但有个问题是:
批量插入大量取值相邻的主键时,可能会产生较大的写热点问题。
所以我还是建议上系统监控图,定位瓶颈
但有个问题是:
批量插入大量取值相邻的主键时,可能会产生较大的写热点问题。
所以我还是建议上系统监控图,定位瓶颈
写入热点不会越写越慢,而是一开始就慢
非聚簇表,已经用SHARD_ROW_ID_BITS 打散了,应该不是这个问题
3台虚拟机,虚拟机的配置为8核cpu,16g内存,100磁盘
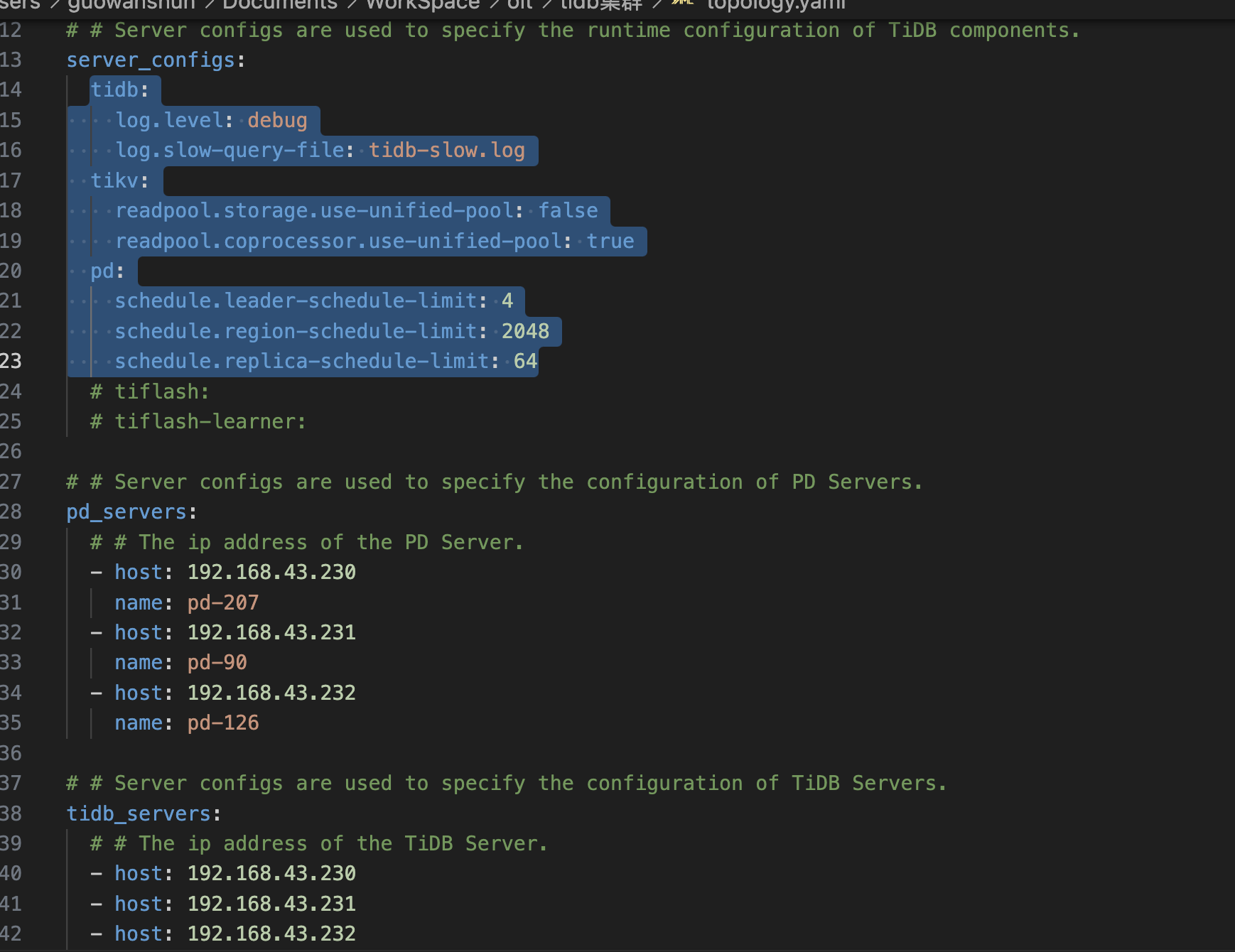
你这个topo配置是啥?
你看下表结构,要怎么改呢:
CREATE TABLE GponPmOnuLocalInfos (
node_id_str varchar(100) NOT NULL COMMENT ‘设备的hostname,为设备在网络中的唯一标识’,
subscription_id_str varchar(100) NOT NULL COMMENT ‘订阅名称’,
collection_id bigint(20) unsigned NOT NULL COMMENT ‘标识采样轮次’,
collection_start_time datetime DEFAULT NULL COMMENT ‘标识采样轮次开始时间’,
name varchar(100) DEFAULT NULL COMMENT ‘//ONU名称,格式:v_ani.f.s.p.onuid’,
channel varchar(100) DEFAULT NULL,
index int(10) unsigned DEFAULT NULL,
olt_rx_power int(10) DEFAULT NULL COMMENT ‘//OLT光模块接收到ONU的光功率,单位:0.01dBm’,
online_duration int(10) unsigned DEFAULT NULL COMMENT ‘//在线时长,单位:秒’,
last_down_time int(10) unsigned DEFAULT NULL COMMENT ‘//最后一次下线时间’,
last_down_cause int(10) unsigned DEFAULT NULL COMMENT ‘//最后一次下线原因’,
onu_status int(10) unsigned DEFAULT NULL COMMENT ‘//ONU状态,1-online,2-offline,255-invalid’,
PRIMARY KEY (node_id_str ,subscription_id_str ,collection_id )
) SHARD_ROW_ID_BITS = 4 PRE_SPLIT_REGIONS=3;
少了个1 不过我觉得应该是IO问题了,倒数第二列 wa ,已经到4了
dstat 1
vmstat 1
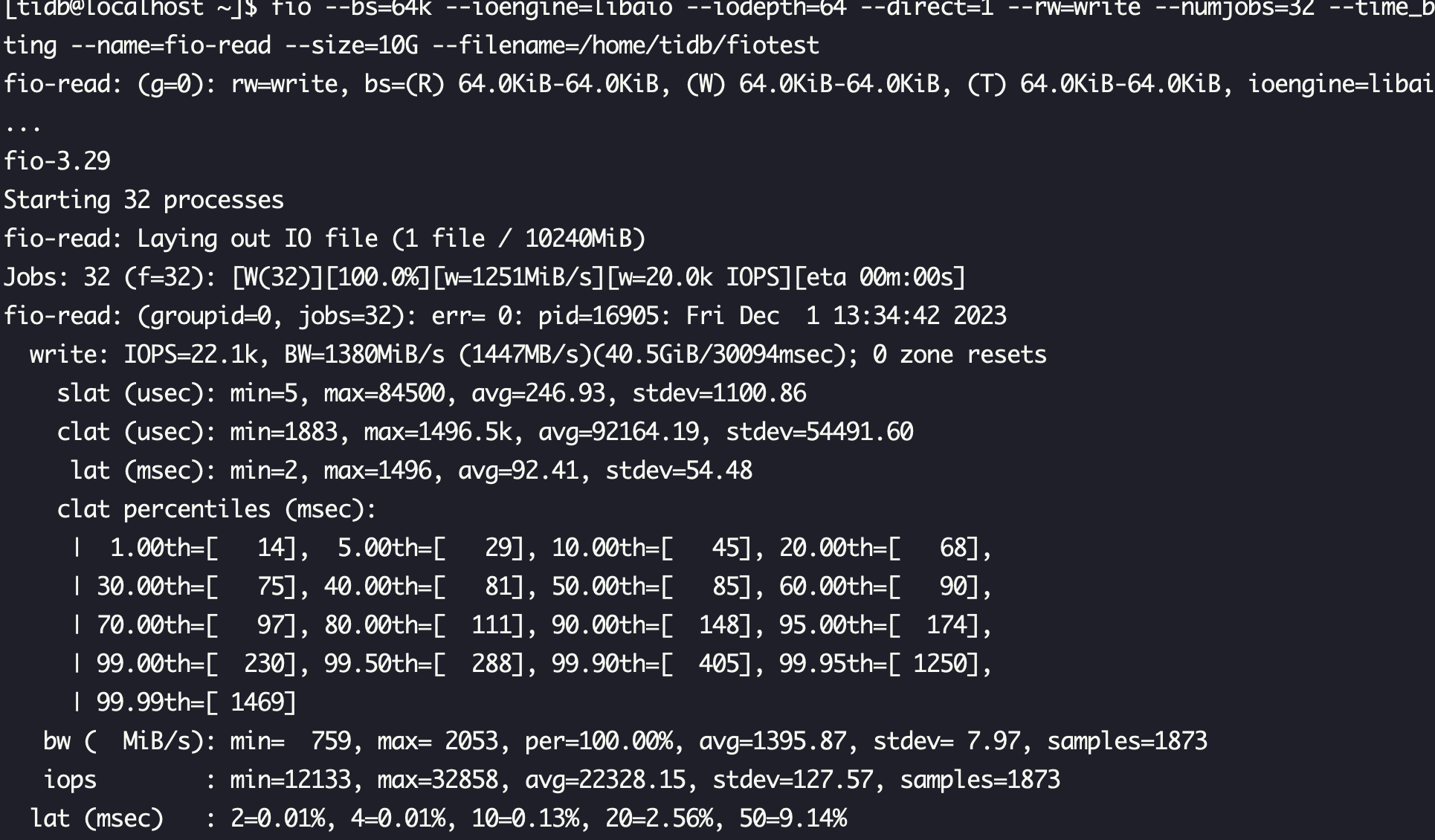
可以的话,用fio测测文件系统IO性能,4k和64k页
fio --bs=64k --ioengine=libaio --iodepth=64 --direct=1 --rw=write --numjobs=32 --time_based --runtime=30 --randrepeat=0 --group_reporting --name=fio-read --size=10G --filename=/data/fiotest
#自己改下filename路径
fio --bs=4k --ioengine=libaio --iodepth=64 --direct=1 --rw=write --numjobs=32 --time_based --runtime=30 --randrepeat=0 --group_reporting --name=fio-read --size=10G --filename=/data/fiotest
KV 节点的内存使用率呢?
你这个是nvme吧,性能很好啊
你截一段导入数据期间,tikv.log 、pd.log和tidb.log
有微信群吗,这样沟通的效率点。这个我们马上要上线的项目
测了多久性能下降的,大概写了多少数据。隔壁也有写入性能下降问题 TIDB v7.1.2 在全量灌入数据阶段每2个小时出现一次写陡降到0 - ![]() TiDB 技术问题 - TiDB 的问答社区 (asktug.com)
TiDB 技术问题 - TiDB 的问答社区 (asktug.com)
我这边时每次插入500条,每秒100次插入。发现性能一直是下降的,到了2小时左右,插入时间达到10min
get timestamp too slow
去grafana上截下图
PD----TIDB---- PD server TSO handle time
PD----TIDB---- Handle requests duration
下面那个
Got too many pings from the client
是已知BUG,不知道修没修