【 TiDB 使用环境】测试
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
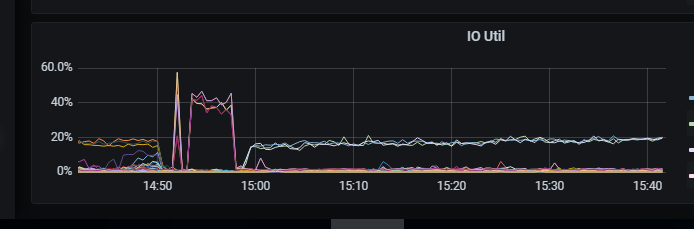
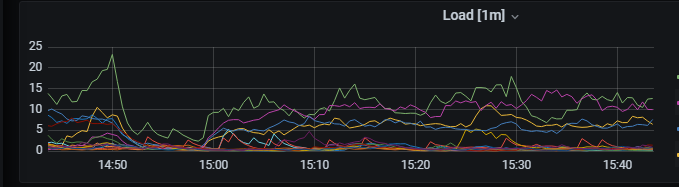
【附件:截图/日志/监控】
[2023/11/23 10:59:05.172 +08:00] [ERROR] [tidb.go:708] [“execute statement failed”] [rows=“[”] [error=“Error 9005 (HY000): Region is unavailable”]
[2023/11/23 10:59:05.172 +08:00] [ERROR] [tidb.go:708] [“execute statement failed”] [rows=“[)]”] [stmt=“REPLACE INTO db.table VALUES()”] [error=“Error 9005 (HY000): Region is unavailable”]
我这个集群之久lighting写入,为啥还会出现这种情况?
有猫万事足
4
目前我也感觉困惑,我看你的语句是replace into,可能是逻辑导入+冲突覆盖的方式导入的?
可能是某个tikv太忙了,或者掉线了之类的问题吧。
lightning的配置和tikv的监控有吗?
有猫万事足
10
[tikv-importer]
# 导入模式配置,设为 tidb 即使用 Logical Import Mode
backend = “tidb”
# Logical Import Mode 插入重复数据时执行的操作。
# - replace:新数据替代已有数据
# - ignore:保留已有数据,忽略新数据
# - error:中止导入并报错
on-duplicate = “replace”
确实是逻辑导入+冲突覆盖。
我也用过这个组合,我的感觉是,如果replace into冲突的数据,如果其他列没有改动,其实是tidb的cpu消耗的比较厉害,io不会很厉害。io如果很厉害,说明大量id相同的数据,内容完全不同。
不会是你在做分片聚合,但是表的主键忘了改了,导致每个分片的上有大量id相同,但是内容不同的数据,在反复写?
这种就比较容易造成tikv挂掉。我用物理导入的时候甚至因为这种冲突,搞得最后表和索引数据都不一致了。 
算是一个思路,你查查看。
1 个赞
有猫万事足
11
如果是每天定时的lightning导入,哪还有一种可能,就是之前的导入文件,在某次导入没清理,还在,然后这次增量导入的时候又导入了一次,也会有大量id冲突。
有猫万事足
14
空集群的话,还是推荐物理模式导入。
我用物理模式导入过csv文件,sql文件不确定,但起码可以肯定不是必须sst文件才能使用物理模式导入。
如果是空集群需要快速导入的情况,我觉得值得尝试。
我这18T数据,我看官方文档写的是10T,我这就一个库
请详细说明一下,如何分批,库创建语句如何处理,表结构如何处理,数据SQL如何分,谢谢
h5n1
(H5n1)
18
导入的并发是多大 region_concurrncy,
region-concurrency = 56,第二次调整为42,第三次调整为32,第四次调整为24,第五次调整为14