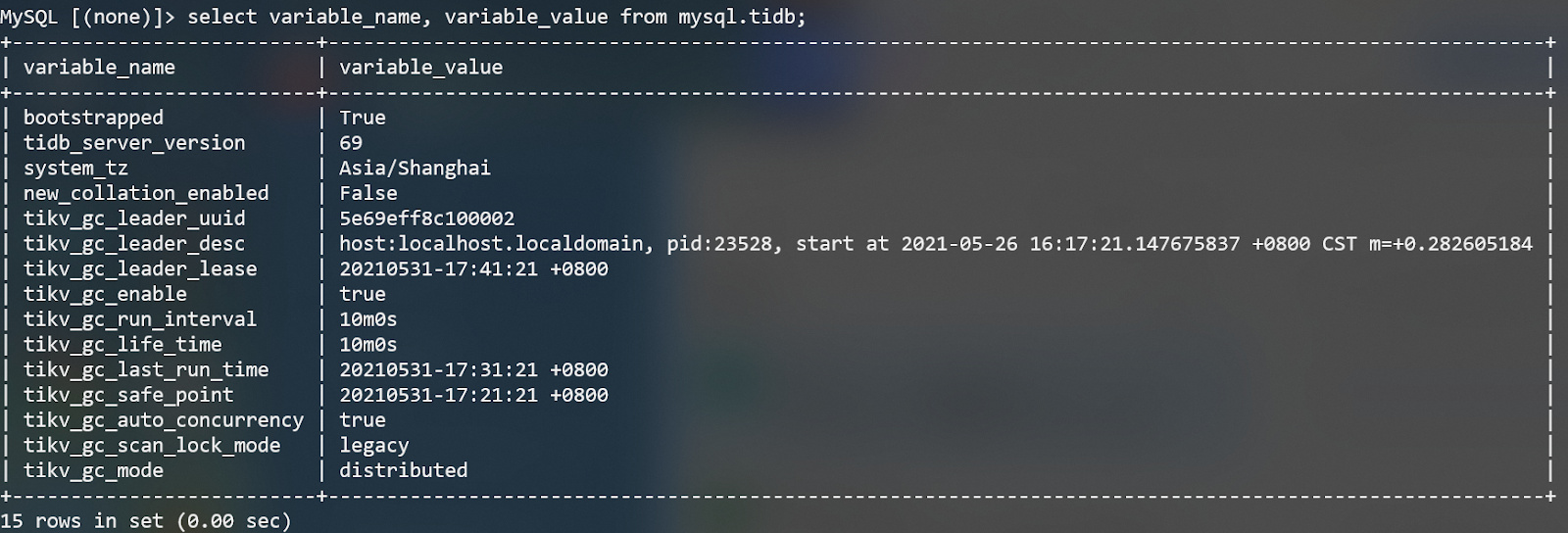
通过查看region
SHOW TABLE data REGIONS ;
数据region一共700多个
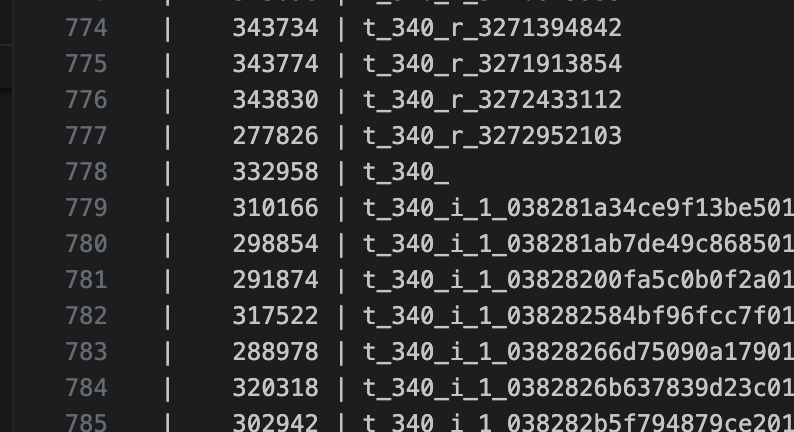
查询最小的id 2986870265
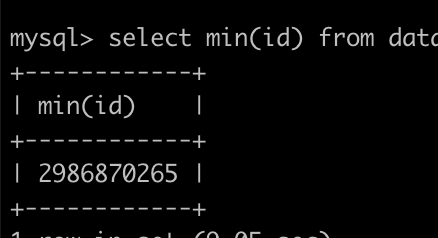
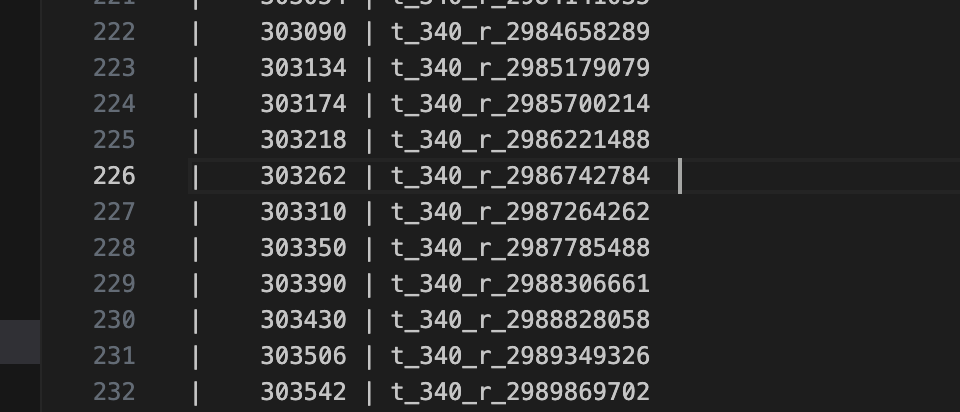
大概在这个位置,也就是说,最小值之前的很多个region并没有被gc掉,具体什么原因造成的不详
通过查看region
SHOW TABLE data REGIONS ;
数据region一共700多个
大概在这个位置,也就是说,最小值之前的很多个region并没有被gc掉,具体什么原因造成的不详
GC可以看一下系统表 mysql.tidb,看看GC有没有正常进行
以 tikv_gc 开头的变量都与 GC 相关,其中 tikv_gc_leader_uuid/tikv_gc_leader_desc/tikv_gc_leader_lease 用于记录 GC leader 的状态,tikv_gc_safe_point 和 tikv_gc_last_run_time 在每轮 GC 开始前会被自动更新,其他几个变量则是可配置的,详见 GC 配置 。
+--------------------------+----------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------+
| VARIABLE_NAME | VARIABLE_VALUE | COMMENT |
+--------------------------+----------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------+
| bootstrapped | True | Bootstrap flag. Do not delete. |
| tidb_server_version | 110 | Bootstrap version. Do not delete. |
| system_tz | UTC | TiDB Global System Timezone. |
| new_collation_enabled | True | If the new collations are enabled. Do not edit it. |
| tikv_gc_leader_uuid | 62e52230284001e | Current GC worker leader UUID. (DO NOT EDIT) |
| tikv_gc_leader_desc | host:localhost, pid:28846, start at 2023-11-03 09:34:32.127850756 +0000 UTC m=+0.121445556 | Host name and pid of current GC leader. (DO NOT EDIT) |
| tikv_gc_leader_lease | 20231120-12:55:32.141 +0000 | Current GC worker leader lease. (DO NOT EDIT) |
| tikv_gc_auto_concurrency | true | Let TiDB pick the concurrency automatically. If set false, tikv_gc_concurrency will be used |
| tikv_gc_enable | true | Current GC enable status |
| tikv_gc_run_interval | 10m0s | GC run interval, at least 10m, in Go format. |
| tikv_gc_life_time | 10m0s | All versions within life time will not be collected by GC, at least 10m, in Go format. |
| tikv_gc_last_run_time | 20231120-12:44:32.148 +0000 | The time when last GC starts. (DO NOT EDIT) |
| tikv_gc_safe_point | 20231120-12:34:32.148 +0000 | All versions after safe point can be accessed. (DO NOT EDIT) |
| tikv_gc_scan_lock_mode | legacy | Mode of scanning locks, "physical" or "legacy" |
| tikv_gc_mode | distributed | Mode of GC, "central" or "distributed" |
+--------------------------+----------------------------------------------------------------------------------------------------------------+---------------------------------------------------------------------------------------------+
15 rows in set (0.00 sec)
正常的
![]() 不会是时区的问题吧,你这个时间都是减8个小时的。
不会是时区的问题吧,你这个时间都是减8个小时的。
有证据了啊,执行计划就是证据啊🤔️,而且你测试max很快也是证据啊,还有啥不明白的
总结一下最终解决方法:
该问题的数据表,是从mysql binlog同步过来了,新建了一个同步任务,然后把历史数据导入到新表,业务查询切换到新表,删除掉老表
新表的执行计划
mysql> explain analyze select min(id) from data_new ;
+------------------------------+---------+---------+-----------+---------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------+-----------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+------------------------------+---------+---------+-----------+---------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------+-----------+------+
| StreamAgg_9 | 1.00 | 1 | root | | time:339µs, loops:2 | funcs:min(order.data_new.id)->Column#12 | 306 Bytes | N/A |
| └─Limit_13 | 1.00 | 1 | root | | time:335.8µs, loops:2 | offset:0, count:1 | N/A | N/A |
| └─TableReader_24 | 1.00 | 1 | root | | time:334.6µs, loops:1, cop_task: {num: 1, max: 332.8µs, proc_keys: 1, rpc_num: 1, rpc_time: 313µs, copr_cache_hit_ratio: 0.00, distsql_concurrency: 1} | data:Limit_23 | 439 Bytes | N/A |
| └─Limit_23 | 1.00 | 1 | cop[tikv] | | tikv_task:{time:0s, loops:1}, scan_detail: {total_process_keys: 1, total_process_keys_size: 27, total_keys: 2, get_snapshot_time: 7.61µs, rocksdb: {key_skipped_count: 1, block: {cache_hit_count: 10}}} | offset:0, count:1 | N/A | N/A |
| └─TableFullScan_22 | 1.00 | 1 | cop[tikv] | table:data_new | tikv_task:{time:0s, loops:1} | keep order:true | N/A | N/A |
+------------------------------+---------+---------+-----------+---------------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------+-----------+------+
感谢以下:
@小龙虾爱大龙虾 解惑算子问题
@Jellybean 解惑算子问题
@zhanggame1 直接点中问题背景,有pt-archiver purge归档任务
@h5n1 定位gc问题及解决方案
@xingzhenxiang 提供了脚本来代替pt-archiver工具,提升效率
![]() 所以最终定位为是GC导致的么?重建表之后可以观察一段时间。另外,别的表有没有这种情况?
所以最终定位为是GC导致的么?重建表之后可以观察一段时间。另外,别的表有没有这种情况?
是的,是gc没有删除掉之前pt-archiver删除的数据,其它表目前没有发现,不知道有没有办法可以巡检出来类似的情况
GET~谢谢~小表重建还好说,大表有点麻烦。确实要考虑怎么监控一下了。
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。