处理
1 个赞
lightning 确实处理 ,“”, 和 , 的行为是一样的 
Prest13
(Ti D Ber 5 W4e F6 Oi)
15
想问问后续是否有解决这个场景下这个问题的计划,或者怎样提交需求。
感觉代码技术层面解决应该不会太复杂。
system
(system)
关闭
17
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。
