把mysql 3.5秒的实际执行计划粘下
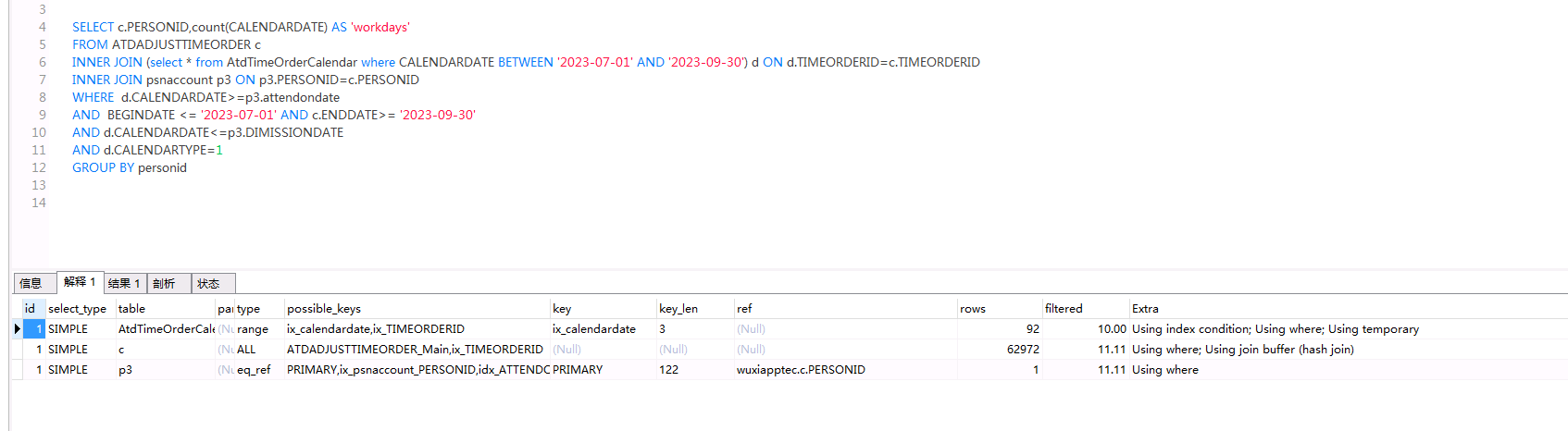
mysql是.18以上的版本吗?是的话直接用explain analyze输出下
8.0.25
→ Table scan on (actual time=0.004…0.613 rows=2657 loops=1)
→ Aggregate using temporary table (actual time=5420.348…5421.137 rows=2657 loops=1)
→ Nested loop inner join (cost=14866.65 rows=794) (actual time=2.700…5324.641 rows=95095 loops=1)
→ Inner hash join (c.TIMEORDERID = atdtimeordercalendar.TIMEORDERID) (cost=12402.83 rows=7150) (actual time=0.470…585.773 rows=4194048 loops=1)
→ Filter: ((c.begindate <= DATE’2023-07-01’) and (c.enddate >= DATE’2023-09-30’)) (cost=713.35 rows=6995) (actual time=0.075…67.627 rows=65532 loops=1)
→ Table scan on c (cost=713.35 rows=62972) (actual time=0.073…50.513 rows=65694 loops=1)
→ Hash
→ Filter: (atdtimeordercalendar.CALENDARTYPE = 1) (cost=103.66 rows=9) (actual time=0.325…0.357 rows=64 loops=1)
→ Index range scan on AtdTimeOrderCalendar using ix_calendardate, with index condition: (atdtimeordercalendar.calendardate between ‘2023-07-01’ and ‘2023-09-30’) (cost=103.66 rows=92) (actual time=0.320…0.345 rows=92 loops=1)
→ Filter: ((atdtimeordercalendar.calendardate >= cast(p3.ATTENDONDATE as date)) and (atdtimeordercalendar.calendardate <= cast(p3.DIMISSIONDATE as date))) (cost=0.03 rows=0) (actual time=0.001…0.001 rows=0 loops=4194048)
→ Single-row index lookup on p3 using PRIMARY (PERSONID=c.PERSONID) (cost=0.03 rows=1) (actual time=0.000…0.000 rows=1 loops=4194048)

select count(*) from ATDADJUSTTIMEORDER c
INNER JOIN psnaccount p3 ON p3.PERSONID=c.PERSONID
where c.BEGINDATE <= ‘2023-07-01’ AND c.ENDDATE>= ‘2023-09-30’;
两边都执行下
两边数据量一样,65532
执行时间也是一样的吗?
都非常快
select count(*) from ATDADJUSTTIMEORDER c
INNER JOIN (select TIMEORDERID,CALENDARTYPE from AtdTimeOrderCalendar where CALENDARDATE BETWEEN ‘2023-07-01’ AND ‘2023-09-30’) d ON d.TIMEORDERID=c.TIMEORDERID
INNER JOIN psnaccount p3 ON p3.PERSONID=c.PERSONID
where c.BEGINDATE <= ‘2023-07-01’ AND c.ENDDATE>= ‘2023-09-30’ and d.CALENDARTYPE=1;
分析一下p3表的索引,看看有没有优化的可能
analyze table psnaccount;
报
commit TS must be greater or equal to min commit TS: commit ts: 445060974279131170, min commit ts: 445060974279131171
会是什么原因啊
有个ninedata工具,可以智能优化sql,你可以用该工具优化后放到tidb执行试试
看tidb和mysql的执行计划一样,tidb主要慢在indexJoin去p3表获取记录,但是这里和mysql行为一样,tidb却很慢,这块应该主要是c.persionid太不连续导致,在lsmtree和btree的等值查询硬碰硬情况下lsmtree差的还是挺多的,尽管tidb已经在内部做了很多优化(比如尽量将key作为有序请求,get请求数据转为next)但是c.persionid过于离散会导致大量的逻辑block读。另外也没想到mysql对400多万数据主键关联索引查找仅需5秒就能搞定,我估计索引都在内存中吧。 tidb索引IndexJoin的一些行为在这个贴子里有较为详细的探讨,希望有所帮助:tidb index join 强行指定连接顺序后执行时间变化的问题
@小龙虾爱大龙虾 ,虾总在一开始就指出了你这并非最优执行计划,并且给出了最佳的连接顺序leading(c,p3,atdtimeordercalender),虽然走了tiflash,即使不走tiflash也不会慢,这个优化是可取的。
另外如果 atdtimeordercalendar的 KEY ix_TIMEORDERID (TIMEORDERID ) 需改为 KEY ix_TIMEORDERID (TIMEORDERID ,calendardate),那MySQL可能会更快很多,但TiDB无法加速。这是因为MySQL的a join b on a.col1=b.col1 and a.col2 < b.col2 index on b(col1,col2) 可以左表一条一条查询记录,不管等值条件还是范围条件都可以下压到右表进行过滤。但TiDB需要一批一批查询左表记录,只能下压等值条件到右表过滤,对于范围条件的只能拿到计算层过滤。
2 个赞
感谢啊,说的很专业。
c表也就几万条数据,不会存在.c.personid过于离散导致 大量的逻辑block读吧
因为c和d表关联,存在多对多情况,导致结果集放大了很多结果为4194048,然后在和p3关联,导致大量的p3主键索引读。因为三张表关联最终结果记录不多,但是c,d先关联产生的中间结果很多,说明关联顺序存在问题,楼上那位虾总也是看到这里所以在表连接顺序上帮你调整优化。
但是我猜想他还想通过将数据类型转换成一致的将非等值连接条件下压到存储层过滤,但是这个对于左边通过batch获取记录的情况是无法将非等值条件下压到右侧的,这个行为和mysql的bka(batched key accessed)以及ob的use_batch行为一样。只不过后两者也支持非batch方式,支持非batch主要是他们都是存算一体的,这种实现很多场景下效率并不低。
嗯,分析的很专业
这个问题大家有没有碰到过啊
LEADING(c,p3,atdtimeordercalendar@sel_2)
这里的@sel_2出现在最后果是什么意思啊
是不是时间没同步