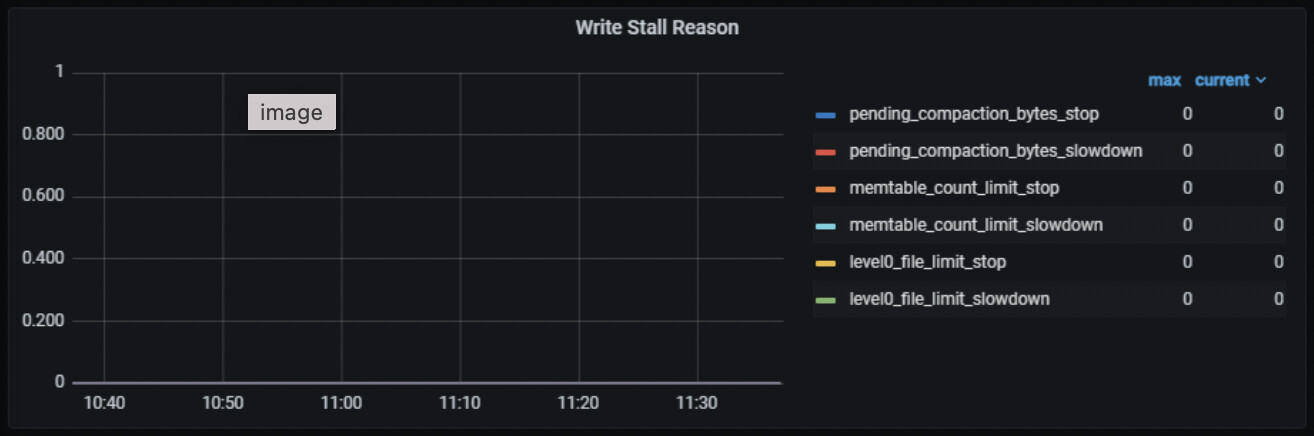
你选的这个时间范围对吗
咋没有值
对的,确实是没有值
对的,确实是没有值
那岂不是不是wait stall这个原因?
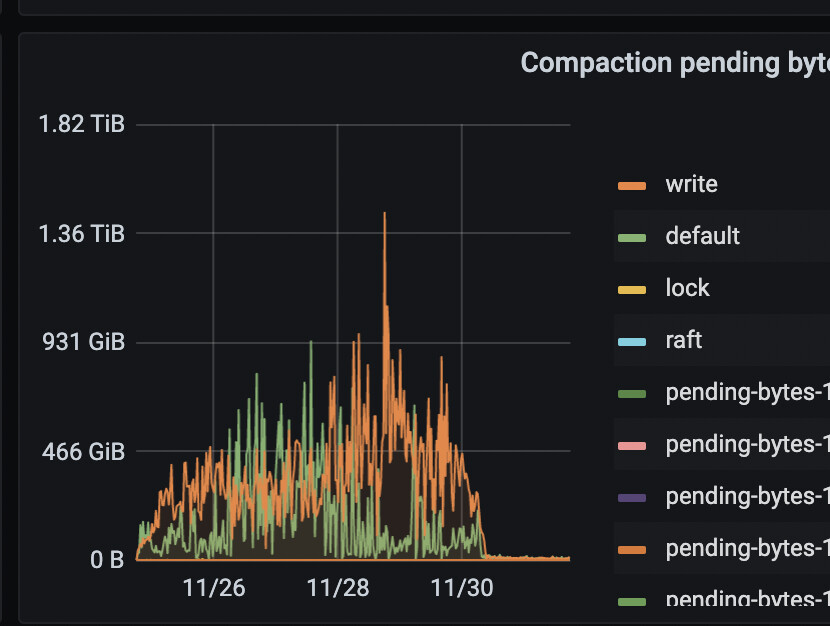
怀疑是这个监控有问题,但是看pending compaction的数据有些有些不符合预期,峰值都接近500GB了
1 个赞
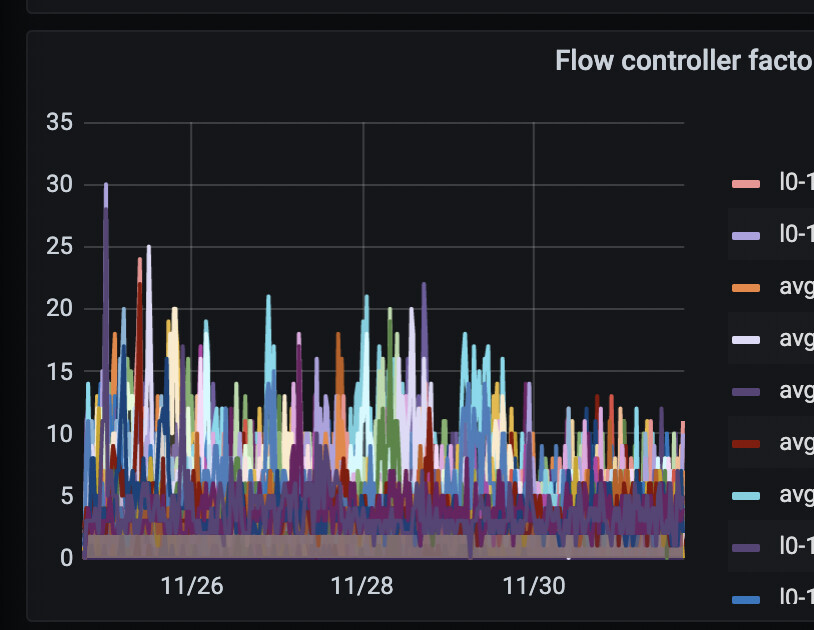
新版本用scheduler层控制流控了 ,看下tikv-detail → Flow Control。 官王没有这些指标说明
1 个赞
![]() 我第一个反应是节点重启了。
我第一个反应是节点重启了。
https://docs.pingcap.com/zh/tidb/stable/tikv-configuration-file#level0-file-num-compaction-trigger
level0-file-num-compaction-trigger
- 触发 compaction 的 L0 文件最大个数。
defaultcf默认值:4writecf默认值:4lockcf默认值:1- 最小值:
0
level0-file-num-compaction-trigger这个参数你现在设置的是多少? writecf,defaultcf这两个cf上数值是被调大过?
这个参数是默认值,没修改过,defaultcf=4, writecf=4
1 个赞
rocksdb层面的L0的SST个数,其实不调整的话也是完全OK的,这个我们在ROCKSDB上做过压测
说明你的磁盘好。我的峰值写入也只有300M/s。
如果 level0-file-num-compaction-trigger=4,基本pending compaction bytes都在2-4g左右。这会造成系统不定期出现一些秒级的写入慢查询。
我直接把这个参数,在所有cf上统一调到1了。现在pending compaction bytes基本都在1g左右。秒级写入慢查询,显著减少。当然我的慢查询本身设置的时间也比默认的300ms长一些,设置到了500ms。
我觉得不管这个参数是多少,原则就是一个,保证pending compaction bytes不能超过磁盘写入峰值太多。不然一compaction就容易出现扎堆的写入慢查询(慢查询界面一打开都是成片的秒级insert/commit)。
对于在线业务来说,这个参数确实不需要调整,我们Rocksdb引擎这个 level0-file-num-compaction-trigger =参数设置了5,但是如果是全量灌入数据期间确实需要关注一下
想知道2小时是哪些方面到了一个什么量级后就会触发流控
从监控上问题是出在COMPACTIOIN那里